This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
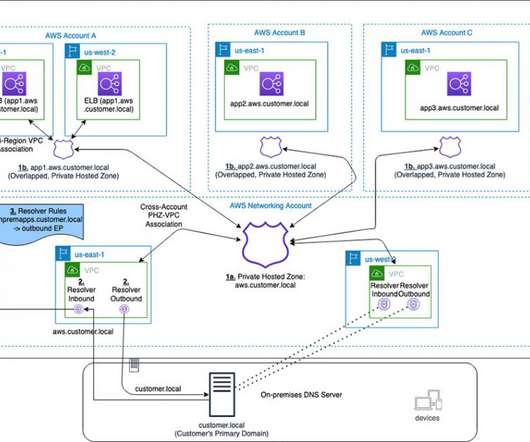
This post was co-written by Anandprasanna Gaitonde, AWS Solutions Architect and John Bickle, Senior Technical Account Manager, AWS Enterprise Support. Your business units can use flexibility and autonomy to manage the hosted zones for their applications and support multi-region application environments for disaster recovery (DR) purposes.
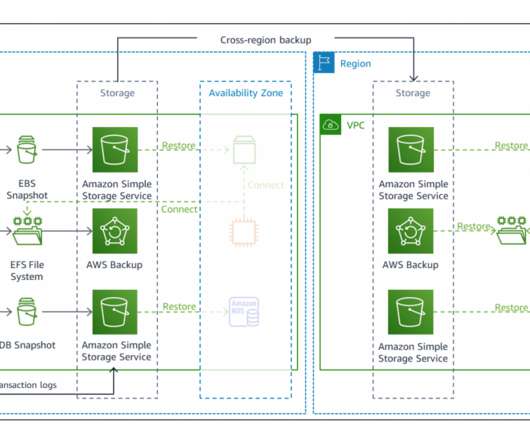
By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions. Every AWS Region consists of multiple Availability Zones (AZs).
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. The AWS Identity and Access Management (IAM) data plane is highly available in each Region, so you can authorize the creation of new resources as long as you’ve already defined the roles.
Our business needs in this scenario required us to build highavailability to prevent 30 minutes of continuous downtime (RTO) and prevent persistent user data loss (that is, a few minutes RPO). Manage service limits with Service Quota and adopt Multi-account strategy. Exponential backoff. Related information.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content