This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy. Because of this, you should develop an organizational multi-Region failover strategy that provides the necessary coordination and consistency to make your approach successful.
Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability. These examples demonstrate the importance of disaster recovery planning, particularly the use of cloud solutions, and geographically diverse systems to mitigate the impact of natural disasters.
These figures highlight the escalating financial risks associated with system outages, underscoring the importance of robust disaster recovery solutions like disaster recovery as a service (DRaaS) to mitigate potential losses. DRaaS helps mitigate this risk by ensuring data availability and regulatory compliance.
Cyber resilience addresses this issue by looking past prevention to consistently ensure the integrity of your critical data to mitigate risk. Cyber resilience is the ability to prepare for, respond to, and recover from a cyberattack once it occurs. Take the Zerto Cyber Resilience Assessment today to find out where you stand.
Guided by a live instructor, you’ll get access to a preconfigured Kubernetes cluster and explore key features such as effortless volume provisioning, overcoming CSI limitations, mitigating “noisy neighbor” issues, and automated capacity management.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. Being prepared will mitigate the impact on your business and reduce downtime.
Companies with high availability and uptime requirements can mitigate the added cost of Oracle RAC by deploying Oracle Single Instances that uses InfoScale Enterprise with Fast Failover.
Mitigate Security Risks with a Connected-Cloud Architecture. With a connected cloud architecture, businesses can mitigate security risks for IP and chip design data. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source.
Mitigating these unplanned disruptions requires a combination of careful planning, proactive monitoring, and a quick response to issues as they arise. The Zerto for Kubernetes Failover Test workflow can help users test the failover operations to multiple target sites.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. When you are structuring your DR plan, consider creating isolated networks specifically for failover testing. This includes updating the escalation plan and contact lists.
All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. Before failover, the infrastructure must scale up to meet production needs. Conclusion.
Private, public, and hybrid cloud offerings offer several advantages including on-premise protection, failover options, flexible workloads, and storage capacity to safeguard your critical data, applications, and IT assets when a crisis hits. The right technologies and resources can help you achieve this.
Ensure that the provider adheres to industry best practices for data protection and has robust security measures in place to mitigate the risk of data breaches or unauthorized access. Zerto runs failover, dev , and other QA tests at any time without production impact, ensuring aggressive SLAs are met. SOC 2, HIPAA, GDPR).
Mitigating Ransomware and Facilitating Data Recovery. a manager of IT infrastructure and resiliency at Asian Paints, a consumer goods company, Zerto is essential for replication of virtual appliances, failover automation, and failback processes at their DR site. It makes me look like a wizard at my desk,” they added.
Mitigating this factor will yield dividends for any organization seeking to reduce Risk. Many data centers incorporate High Availability – redundancy, hardening, segregated graceful failover – and assume that because “It Can Never Fail” there is no need for Disaster Recovery or Business Continuity.
To help mitigate against ransomware attacks, organizations need to not only carefully identify which applications should be refactored but consider the integration of data protection solutions early on. The Zerto for Kubernetes failover test workflow can help check that box. Disaster Recovery & Data Protection All-In-One.
With Zerto, state, local, and education entities can easily create and manage recovery plans, perform non-disruptive testing, and streamline the failover/failback processes. This simplification helps organizations achieve lower Recovery Time Objectives (RTOs) and minimizes the impact of downtime during disaster scenarios.
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. DR also mitigates the impact of disaster events and improves resiliency, which keeps Service Level Agreements high with minimum impact on business continuity.
After thorough testing of the failover and failback process, aligned with its clients’ other infrastructure components, DXC Technology decided to put the Portworx DR solution into production. Every six months, Wolthuizen and team rehearse the failover process to check readiness.
Cyber recovery also emphasizes threat mitigation during recovery, while DR focuses on system functionality. DR solutions integrate system restoration, failover procedures, and network rebuilding, making them crucial for organizations that require business continuity after major disruptions.
Develop a comprehensive migration plan that includes timelines, dependencies, and risk mitigation strategies. Automated failover and failback: Zerto automates the failover and failback process, allowing you to migrate workloads to the cloud with minimal manual intervention.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Infrascale built the first data protection cloud to automatically failover and recover applications, data, site s , and systems at the push of a button.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Infrascale built the first data protection cloud to automatically failover and recover applications, data, site s , and systems at the push of a button.
Quickly mitigate any planned or unplanned disruption and get the fast, flexible recovery your organization needs for 24/7 business continuity. Ease of deployment and operation The simple point-and-click provisioning provides a straightforward way to deploy a DR solution.
The Australian Signals Directorate (ASD) has developed a set of prioritized mitigation strategies known as the Essential Eight to safeguard internet-connected information technology networks. These strategies, outlined by the ASD, form a comprehensive framework to mitigate cybersecurity incidents effectively.
It’s eminently important for them to have a scenario where they can test failover actively without disrupting these services. . The department is a 24×7 shop because their customers—especially the police and fire departments—are actively working throughout the day and night.
” The BCP is a master document that details your organization’s entire prevention, mitigation, response, and recovery protocols for all kinds of threats and disasters. RTOs and RPOs guide the rest of the DR planning process as well as the choice of recovery technologies, failover options, and data backup platforms.
When using an off-site secondary server, your RTO will be restricted to the amount of time it takes to failover from one server to the other. Consolidating your disconnected systems is essential to mitigate this risk and streamline the recovery process. . Your RPO will be established by how often you replicate your data.
Every organization faces unique risks, and evaluating your risks is an important part of determining a disaster recovery testing template for your organization that includes the frequency that DR testing should be performed to help mitigate those risks. Setting Up Your Disaster Recovery Testing Template: Full vs. Partial.
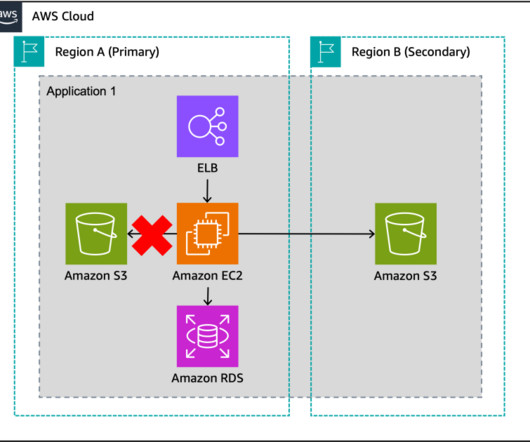
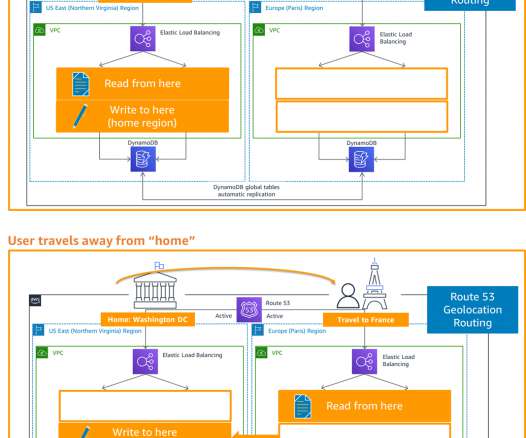
Consider using a write partitioned pattern to mitigate this. With a multi-Region active/active strategy, if your workload cannot operate in a Region, failover will route traffic away from the impacted Region to healthy Region(s). Alternatively, you can use AWS Global Accelerator for routing and failover. It does not rely on DNS.
Pure Storage vSphere Client Plugin: Pure Storage’s plugin for vSphere supports easy storage provisioning and management via Storage Policy Based Management (SPBM), provides orchestration for recovering VMs from SafeMode-protected snapshots, and can even manage replication of those snapshots to provide DR testing and orchestrated failover.
Mitigate Security Risks with a Connected-Cloud Architecture. With a connected cloud architecture, businesses can mitigate security risks for IP and chip design data. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source.
Part 1 : Configure ActiveDR and protect your DB volumes (why & how) Part 2 : Accessing the DB volumes at the DR site and opening the database Part 3 : Non-disruptive DR drills with some simple scripting Part 4 : Controlled and emergency failovers/failbacks In Part 1, we learned how to configure ActiveDR™.
Closely aligned with a data center strategy should be a holistic BCDR strategy that considers all types of risks (system failure, natural disaster, human error or cyberattack) and outage scenarios, and provides plans for mitigation with minimal or no impact to the business. Some of them use manual runbooks to perform failover/failbacks.
Availability requires evaluating your goals and conducting a risk assessment according to probability, impact, and mitigation cost (Figure 3). During failover, scale up resources and increase traffic to the Region. Now that you’ve set up a DR site in a second AWS Region, how do you route traffic to it if there’s a failover?
This redundancy provides a failover mechanism that allows you to switch to alternative systems or locations when primary ones are affected, ensuring that a copy of your data is always available. Regular backups also enable businesses to demonstrate compliance during audits, mitigating the risk of penalties and reputational damage.
Stability: Self-service upgrades need to be performed safely and with ample risk mitigation. We also require your input before failing over storage controllers just to keep you in sync with what’s going on (and to make sure you’re ready for the failover). This is your last chance to pause or back out of the upgrade process.
So, how might the new operational resilience methodologies and requirements help us to mitigate future harm? If we are able to take this one step further and conduct cross-market exercising with common third parties, we stand a far greater chance of mitigating harm to customers, firms, and the wider market in the event of a major crisis.
Students will learn how to attribute identified threats and risks to suspects, detect security threats, and design a security solution to mitigate risk. This training covers a range of topics, including recovery models, database backups, and failover clustering, among others. GO TO TRAINING.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Your DR plan may include any number of features, but some basics to keep in mind include: Know when to declare a disaster and initiate a failover.
Read on for more Osano Releases New ‘Advanced’ Features to Data Privacy Platform Osano’s new dashboards enable better visualization that enhances risk mitigation with more actionable information, including risk alerts, task prioritization, and progress tracking. NetApp’s E-Series is already SuperPOD-certified.
Too often, organizations invest significant hours and dollars in the effort to mitigate risk and build resilience, only to find the task is as daunting and impossible as pushing a boulder up a hill. Trying to figure out how to federate out the details to existing programs and create a holistic perspective from them.
It is well-known now that a recovery time objective (RTO) and recovery point objective (RPO) are important in mitigating the impact of a disaster. A ransomware attack is a disaster-level event and RTO and RPO are as important for ransomware as any other recovery event, but both must be effective to mitigate the costs.
One way to help mitigate this uncertainty is to build a lasting business continuity program. One way to help mitigate this uncertainty is to build a lasting business continuity program. Request a demo at [link] today! But how exactly do we do this? Request a demo at [link] today! But how exactly do we do this?
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content