

Minimizing Dependencies in a Disaster Recovery Plan
AWS Disaster Recovery
JANUARY 25, 2022
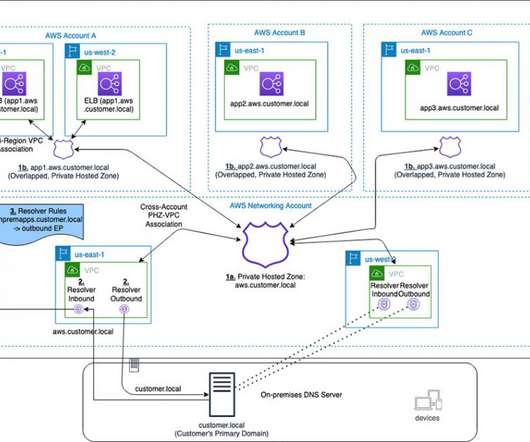
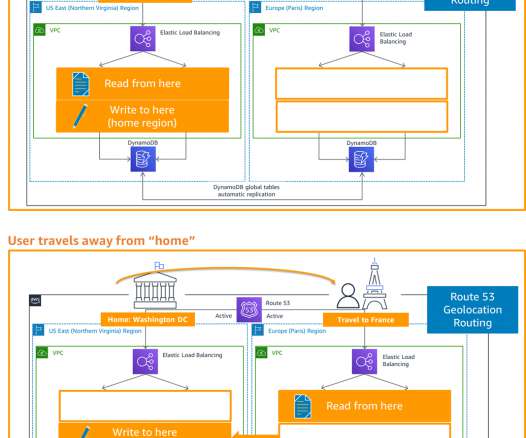
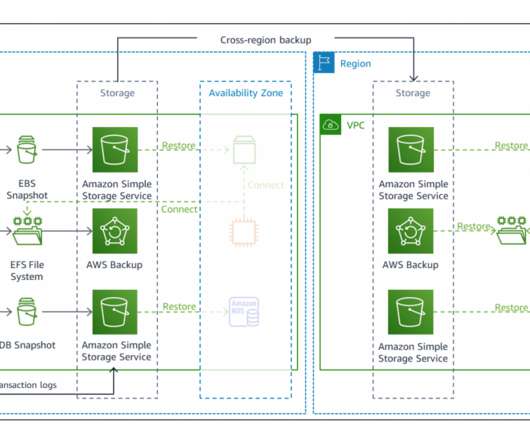
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. What if the very tools that we rely on for failover are themselves impacted by a DR event? Failover plan dependencies and considerations. What are the dependencies that we’ve baked into this failover plan?







Let's personalize your content