This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s dive in and ensure your DR environment is as resilient and reliable as it needs to be. Invest in Reliability : Opt for compute resources that offer highavailability and redundancy to minimize the risk of downtime during a disaster.
In this feature, SIOS Technology ‘s Todd Doane offers five strategies for achieving application highavailability. To address these concerns, implementing robust highavailability (HA) and disaster recovery (DR) strategies is essential.
Register for a session today Optimize Your Databases on Kubernetes The latest version of Portworx Data Services includes options for more streamlined database management and data resiliency. This includes SIEM, SOAR, and XDR integrations with security leaders like Cisco, Microsoft, LogRhythm, and others.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of highavailability (HA) and disaster recovery (DR) is paramount. Here, we delve into HA and DR, the dynamic duo of application resilience. What Is HighAvailability?
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
On-premises and cloud platforms differ in resiliency, storage efficiency, and APIs. This creates a divide between on-premises and cloud capabilities: Resiliency and efficiency. Pure Cloud Block Store bridges this divide in a few ways: It enhances the storage resiliency of the cloud.
Warm standby Implementing the multi-site active/passive strategy By replicating across multiple Availability Zones in same Region, your workloads become resilient to the failure of an entire data center. You would just need to create the records and specify failover for the routing policy.
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. What if the very tools that we rely on for failover are themselves impacted by a DR event? Failover plan dependencies and considerations. What are the dependencies that we’ve baked into this failover plan?
Site reliability engineering (SRE) and disaster recovery (DR) are two important activities that ensure the availability and resilience of an organization’s application infrastructure. In fact, SREs need to integrate DR solutions as part of their systems to ensure resilience.
The plan typically includes regular backups both on-site and off-site, redundant hardware for highavailability (HA), and failover systems. HA is a good option for availability and a recovery solution in case of natural disasters, but it does not fit the bill when it comes to ransomware events and related incidents.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Recalibrate your resilience architecture.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor also provides end-to-end data protection capabilities that include highavailability, endpoint protection , and workload migration.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor also provides end-to-end data protection capabilities that include highavailability, endpoint protection , and workload migration. Recovery Point.
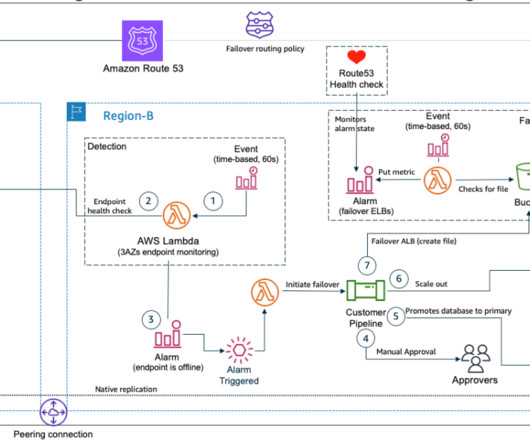
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. This makes your infrastructure more resilient and highly available and allows business continuity with minimal impact on production workloads.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Increase resiliency. In the following sections, we show you the steps we took to improve system resiliency for our example company. Conclusion.
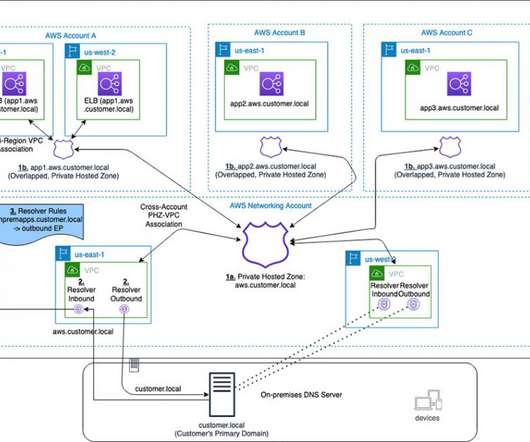
It utilizes PHZs with overlapping namespaces and cross-account multi-region VPC association for PHZs to create an efficient, scalable, and highly available architecture for DNS. For each Resolver endpoint, two or more IP addresses can be specified to map to different Availability Zones (AZs). Architecture Overview. Considerations.
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. High security, compartmentalized access, biometrics, the works. Uptime Institute Tier 4, everything down to the power into the racks was HighAvailability.
For software replication with Always On availability groups across regions in Microsoft SQL Server 2022, the following benefits can be realized: Volume snapshots and asynchronous replication can be used to ensure that, after failover, disaster recovery posture can be regained rapidly.
The Best Business Continuity Software Archer Platform: Archer Business Resiliency Description: Archer Business Resiliency enables users to identify and catalog their organization’s mission-critical processes and systems, as well as develop detailed business continuity and disaster recovery plans to protect their business from disruption.
It offers numerous high-availability solutions. When using FlashArray as the storage for any MySQL database, admins gain access to data services that can be used to protect or provide an additional layer of resilience for MySQL databases. Single-command failover. It can be virtualized. Multi-direction replication.
OK, how about some other areas where we can see differentiation from previous models, such as in data resiliency? What is also interesting is that Unity XT calls RAID “dynamic pools,” where PowerStore calls it “Dynamic Resiliency Engine.” Did Dell make some giant leaps there? You guessed it: Unity XT. I’m calling “B.S.”
Today’s top vendors primarily focus on centralized management, overall ransomware resilience and detection, support for public cloud backup, instant recovery of databases and virtual machines, and subscription licensing. Learn more and compare products with the Solutions Review Buyer’s Guide for Backup and Disaster Recovery.
Infrascale offers an enterprise-grade disaster recovery solution that provides failover to a second site with the flexibility to boot from the appliance or cloud. Data Protector offers high-performing backup and recovery across various data repositories, applications , and remote sites in physical and virtual environments.
In addition to storage, the provider’s solutions and products include cloud computing, compute , networking, content delivery, databases, analytics, application services, backup, compliance, data resiliency, data lifecycle management, hybrid cloud backup, and archive.
Organizations that implement a backup strategy with cyber resilience at the core can enable restores that are fast, predictable, reliable and cost-effective – at scale. It’s important to do full failover and recovery whenever possible so that you truly can understand the nuances you may face in a real situation.
It provides built-in automation, highavailability, rolling updates, role-based access control, and more—right out of the box. These include automated capacity management capabilities, data and application disaster recovery, application-aware highavailability, migrations, and backup and restore.
Later generations of Symmetrix were even bigger and supported more drives with more capacity, more data features, and better resiliency. . Other vendors brought storage products to market touting “enterprise class” with better features and resiliency. PowerStore utilizes ALUA-based failover, which could affect availability.
Despite the added complexity of running different workloads in different clouds, a multicloud model will enable companies to choose cloud offerings that are best suited to their individual application environments, availability needs, and business requirements. ” HighAvailability Protection for Storage Will Become Standard.
However, their effectiveness is partially dependent on the speed of their cyber resilience systems. Why RTO Matters for Cyber Resilience RTO is a critical metric in cyber resilience. Conclusion In the world of cyber resilience , speed is everything. The lower the RTO, the quicker a business can resume operations.
A good strategy for resilience will include operating with highavailability and planning for business continuity. AWS recommends a multi-AZ strategy for highavailability and a multi-Region strategy for disaster recovery. Failover Our customer decided to test the Pilot Light scenario.
.” For enterprise leaders, hybrid cloud combines the control of on-premises infrastructure, the security and compliance of private cloud, and the scalability and cost efficiency of public cloud, creating a flexible and resilient IT foundation. Key takeaway: Resiliency isnt a one-time initiative its an ongoing strategy.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content