This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. High security, compartmentalized access, biometrics, the works. Uptime Institute Tier 4, everything down to the power into the racks was HighAvailability.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of highavailability (HA) and disaster recovery (DR) is paramount. What Is HighAvailability? Failover is a part of the DR plan by providing both system and network-level redundancy.
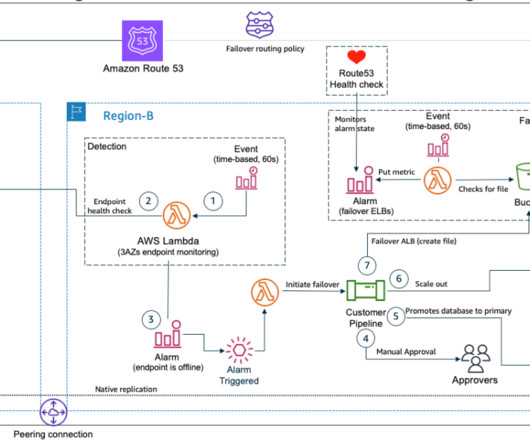
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Availability groups can be created to provide highavailability, read scale, or disaster recovery. .
Step 6: Test the Plan – Use scheduled power outages or major upgrades as a chance to test the plan. You can recover from a failure by using clustering software to failover application operation from a primary server node to a secondary server node over a LAN. RTO is the maximum tolerable length of time of an outage.
It offers numerous high-availability solutions. Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failover event. MySQL HighAvailability We know that a truly resilient business strategy means ensuring availability at multiple levels.
Minimum business continuity for failover. Our business needs in this scenario required us to build highavailability to prevent 30 minutes of continuous downtime (RTO) and prevent persistent user data loss (that is, a few minutes RPO). Standardize observability.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
It’s important to do full failover and recovery whenever possible so that you truly can understand the nuances you may face in a real situation. Securing your data is just the start: once you have a data protection strategy in place, it’s critical to consider recovery of that data should any disruption, outage, or cyber-attack occur.
Related reading: What is MySQL HighAvailability? NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases highavailability but also failover and fault tolerance in the event of a failure or outage. What Is a Non-relational Database? Built-in replication.
Despite the added complexity of running different workloads in different clouds, a multicloud model will enable companies to choose cloud offerings that are best suited to their individual application environments, availability needs, and business requirements. ” HighAvailability Protection for Storage Will Become Standard.
A good strategy for resilience will include operating with highavailability and planning for business continuity. AWS recommends a multi-AZ strategy for highavailability and a multi-Region strategy for disaster recovery. Failover Our customer decided to test the Pilot Light scenario.
This shift is driven by the operational and economic benefits of cloud solutions, yet it comes with its own set of challenges, particularly in the realm of highavailability (HA) environments. Understanding storage patterns and usage can help avoid unexpected slowdowns or outages.
Architect for highavailability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions. Deploy AI-driven monitoring and anomaly detection Use predictive analytics to detect and mitigate failures before they escalate into major outages.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content