This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In an era where data is the lifeblood of organizations, ensuring its resilience against unexpected outages is paramount. The recent CrowdStrike outage that impacted millions of Microsoft Windows devices worldwide has highlighted vulnerabilities within many companies’ disaster recovery frameworks.
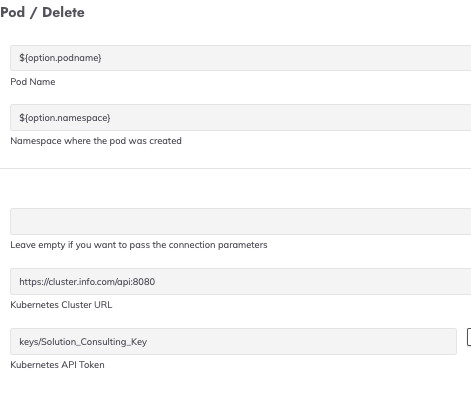
Event-driven automation is a powerful approach to managing enterprise IT environments, allowing systems to automatically react to enterprise events (Observability / Monitoring / Security / Social / Machine) and reducing or removing the need for manual intervention. Guard rails can be easily added to prevent accidental overscaling.
This cloud-based solution ensures data security, minimizes downtime, and enables rapid recovery, keeping your operations resilient against hurricanes, wildfires, and other unexpected events. In the event of a disaster, businesses can switch to their cloud-based VMs within minutes.
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
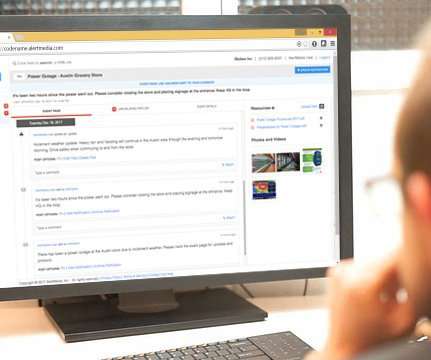
With the launch of Event Pages, organizations can instantly link their employees to critical information via a dedicated web page specific to an event. Individuals affected by the event can check the page as little or often as they feel necessary.
With the launch of Event Pages,  organizations can instantly link their employees to critical information via a dedicated web page specific to an event. Instead of sending individual status updates to every affected employee, the company now manages one Event Page in our mobile or web application â?? How An Event Page Works.
And ultimately, it’s not a matter of if you will have an outage, but of when. Before an outage… 1. During an outage… 3. Leverage our Change Events feature to view the most recent changes to your services (80% of incidents are the result of change events such as software deployments.) After an outage… 8.
These figures highlight the escalating financial risks associated with system outages, underscoring the importance of robust disaster recovery solutions like disaster recovery as a service (DRaaS) to mitigate potential losses. This setup minimizes the risk of prolonged downtime by providing a secure backup in the event of a regional issue.
However, IT outages, as the one caused by a Crowdstrike update on July 19 th 2024, are inevitable and can disrupt business operations, leading to significant financial losses and reputational damage. Accelerated incident response and resolution for IT disruption One of the most critical aspects of managing IT outages is the speed of response.
Use tools like SIEM (security information and event management) and SOAR (security orchestration, automation, and response) platforms. After a breach, outage, or data theft, the first priority is to get systems back online as quickly as possible. Access to data: Youre swimming in data from countless sources.
And ultimately, it’s not a matter of if you will have an outage, but of when. Before an outage… 1. During an outage… 3. Leverage our Change Events feature to view the most recent changes to your services (80% of incidents are the result of change events such as software deployments.) After an outage… 8.
When a critical event occurs, a Business Continuity Plan (BCP) documents the procedures and resources each department within an organization will use to keep the business impact to a minimum. Utility outages. When a critical event occurs, the responsibility of response may land on anyone from a local facility manager to the CSO.
The pressure to control costs, coupled with the larger business impact of outages, makes balancing efficiency and resilience even more difficult. How much revenue is lost during each outage? Outages are also trust erosion events for your brand, so there are other intangibles to consider besides revenue.
It’s been interesting to see the accepting attitude of customers that a disruption as large scale as the CrowdStrike outage would occur; ire and blame seems to have only been aimed at individual firms when those organisations have failed to revert to manual or alternative processes and recover within similar time frames to their peers.
How to Set Up a Secure Isolated Recovery Environment (SIRE) by Pure Storage Blog If youve suffered a breach, outage, or attack, theres one thing you should have completed and ready to go: a secure isolated recovery environment (SIRE). Heres why you need a secure isolated recovery environment and how to set one up. Why Do You Need a SIRE?
This caused a major outage in many sectors, including transportation, and CrowdStrike customers scrambled to roll back their systems or implement a workaround to restore systems to working order. We cannot prevent 100% of outages, but collectively we can prevent most and mitigate the impact of those that occur.
There was clearly a big outage and I quickly checked our systems at PagerDuty. Major outages happen multiple times per year, so frequently that we have an internal dashboard (colloquially referred to as “the internets are broken”). His team had just started implementing AIOps when the outage hit.
There was clearly a big outage and I quickly checked our systems at PagerDuty. Major outages happen multiple times per year, so frequently that we have an internal dashboard (colloquially referred to as “the internets are broken”). His team had just started implementing AIOps when the outage hit.
How can leaders handle a surge of inquiries during an IT outage? Outages are inevitable, so the focus should be on how well the company manages them and communicates with both internal stakeholders and customers. Support is part of a company-wide function, and handling a surge of inquiries ties back to preparedness.
I think with cyber threats and power outages being the focus of the moment, occupying us business continuity folks, we have forgotten about a good old threat: the computer outage. The post An Old Threat Returns…Computer Outage appeared first on PlanB Consulting.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. There is an order of magnitude difference between the two.
For my current client, I first considered this system’s potential after a hypothetical hurricane or extreme weather event. While Aruba has not faced a severe hurricane in living memory, such a system could still be valuable after an event causing widespread damage.
This year we had three spine-tingling tales that covered everything from hardware failures and human errors to ominous outages, monstrous migrations, and a blindsiding bioterrorism attack! Among today’s threats, hardware failures and human error account for a major portion of downtime events.
Recent heavy rainfall in Rhode Island, Georgia, and Indiana caused deadly flash floods and thousands of power outages. Preparing and planning ahead of disasters help keep families safe during emergencies and long after an event has passed. Find information that can help medical providers with their emergency preparedness needs.
The National Institute of Standards and Technology (NIST) Cybersecurity Framework (CSF) encourages security and IT teams to work together to reduce the impact of attacks and even prevent outages and permanent data loss. NIST CSF 2.0—
Undoubtedly, VMware Explore stands out as one of my favorite events of the year. While basking in the lively atmosphere of the event, one dominant theme echoed throughout our booth discussions – ransomware. While basking in the lively atmosphere of the event, one dominant theme echoed throughout our booth discussions – ransomware.
In the event of a sudden and unexpected disruption, from a power outage or natural disaster to equipment failure or system crash, the consequences can be catastrophic. This underlines the compelling case for MSPs to offer clients a way to maintain business continuity if the worst should happen.
If your enterprise has a disaster recovery plan, you’re on the right track, but these plans don’t always go into the details of how your business will operate and regain access to your data during an outage.
Before a winter weather event. Following a winter weather event. Monitor the weather. Find a reliable source for severe weather information. Follow the National Weather Service (NWS) Weather Prediction Center ( WPC ) on Facebook or Twitter and your local NWS office. Tune in to local news often when winter weather is forecast.
For those in the manufacturing industry, critical events threaten financial loss due to unplanned downtime, reduced factory utilization rates, lost revenue, and even employees put at risk. With so much reliance on electricity and computers, one outage can wreak havoc on your processes. Manufacturing Industry-Specific Dangers.
A Q&A with Brian Toolan , Everbridge VP Global Public Safety Talk about the trend in heat events that are impacting state and local governments. With power outages, you now have people who are oxygen dependent, who don’t have access to their oxygen because the power’s been turned off.
From managing global outages to addressing complex digital operations, the PagerDuty Operations Cloud enabled organizations to respond faster, work smarter, and build operational resilience. These updates help teams prepare for future events by automating critical workflows and ensuring consistency.
A company that has suffered an outage or disruption for any reason, and which is in the process of recovering its systems and operations, is at a heightened level of vulnerability to every type of event. During an event, use of devices often diverges from the norm. Risk assessment. Remote work polices and oversight.
This information will be important after an event when determining if there is too much snow on the roof. Avoiding a power outage can save a day or two of business interruption. Select a heating system repair service before an unexpected outage or maintenance issue arises mid-season. Prevent plumbing from freezing.
This wasn’t just a blip; it was the largest outage in IT history. This catastrophic event is a prime example of a colossal failure in risk management at multiple levels and underscores the dangers of third-party contagion. Nonexistent : The manual fixes and lingering outages showed just how unprepared everyone was.
Aside from data backup and replication considerations, IT organizations and teams also need to design robust disaster recovery (DR) plans and test these DR plans frequently to ensure quick and effective recovery from planned and unplanned outageevents when they occur. The right technologies and resources can help you achieve this.
Cyber resilience refers to an organization’s capacity to sustain operations and continue delivering to customers during a critical cyber event, whether it’s an internal disruption or an external threat. Adaptability and agility are key components of cyber resilience, allowing businesses to respond effectively to such events.
Mitigating supply chain risk After widespread coverage, the CrowdStrike outage from 19 July 2024 hardly needs an introduction. The outage was caused by a bad security update rolled out by CrowdStrike. Without question, this is one of the most expensive IT outages to date, with significant global impact. million Windows devices.
Events like KubeCon highlight the need for ongoing learning, tooling, and collaboration to manage Kubernetes effectively. Whats often referred to as an incident can range from routine IT tasks (like increasing system capacity) to major outages. Treating all incidents the same way can lead to unnecessary complexity.
Using an automation orchestration tool to enable event-driven automation, organisations can empower on-call responders with immediate access to automated runbooks, personally crafted by subject matter experts. They can do this by having automation orchestration capability that is event-driven, where the event in question is the incident.
The world has become increasingly reliant on access to data and digital services, and prolonged outages may cost your organization lost business, impaired productivity and irreparable reputation damage. Even the largest public clouds experience outages as seen in recent news events. Your Data is Your Responsibility.
Effective business continuity is measured by an organization’s ability to continue operations and maintain solvency, regardless of critical events and the circumstances – both expected and unknown – that lead to them. Confluence is inevitable: Prepare for interconnected critical events. What does it take? CXOVoice.com, April 2019 5.
All this effort spent on sifting through noise, processing events, and gathering context results in a lot of wasted time. . That’s why we’ve launched Event Orchestration, which became generally available to our Event Intelligence and Digital Operations customers on Monday. . The first is noise reduction.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. DR Strategies. OpenSearch Service.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content