This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This cloud-based solution ensures data security, minimizes downtime, and enables rapid recovery, keeping your operations resilient against hurricanes, wildfires, and other unexpected events. Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability.
These figures highlight the escalating financial risks associated with system outages, underscoring the importance of robust disaster recovery solutions like disaster recovery as a service (DRaaS) to mitigate potential losses. DRaaS helps mitigate this risk by ensuring data availability and regulatory compliance.
And, in the wake of such events, historically, many organizations have uprooted their operations to other regions or countries where environmental threats are less likely to interrupt their business. This is why HA and DR are critical for failover and recovery processes to minimize downtime.
Be sure to tune in to our Pure//Launch event on demand. Pure1 AIOps never sleeps Upgrade and Save Upgrade to Evergreen//Forever non-disruptively to avoid end-of-life events and realize significant cost savings compared to purchasing new arrays with the ForeverNow program. Visit the Pure//Launch web page to get the inside scoop.
Ransomware resilience: Zerto allows you to detect malicious encryption events then quickly recover in minutes by rolling back to a granular point-in-time just seconds before an attack. Cyber resilience addresses this issue by looking past prevention to consistently ensure the integrity of your critical data to mitigate risk.
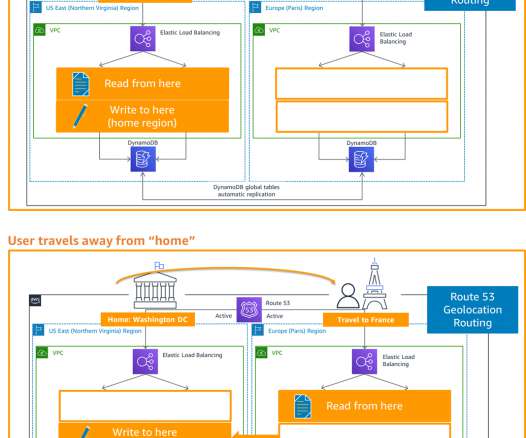
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. The main traffic flows through the primary and the secondary Region acts as a recovery Region in case of a disaster event.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. Being prepared will mitigate the impact on your business and reduce downtime.
This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Scope of impact for a disaster event.
Mitigating these unplanned disruptions requires a combination of careful planning, proactive monitoring, and a quick response to issues as they arise. In the event of a disaster, users can restore the application across multiple on-premises clusters or Kubernetes services running in the public cloud.
Aside from data backup and replication considerations, IT organizations and teams also need to design robust disaster recovery (DR) plans and test these DR plans frequently to ensure quick and effective recovery from planned and unplanned outage events when they occur. The right technologies and resources can help you achieve this.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. Step 1: Identify Critical Systems and Data To begin building your DR runbook, identify the critical systems and data that need to be protected in the event of a disaster.
Evaluate the Reliability and Availability of the DR Service The primary goal of DRaaS is to ensure uninterrupted access to critical systems and data in the event of a disaster. Zerto runs failover, dev , and other QA tests at any time without production impact, ensuring aggressive SLAs are met. SOC 2, HIPAA, GDPR).
Solutions like the Zerto Cyber Resilience Vault offer an added layer of protection, ensuring that even in the event of a severe breach, core assets remain untouched and recoverable. Cyber recovery also emphasizes threat mitigation during recovery, while DR focuses on system functionality.
In the event of an incident, organizations can easily recover their data from any point in time, reducing the potential for data loss and minimizing downtime. With Zerto, state, local, and education entities can easily create and manage recovery plans, perform non-disruptive testing, and streamline the failover/failback processes.
To help mitigate against ransomware attacks, organizations need to not only carefully identify which applications should be refactored but consider the integration of data protection solutions early on. The Zerto for Kubernetes failover test workflow can help check that box. Disaster Recovery & Data Protection All-In-One.
These events could be man-made (industrial sabotage, cyber-attacks, workplace violence) or natural disasters (pandemics, hurricanes, floods), etc. It is a strategy designed to help businesses continue operating with minimal disruption during a disruptive event. Business Continuity Plan vs. Disaster Recovery Plan.
The Australian Signals Directorate (ASD) has developed a set of prioritized mitigation strategies known as the Essential Eight to safeguard internet-connected information technology networks. These strategies, outlined by the ASD, form a comprehensive framework to mitigate cybersecurity incidents effectively.
A popular tourist destination, the city nearly bursts at the seams with an influx of revelers during major events such as Mardi Gras and Jazzfest. From the recreation parks all the way up to the public safety teams, especially our police and fire in the event of disasters, depend on us for technology services.” –Kim
This provided the bank with rapid synchronous data replication with a recovery point objective (RPO) of practically zero, meaning no data is lost in the event of an incident. Every six months, Wolthuizen and team rehearse the failover process to check readiness.
RPOs establish how much data an organization can stand to lose in the event of a disaster. When using an off-site secondary server, your RTO will be restricted to the amount of time it takes to failover from one server to the other. Reducing RPOs and RTOs is a goal of IT managers. Replication at a higher frequency means a lower RPO.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The company’s Disaster Recovery as a Service ( DRaaS ) solution, Recovery Cloud, provides recovery of business-critical applications to reduce data loss in the event of a disaster.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The company’s Disaster Recovery as a Service ( DRaaS ) solution, Recovery Cloud, provides recovery of business-critical applications to reduce data loss in the event of a disaster.
Develop a comprehensive migration plan that includes timelines, dependencies, and risk mitigation strategies. Automated failover and failback: Zerto automates the failover and failback process, allowing you to migrate workloads to the cloud with minimal manual intervention.
Pure Storage vSphere Client Plugin: Pure Storage’s plugin for vSphere supports easy storage provisioning and management via Storage Policy Based Management (SPBM), provides orchestration for recovering VMs from SafeMode-protected snapshots, and can even manage replication of those snapshots to provide DR testing and orchestrated failover.
Part 1 : Configure ActiveDR and protect your DB volumes (why & how) Part 2 : Accessing the DB volumes at the DR site and opening the database Part 3 : Non-disruptive DR drills with some simple scripting Part 4 : Controlled and emergency failovers/failbacks In Part 1, we learned how to configure ActiveDR™.
The crises and disruptions of the past few years have not been black swan events ? So, how might the new operational resilience methodologies and requirements help us to mitigate future harm? Dusting off the Documents. they were all imaginable and, to some degree, likely. by which point it’s too late for our strategy to be effective.
Like other DR strategies, this enables your workload to remain available despite disaster events such as natural disasters, technical failures, or human actions. Consider using a write partitioned pattern to mitigate this. Alternatively, you can use AWS Global Accelerator for routing and failover. It does not rely on DNS.
For a hyperconnected digital business, even a small disruptive event can ripple through the entire organization. Some of them use manual runbooks to perform failover/failbacks. Business continuity and disaster recovery (BCDR) plans need to keep pace with increasing business demands and growth in physical and compute infrastructures.
Data backup refers to the creation of copies of data to ensure it is not lost, corrupted, or destroyed in the event of a disaster or other unforeseen circumstance. Cyberattack risks mitigation Data breaches and other malicious activities can compromise sensitive business information, paralyze operations, and cause financial losses.
Minimum business continuity for failover. We used AWS Backup to simplify backup and cross-Region copying of Amazon EC2, Amazon Elastic Block Store (Amazon EBS) , and Amazon RDS to mitigate business continuity risks. Decoupling integrations using event-driven design patterns. Define application and infrastructure metrics.
Stability: Self-service upgrades need to be performed safely and with ample risk mitigation. The entire process is performed from within the Pure1 UI and is on rails, so the sequence of events will be consistent every time. We even provide two-factor authentication to validate a user’s identity before initiating any upgrades.
Surging ransomware threats elevate the importance of data privacy and protection through capabilities such as encryption and data immutability in object storage – capabilities that protect sensitive data and enable teams to get back to business fast in the event of such an attack.
This helps minimize downtime in the event of outages or cyberattacks. Read on for more Osano Releases New ‘Advanced’ Features to Data Privacy Platform Osano’s new dashboards enable better visualization that enhances risk mitigation with more actionable information, including risk alerts, task prioritization, and progress tracking.
Availability requires evaluating your goals and conducting a risk assessment according to probability, impact, and mitigation cost (Figure 3). During failover, scale up resources and increase traffic to the Region. Now that you’ve set up a DR site in a second AWS Region, how do you route traffic to it if there’s a failover?
Now, ransomware has elevated cyber-crime to events that paralyze the operations of one or more organizations for days or weeks. It is well-known now that a recovery time objective (RTO) and recovery point objective (RPO) are important in mitigating the impact of a disaster.
With a business continuity plan and disaster recovery solutions, however, businesses can minimize their risk of experiencing downtime and data loss due to a disaster or other crisis event. They ensure a firm can continue functioning without downtime, regardless of adverse circumstances or events. How Do They Work Together?
Those who are certified will be working, as a professional, with a business to prepare processes, policies and procedures to follow in the event of a disruption. Students will learn how to attribute identified threats and risks to suspects, detect security threats, and design a security solution to mitigate risk. GO TO TRAINING.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Get Your Info from the Source For large incidents and major outages, the events are often the main tech news story of the day. What can we bring from our experiences handling our own incidents?
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. Get the Guide What Is Disaster Recovery Planning?
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. What Is Disaster Recovery Planning?
Too often, organizations invest significant hours and dollars in the effort to mitigate risk and build resilience, only to find the task is as daunting and impossible as pushing a boulder up a hill. Trying to figure out how to federate out the details to existing programs and create a holistic perspective from them.
One way to help mitigate this uncertainty is to build a lasting business continuity program. LinkedIn: [link] Book Mathews as a speaker: [link] Jon Seals, producer Jon Seals is the editor in chief at Disaster Recovery Journal, the leading magazine/event in business continuity. Request a demo at [link] today!
One way to help mitigate this uncertainty is to build a lasting business continuity program. Connect with Shane Mathew LinkedIn - [link] Failover Plan Podcast - failoverpodcast.com. Jon Seals, producer Jon Seals is the editor in chief at Disaster Recovery Journal, the leading magazine/event in business continuity.
One way to help mitigate this uncertainty is to build a lasting business continuity program. Connect with Shane Mathew LinkedIn - [link] Failover Plan Podcast - failoverpodcast.com. Jon Seals, producer Jon Seals is the editor in chief at Disaster Recovery Journal, the leading magazine/event in business continuity.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content