This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this feature, SIOS Technology ‘s Todd Doane offers five strategies for achieving application highavailability. To address these concerns, implementing robust highavailability (HA) and disaster recovery (DR) strategies is essential. The company relied on securities trading applications based on Oracle Database.
Be sure to tune in to our Pure//Launch event on demand. This feature is available on the Asset Management, Appliance Genealogy, and Subscriptions pages in Pure1. Combined with automated operations for SQL Server availability groups to support highavailability and failover, you can experience higher uptime and greater data resilience.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of highavailability (HA) and disaster recovery (DR) is paramount. What Is HighAvailability? Failover is a part of the DR plan by providing both system and network-level redundancy.
So, given its importance, you want to make sure you have a solid solution for ensuring it’s highly available or protected in the event of a disaster. Most SAP HANA customers today are using SAP HANA system replication (HSR) to ensure the highavailability and disaster recovery systems remain in sync.
Active-active vs. Active-passive: Decoding High-availability Configurations for Massive Data Networks by Pure Storage Blog Configuring highavailability on massive data networks demands precision and understanding. Related reading: What Is Oracle HighAvailability? and What Is MySQL HighAvailability?
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
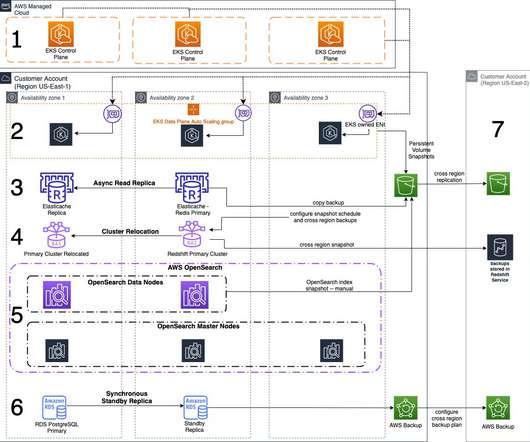
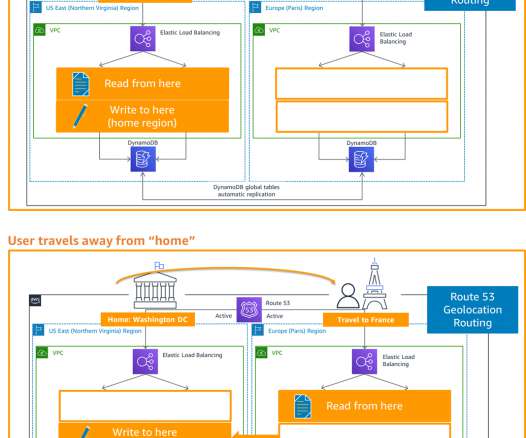
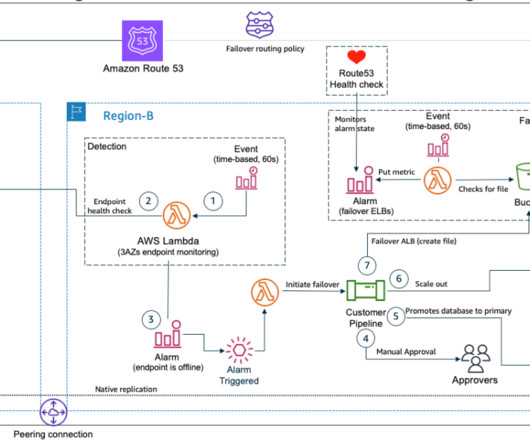
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. The main traffic flows through the primary and the secondary Region acts as a recovery Region in case of a disaster event.
Organizations need an easier, cost-effective solution that lets them still maintain business continuity in the event of any disaster. The plan typically includes regular backups both on-site and off-site, redundant hardware for highavailability (HA), and failover systems.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Static stability.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1 or later.
They continuously improve systems’ design and operation, and they work closely with development teams to ensure that systems are highly available, resilient, and prepared for planned and unplanned disruptions to applications. A robust DR strategy is critical to application availability and resilience. Zerto also automates DR processes.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor also provides end-to-end data protection capabilities that include highavailability, endpoint protection , and workload migration. Canada, and the Netherlands.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor also provides end-to-end data protection capabilities that include highavailability, endpoint protection , and workload migration. Canada, and the Netherlands.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Availability groups can be created to provide highavailability, read scale, or disaster recovery. .
No business continuity or disaster recovery plan can tackle every possible event or set of circumstances and, for that reason, both BC/DR should evolve continuously. You can recover from a failure by using clustering software to failover application operation from a primary server node to a secondary server node over a LAN.
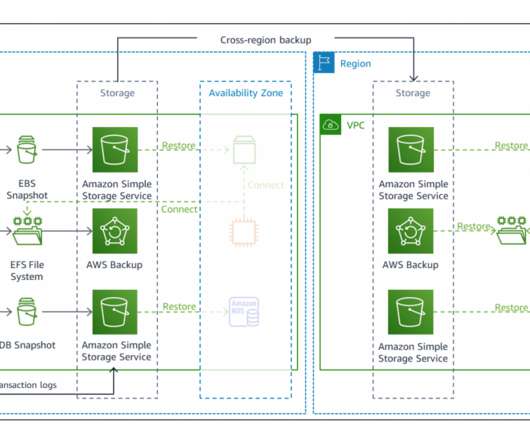
This will minimize maintenance and operational overhead, create fault-tolerant systems, ensure highavailability, and protect your data with robust backup/recovery processes. This is to ensure highavailability of the service and application. Amazon RDS PostgreSQL. Backing up data across Regions.
By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions. Every AWS Region consists of multiple Availability Zones (AZs).
It offers numerous high-availability solutions. Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failoverevent. However, there is no single high-availability solution that fits in all situations.
By maintaining a copy of important data in a secure off-site location, businesses can protect themselves from data loss events such as hardware failures, natural disasters, and cyberattacks. This strategy ensures that data is continuously mirrored, allowing for rapid failover in case of a server failure.
Like other DR strategies, this enables your workload to remain available despite disaster events such as natural disasters, technical failures, or human actions. Each Region hosts a highly available, multi- Availability Zone (AZ) workload stack. Alternatively, you can use AWS Global Accelerator for routing and failover.
Those who are certified will be working, as a professional, with a business to prepare processes, policies and procedures to follow in the event of a disruption. TITLE: SQL Server HighAvailability and Disaster Recovery (HA/DR). TITLE: Advanced SQL Server HighAvailability & Disaster Recovery. GO TO TRAINING.
Minimum business continuity for failover. Our business needs in this scenario required us to build highavailability to prevent 30 minutes of continuous downtime (RTO) and prevent persistent user data loss (that is, a few minutes RPO). Decoupling integrations using event-driven design patterns. Centralized logging.
Availability: Concerns to solve for highavailability (HA) and DR. Now let’s discuss how we can address these concerns in the AWS Cloud. First, the AWS Well-Architected Framework covers important architecture principles and related services that help you with availability and performance. Warm standby (Tier 3).
Data protection strategies are developing around two concepts: data availability and data management. Data availability ensures that users have access to the data they need to maintain day-to-day business operations at all times, even in the event that data is lost or damaged.
enables customers to deploy a multitarget highavailability environment in which HANA operates on a primary node and, in the event of a failure or disaster, can failover to a secondary and/or a tertiary target node located in a different cloud Availability Zone or on-premises disaster recovery location.
Surging ransomware threats elevate the importance of data privacy and protection through capabilities such as encryption and data immutability in object storage – capabilities that protect sensitive data and enable teams to get back to business fast in the event of such an attack.
True Enterprise High-availability (HA) By enterprise HA we mean that the storage system has been hardened to support automatic, rapid isolation and recovery from underlying hardware and software faults. In a typical HA configuration, each SSD is redundantly connected to at least two controllers in the event there is a problem.
Apache Kafka is an event-streaming platform that runs as a cluster of nodes called “brokers.” It provides built-in automation, highavailability, rolling updates, role-based access control, and more—right out of the box. This post is part 1 in a series on architecting Apache Kafka on Kubernetes with Portworx ® by Pure Storage ®.
Related reading: What is MySQL HighAvailability? NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases highavailability but also failover and fault tolerance in the event of a failure or outage. What Is a Non-relational Database? Built-in replication.
Despite the added complexity of running different workloads in different clouds, a multicloud model will enable companies to choose cloud offerings that are best suited to their individual application environments, availability needs, and business requirements. ” HighAvailability Protection for Storage Will Become Standard.
A good strategy for resilience will include operating with highavailability and planning for business continuity. AWS recommends a multi-AZ strategy for highavailability and a multi-Region strategy for disaster recovery. Failover Our customer decided to test the Pilot Light scenario.
Originally developed by LinkedIn and now an Apache Software Foundation project, Kafka is designed to handle high-throughput , fault-tolerant, and distributed event streaming. Beyond simplifying operations, KRaft treats metadata as an event stream, allowing cluster members to track their position using a single offset.
vSphere highavailability (HA) and disaster recovery (DR): VMware offers built-in highavailability and disaster recovery features, ensuring that critical workloads can quickly recover from failures with minimal downtime. Its flexible architecture allows for both on-premises and cloud integration.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content