This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This cloud-based solution ensures data security, minimizes downtime, and enables rapid recovery, keeping your operations resilient against hurricanes, wildfires, and other unexpected events. Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Why DRaaS Makes Financial Sense DRaaS provides cloud-based disaster recovery solutions, meaning that in the event of a disaster, your systems can be restored quickly, allowing your business to keep operating with minimal disruption. Look for providers that offer automated, regular testing capabilities that simulate failover scenarios.
Ransomware resilience: Zerto allows you to detect malicious encryption events then quickly recover in minutes by rolling back to a granular point-in-time just seconds before an attack. Most of our customers purchased Zerto for disaster recovery (90% of respondents) or ransomware recovery (41%).
Customers only pay for resources when needed, such as during a failover or DR testing. Automation and orchestration: Many cloud-based DR solutions offer automated failover and failback, reducing downtime and simplifying disaster recovery processes.
Be sure to tune in to our Pure//Launch event on demand. Pure1 AIOps never sleeps Upgrade and Save Upgrade to Evergreen//Forever non-disruptively to avoid end-of-life events and realize significant cost savings compared to purchasing new arrays with the ForeverNow program. Visit the Pure//Launch web page to get the inside scoop.
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. The main traffic flows through the primary and the secondary Region acts as a recovery Region in case of a disaster event.
Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. Zerto pulls a “gold copy” of the infected VM initially backed up before the event to a repository. Get Your Files Back!
Cloud recovery typically involves automated failover mechanisms, ensuring minimal impact on end users and business processes. They refer to data loss and recovery time for data and applications in the event of a disasterwhether on-premises or an outage in a region hosting cloud resources. Ensuring frequent backups with low RPOs.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. power outages, email outages, etc).
So, given its importance, you want to make sure you have a solid solution for ensuring it’s highly available or protected in the event of a disaster. It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. .
This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Scope of impact for a disaster event.
Application-consistent points in time will be indicated as a checkpoint in the Zerto journal of changes to ensure visibility when performing a move, failover, or failover test in Zerto. In the event of a crash recovery, the database will recover from a specific checkpoint and behave like it is recovering from a failure.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Static stability.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. Step 1: Identify Critical Systems and Data To begin building your DR runbook, identify the critical systems and data that need to be protected in the event of a disaster.
In the event of a disaster, users can restore the application across multiple on-premises clusters or Kubernetes services running in the public cloud. The Zerto for Kubernetes Failover Test workflow can help users test the failover operations to multiple target sites.
Evaluate the Reliability and Availability of the DR Service The primary goal of DRaaS is to ensure uninterrupted access to critical systems and data in the event of a disaster. Zerto runs failover, dev , and other QA tests at any time without production impact, ensuring aggressive SLAs are met. Non-disruptive testing.
Organizations need an easier, cost-effective solution that lets them still maintain business continuity in the event of any disaster. The plan typically includes regular backups both on-site and off-site, redundant hardware for high availability (HA), and failover systems.
We accomplish this by automating and orchestrating snapshots and replication within EBS to efficiently move data across regions and allow rapid failover between regions in a disaster event. As an agentless disaster recovery solution, Zerto stands out in delivering rapid failover and recovery at scale. .
Solutions like the Zerto Cyber Resilience Vault offer an added layer of protection, ensuring that even in the event of a severe breach, core assets remain untouched and recoverable. Backup refers to storing copies of data that can be used in the event of data loss (typically due to user error, hardware failure, or corruption).
Aside from data backup and replication considerations, IT organizations and teams also need to design robust disaster recovery (DR) plans and test these DR plans frequently to ensure quick and effective recovery from planned and unplanned outage events when they occur. The right technologies and resources can help you achieve this.
In the event of an outage due to a ransomware attack completely taking your primary site down, Zerto for Kubernetes helps users fight back by performing a failover live operation. The Zerto for Kubernetes failover test workflow can help check that box. Disaster Recovery & Data Protection All-In-One.
In the event of an incident, organizations can easily recover their data from any point in time, reducing the potential for data loss and minimizing downtime. With Zerto, state, local, and education entities can easily create and manage recovery plans, perform non-disruptive testing, and streamline the failover/failback processes.
“Zerto has been one of our most important technology partners for a decade now, and it’s extremely gratifying to be named its MSP of the Year for the third year running,” said Pete Abel, SVP and CMO, TierPoint.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1 or later.
To monitor the replication status of objects, Amazon S3 events and metrics will track replication and can send an alert if there’s an issue. Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Traditionally, each S3 bucket has its own single, Regional endpoint.
How can you be sure that your counter-parties will be there for you for the next business-interrupting event? Some had plans, some are improvising, and the Governors are dictating most of the responses anyway.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. DR Strategies.
With Zerto, SREs can replicate data in real-time, ensuring that the most recent version of data is always available in the event of a disaster. This eliminates the need for manual intervention and reduces the risk of human error when initiating a failover. Zerto also automates DR processes. Another important aspect of DR is testing.
The lab exercises allowed them to install Zerto, pair production and recovery sites, restore files and folders, perform test and live failovers, and restore VMs from long-term retention.
While the firm’s IT team was backing up these applications and database frequently, they could not recover operations quickly in the event of a failure or disaster. In the event of a failover, the software orchestrated the failover of application operation to the secondary node in the cluster.
No business continuity or disaster recovery plan can tackle every possible event or set of circumstances and, for that reason, both BC/DR should evolve continuously. You can recover from a failure by using clustering software to failover application operation from a primary server node to a secondary server node over a LAN.
Minimize Risk with Data That’s Always Available Keep your data available in the event of disasters or accidents, regardless of your required recovery point objectives (RPOs) and recovery time objectives (RTOs). Protect Your Data The post ZTNA vs. VPN appeared first on Pure Storage Blog.
Secure analysis: In the event of a cyberattack, the replicated data can be spun up as native EC2 instances within an isolated VPC. Automated failover: Automated failover capabilities of Pure Protect //DRaaS ensure a swift transition to the clean room environment, minimizing the window of exposure during a cyberattack.
By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions. Failover and cross-Region recovery with a multi-Region backup and restore strategy.
Real-time replication and automated failover/failback ensure rapid recovery of data and applications, minimizing downtime and business disruption. Recovery orchestration Solution: Zerto automates the orchestration of recovery processes, enabling seamless and coordinated failover and failback.
This provided the bank with rapid synchronous data replication with a recovery point objective (RPO) of practically zero, meaning no data is lost in the event of an incident. Every six months, Wolthuizen and team rehearse the failover process to check readiness.
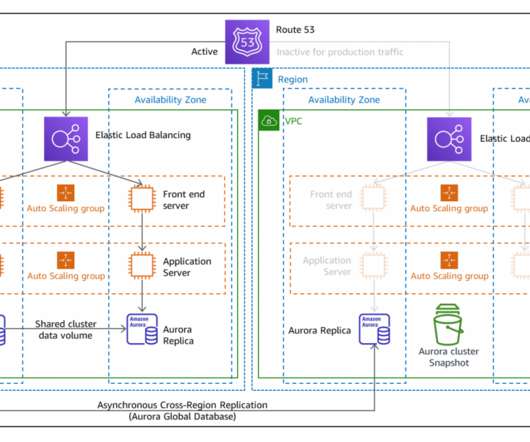
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
And he’s a big advocate for the act of pre-planning for these events. . With over 20 years of experience in Property Restoration, he assists customers as they struggle with property loss whether from fire loss, water damage, storm events, mold remediation, or any other property loss.
Automated failover and failback: Zerto automates the failover and failback process, allowing you to migrate workloads to the cloud with minimal manual intervention. In the event of a migration failure or rollback, Zerto provides seamless failback capabilities, ensuring minimal disruption to your operations.
James has experience providing crisis response support during real world events across multiple threat vectors including product recall, extortion events, workplace violence, cyber-attacks, natural disasters and corporate misconduct events.
The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests. In the event of a primary server failure, processes running the services are moved to the standby cluster.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content