This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. High security, compartmentalized access, biometrics, the works. Uptime Institute Tier 4, everything down to the power into the racks was HighAvailability.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of highavailability (HA) and disasterrecovery (DR) is paramount. What Is HighAvailability? Here, we delve into HA and DR, the dynamic duo of application resilience.
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. What does static stability mean with regard to a multi-Region disasterrecovery (DR) plan? Testing your disasterrecovery plan. Failover plan dependencies and considerations.
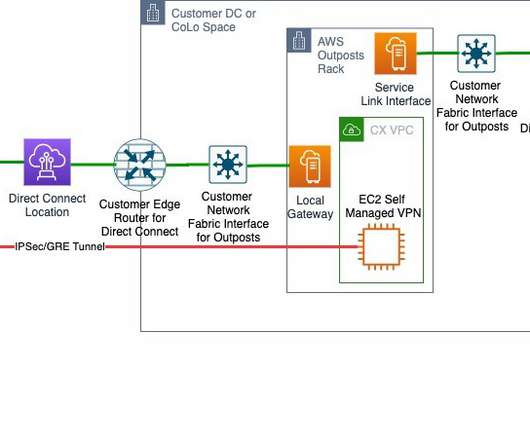
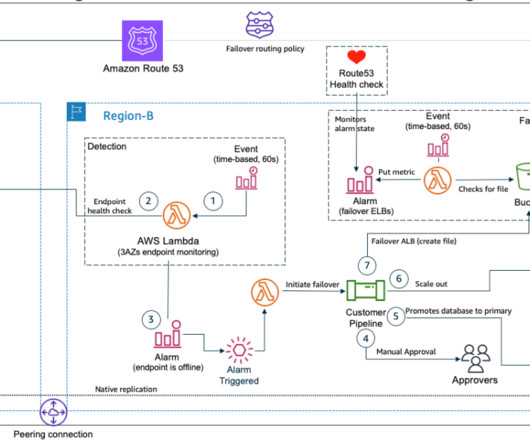
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. During an outage in the primary Region, Velero restores volumes from the latest snapshots in the standby cluster.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. That’s why many customers replicate their mission-critical workloads in multiple places using a DisasterRecovery (DR) strategy suited for their needs. Prerequisites.
The benefits of using Pure Cloud Block Store volumes for SQL Server database storage include, but are not limited to, greater storage efficiency and increased storage availability. . Cost-effective DisasterRecovery . Availability groups can be created to provide highavailability, read scale, or disasterrecovery. .
In this submission, SIOS Technology Solutions Architect Ian Allton outlines the four keys to disasterrecovery implementation, as well as 7 steps to proper business continuity planning. Establishing a disasterrecovery plan could be a stressful task for IT and database administrators. 2) DisasterRecovery Plan.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Many databases use storage replication for highavailability (HA) and disasterrecovery (DR). Data Loss and Corruption.
Data protection is a broad field, encompassing backup and disasterrecovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disasterrecovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
Related on MHA Consulting: The Write Stuff: How to Create and Maintain Business Continuity Documentation Five Ways BC Documentation Can Go Wrong An organization can reap myriad benefits by documenting its business continuity or IT disasterrecovery (IT/DR) program in the form of written recovery plans.
Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements. Earlier, we were able to restore from the backup but wanted to improve availability further. Minimum business continuity for failover.
It offers numerous high-availability solutions. MySQL Workloads DisasterRecovery MySQL databases are the heart of many businesses. This means, of course, that admins need a disaster-recovery plan in place in case a database disruption occurs. It can be virtualized. Single-command failover.
As part of Solutions Review’s ongoing coverage of the enterprise storage, data protection, and backup and disasterrecovery markets, lead editor Tim King offers this nearly 7,000-word resource. This includes the availability of emergency backup services, such as batteries and generators, in case of power outages.
Executives will find this information valuable for enhancing their company’s disasterrecovery plans and ensuring sustained operational effectiveness today and into the future. What is a Recovery Time Objective (RTO)? The Key Elements of RTO: Time Frame: The specific duration within which recovery must be completed.
introducing extreme highavailability for PostgreSQL—up to 99.999%+ availability via active-active technology, according to the vendor. EDB Launches Postgres Distributed 5.0 EnterpriseDB (EDB), the accelerator of Postgres in the enterprise, is launching EDB Postgres Distributed (PGD) 5.0, Read on for more. Read on for more.
Concerns about the ability to meet 99.99% SLAs in the cloud for business critical applications will prompt companies to implement sophisticated application-aware highavailability and disasterrecovery solutions.” ” More Investment in DisasterRecovery. ” Danny Allan, CTO at Veeam.
Today, organizations are having a one-to-one mapping between source clouds and data backup, and disasterrecovery sites lead to multiple standard operating procedures and multiple points of data thefts along with inconsistent recovery SLAs.”
Abstract: Stretched clusters offer the ability to balance VMs, application workloads between two geographically separated datacenters, with non-disruptive workload mobility enabling migration of services between geographically close sites without the need for sustaining an outage.
A good strategy for resilience will include operating with highavailability and planning for business continuity. It also accounts for the incidence of natural disasters, such as earthquakes or floods and technical failures, such as power failure or network connectivity.
This shift is driven by the operational and economic benefits of cloud solutions, yet it comes with its own set of challenges, particularly in the realm of highavailability (HA) environments. Understanding storage patterns and usage can help avoid unexpected slowdowns or outages.
Build Resilience with Automated Backup and DisasterRecovery Downtime, data loss, and compliance failures are costlybusinesses without a resilient hybrid cloud strategy risk prolonged disruptions and financial setbacks. Key takeaway: Resiliency isnt a one-time initiative its an ongoing strategy.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content