This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
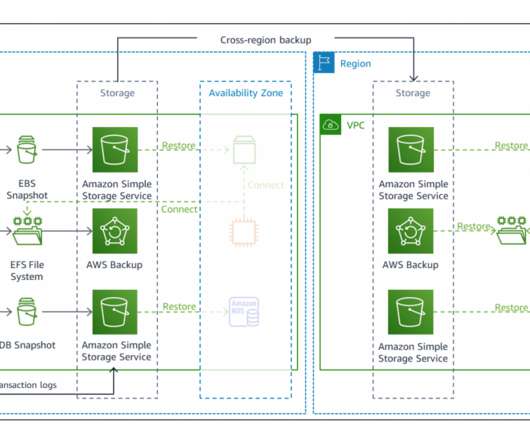
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. DR objectives.
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. What does static stability mean with regard to a multi-Region disasterrecovery (DR) plan? What if the very tools that we rely on for failover are themselves impacted by a DR event? Static stability.
Zerto, a Hewlett Packard Enterprise company, simplifies the protection of a business’s most precious assets by providing disasterrecovery for databases at scale. As the size and number of these server instances increase, so does the complexity and requirements when it comes to disasterrecovery and replication.
In a previous blog post , I introduced you to four strategies for disasterrecovery (DR) on AWS. These strategies enable you to prepare for and recover from a disaster. For your recovery Region, you should use a different AWS account than your primary Region, with different credentials. Related information.
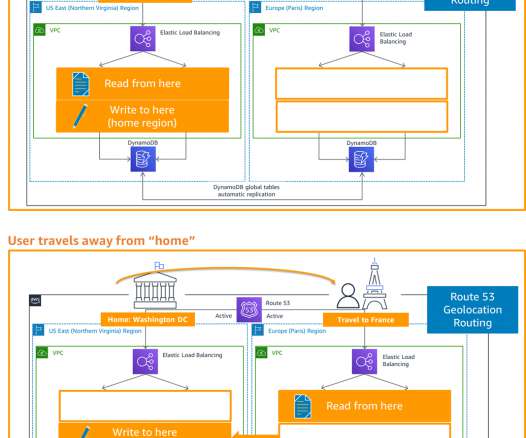
In my first blog post of this series , I introduced you to four strategies for disasterrecovery (DR). With a multi-Region active/active strategy, if your workload cannot operate in a Region, failover will route traffic away from the impacted Region to healthy Region(s). Disasterrecovery options in the cloud whitepaper.
These backup appliances are also dabbling in delivering disasterrecovery capabilities using VM snapshots. Apart from traditional VM backup, software-based backup solutions are also looking to deliver disasterrecovery capabilities using VM snapshots. Trusted disasterrecovery with built-in automation and orchestration.
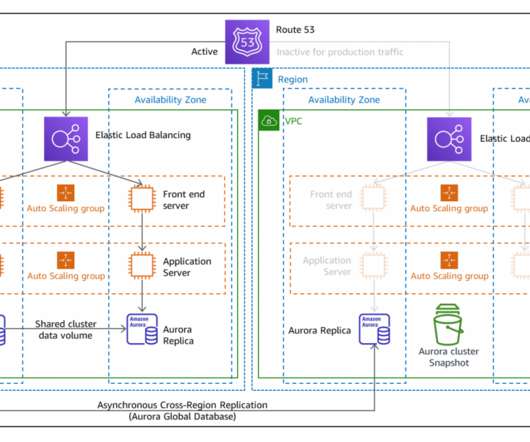
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Previously, I introduced you to four strategies for disasterrecovery (DR) on AWS. Recovery with pilot light or warm standby.
In 2022, IDC conducted a study to understand the evolving requirements for ransomware and disasterrecovery preparation. Check out the IDC whitepaper The State of Ransomware and Disaster Preparedness. DisasterRecovery & Data Protection All-In-One. No application is safe from ransomware. CDP-As-Code.
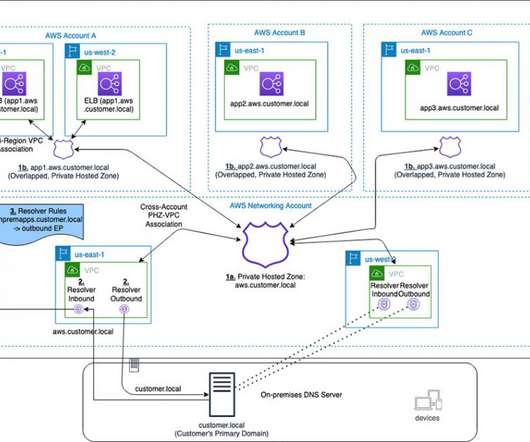
Your business units can use flexibility and autonomy to manage the hosted zones for their applications and support multi-region application environments for disasterrecovery (DR) purposes. Failover routing policy is set up in the PHZ and failover records are created. This architecture involves three key components: 1.
Minimum business continuity for failover. Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements. Earlier, we were able to restore from the backup but wanted to improve availability further.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content