This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. Equip the team with advanced monitoring tools, automated failover systems, and cloud-based collaboration platforms. Redundancy ensures resilience by maintaining connectivity during outages.
Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. This is where Zerto’s failover test and live failover functionalities help users recover from complete infrastructure meltdowns.
You need a robust backup plan and multiple channels of communication and response. This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. power outages, email outages, etc).
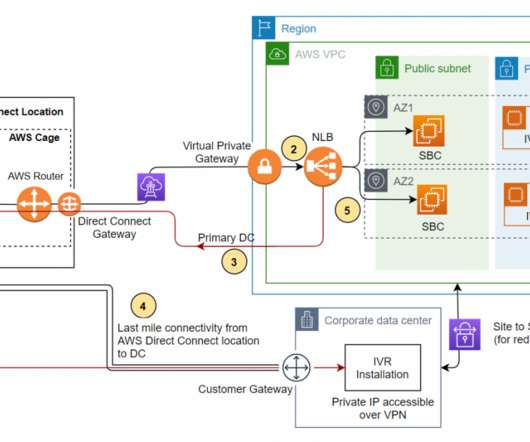
SIP trunk communication on AWS. Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. At this point, the mode of communication becomes IP-based. Communication circuitry at telecom side. Conclusion.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. When you are structuring your DR plan, consider creating isolated networks specifically for failover testing. This includes updating the escalation plan and contact lists.
A separate subnet needs to be configured on the on-premises FlashBlade to communicate with the FlashBlade in the Equinix data center. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source. Data has gravity.
Inter-Pod communications run the risk of being attacked. A Pod can communicate with another Pod by directly addressing its IP address, but the recommended way is to use Services. The Zerto for Kubernetes failover test workflow can help check that box. In Kubernetes, each Pod has an IP address.
You can not only get the evidence that their plan does at least exist, but you’ll be testing how the communications and operational circuits flow between you and them.
These issues can prevent communication between nodes and lead to disruptions in application availability and performance. The Zerto for Kubernetes Failover Test workflow can help users test the failover operations to multiple target sites.
Crisis Communications. She has managed comprehensive planning, training, and exercise programs for companies and organizations in various industries and has received her business continuity certification from Business Continuity Institute (BCI). Business Continuity. Emergency Management. Human Impact/People Support/Workplace Violence.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor offers organizations a unified option for cloud services such as virtual servers, virtual desktops, disaster recovery, IP telephony, unified communications, and contact centers.
They can’t communicate, creating a management nightmare and added complexity. . You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. Data silos cause fragmentation that limits your visibility and collaboration.
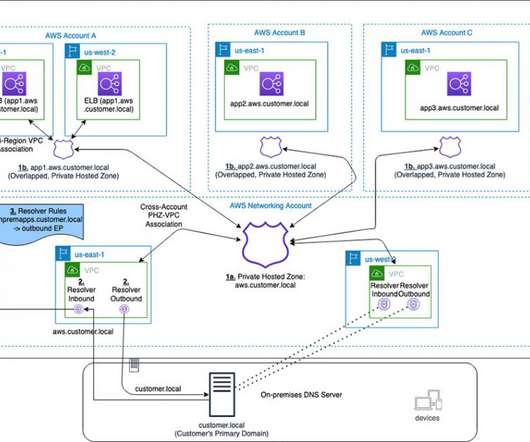
These resources can communicate using private IP addresses and do not require an internet gateway, VPN, or separate network appliances. If a larger failure occurs, the Route 53 Application Recovery Controller can simplify the monitoring and failover process for application failures across Regions, AZs, and on-premises.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The vendor offers organizations a unified option for cloud services such as virtual servers, virtual desktops, disaster recovery, IP telephony, unified communications, and contact centers.
Failover routing policy is set up in the PHZ and failover records are created. As these business applications are internal to the organization, a metric-based health check with Amazon CloudWatch can be configured as mentioned in Configuring failover in a private hosted zone. Considerations.
Language is inherently less rich than reality, but for simplicity’s sake—for the sake of being able to communicate and describe reality—we tend to put things in boxes. And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive.
Critical systems and applications that can’t afford any downtime often employ them to ensure swift failover and maintain operational integrity. If the active node experiences issues, such as hardware failure, the passive node quickly assumes the active role, ensuring uninterrupted communication services for users.
Many data centers incorporate High Availability – redundancy, hardening, segregated graceful failover – and assume that because “It Can Never Fail” there is no need for Disaster Recovery or Business Continuity. When they do plan, they skip over or go light on essential elements.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. During a vendor incident, though, the teams integrating directly with the vendor’s products need to be in the loop for vendor communications. Determine where internal communication will happen.
11:42min- The first actions around personal and worker safety, include a communication cadance. Key Points: 2:09min- Intro to our guest - Sheeba CEO of Akola. 3:03min- What does Akola mean what they do. 6:40min- When she and Akola begin to feel the impacts of the pandemic. 9:33min- There was no plan!
Not only do we provide secure communication channels between the Pure1 Cloud and your FlashArray™ ( which you can read more about in this KB —Pure1 login required), but we also provide checks to ensure the binaries are unaltered before performing the upgrade. This is your last chance to pause or back out of the upgrade process.
This really matters in the performance during a path failover, controller failure, or controller upgrade. Since both back ends can individually handle 100% of the system load, there’s no tangible performance impact if there’s ever a controller failover. And this hand-off takes time, incurring at least some amount of latency.
You need a robust backup plan and multiple channels of communication and response. This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover.
A separate subnet needs to be configured on the on-premises FlashBlade to communicate with the FlashBlade in the Equinix data center. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source. Data has gravity.
A well-designed DRP guides businesses on how to restore communications, critical operations, and systems to a secondary business location if the primary location has been compromised. RTOs and RPOs guide the rest of the DR planning process as well as the choice of recovery technologies, failover options, and data backup platforms.
To help you better formulate plans to deal with a true disaster recovery scenario, apply conditions that simulate an actual disaster such as: Limited communications. Zerto offers fully orchestrated and automated failover testing with built-in reporting for compliance purposes. Limited personnel. Limited networking.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. During a vendor incident, though, the teams integrating directly with the vendor’s products need to be in the loop for vendor communications. Determine where internal communication will happen.
Natural Language Processing (NLP) for Communication Analysis: How it Works: NLP processes and analyzes natural language data, including emails, social media, and news articles. Application: Organizations can use NLP to monitor communication channels for early signs of potential crises , enabling a proactive response.
When a regional storm makes travel difficult and causes short-term power outages, for example, an effective business continuity plan will have already laid out the potential impact, measures to mitigate associated problems, and a strategy for communicating with employees, vendors, customers, and other stakeholders.
When a regional storm makes travel difficult and causes short-term power outages, for example, an effective business continuity plan will have already laid out the potential impact, measures to mitigate associated problems, and a strategy for communicating with employees, vendors, customers, and other stakeholders.
PagerDuty also provides status update templates and web-based Status Pages – directly associated with and linked to Important Business Services (PRA again) – to allow for immediate mass communication to stakeholders and customers.
Adding too many responders to an incident can lead to confusion, duplicate work, and bottlenecks in communication. Examples of this strategy in action are cluster orchestration, automated failovers, state replication, and leader election. It’s a logical assumption: more brains should equal faster problem-solving.
Adding too many responders to an incident can lead to confusion, duplicate work, and bottlenecks in communication. Examples of this strategy in action are cluster orchestration, automated failovers, state replication, and leader election. It’s a logical assumption: more brains should equal faster problem-solving.
We live in a global world where technology is changing the way businesses create and capture value, how we work, and how we communicate and interact. Several third-party services leverage cloud computing and on-premise resources to provide recovery activities, such as data protection, backup, replication, failover, and failback.
This backup can restore the data to how it was when it was copied, helping to preserve data accuracy and protect your business information. While backups can be used for disaster recovery, they aren’t comparable to replication and failover solutions for achieving low Recovery Time Objectives (RTOs) and low Recovery Point Objectives (RPOs).
How to Build Resilience against the Risks of Operational Complexity Mitigation: Adopt a well-defined cloud strategy that accounts for redundancy and failover mechanisms. Your organization should also develop robust reporting mechanisms to track and communicate your IT department’s ESG efforts.
What about the transactions, customer communications, and operational insights lost in the process? Proactive testing: Automated and orchestrated, nondisruptive failover testing verifies your recovery plan works flawlessly when its needed most. But what about the data created in those missing hours?
Disaster recovery and backup: Hyper-V supports live migration, replication, and failover clustering, making it a popular choice for business continuity and disaster recovery solutions. To scale out, Hyper-V uses failover clustering, which allows multiple physical hosts to be grouped together in a cluster.
Mission-critical Workloads Enterprises running mission-critical applications, such as enterprise resource planning (ERP) systems or large-scale databases, require virtualization platforms that guarantee performance, reliability, and failover protection.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content