This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compute Sizing: Ensure Adequate Capacity for Extended Periods One of the most critical aspects of DR compute resources is ensuring you have enough capacity to run your operations for an extended period. Plan for the unexpected : Include additional buffer capacity to handle unexpected workload spikes or increased demand.
BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. Bandwidth Optimization and Capacity Planning Why It Matters: Recovery operations generate significant network traffic. Equip the team with advanced monitoring tools, automated failover systems, and cloud-based collaboration platforms.
Evergreen//Forever benefits include controller upgrades, trade-in credit options, capacity consolidation, and predictable pricing for subscription renewals. Combined with automated operations for SQL Server availability groups to support high availability and failover, you can experience higher uptime and greater data resilience.
Sleep soundly through hardware battles: Hardware failures are inevitable, but with fan-in replication and orchestrated failovers to the centralized target, your data is always protected, ensuring restful nights. FlashArray//C is designed to address operational workload requirements.
Customers only pay for resources when needed, such as during a failover or DR testing. Automation and orchestration: Many cloud-based DR solutions offer automated failover and failback, reducing downtime and simplifying disaster recovery processes. This is a cost-effective solution but with a higher recovery time objective (RTO).
HDD devices are slower, but they have a large storage capacity. Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. Traditionally, the biggest disadvantages of an SSD have been price, degradation, and capacity. SSD devices are faster, but they also cost more.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward.
Constantly Running Out of Capacity Symptom: Were always scrambling for more storage space, and adding capacity is expensive and disruptive. Root Cause: Some IT teams try to address performance and capacity issues by spinning up more VMs or increasing allocated resources per VM, leading to inefficiencies.
All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. Before failover, the infrastructure must scale up to meet production needs.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Pure Cloud Block Store provides the following benefits to SQL Server instances that utilize its volumes for database files: A reduction in cost for cross availability zone/region traffic and capacity consumption.
And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive. And while all front-end ports on a FlashArray system are active, only one controller is actively processing IO at any given time. This approach guarantees consistent 100% performance , even in controller failure scenarios.
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. You also have thin provisioning, dedupe, and compression.
Private, public, and hybrid cloud offerings offer several advantages including on-premise protection, failover options, flexible workloads, and storage capacity to safeguard your critical data, applications, and IT assets when a crisis hits. The right technologies and resources can help you achieve this.
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Amazon RDS database.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Druva customers can reduce costs by eliminating the need for hardware, capacity planning, and software management.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Druva customers can reduce costs by eliminating the need for hardware, capacity planning, and software management.
The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover. The warm standby strategy deploys a functional stack, but at reduced capacity. Pilot light DR strategy. Warm standby DR strategy. Similarities between these two DR strategies.
Resource Balancer only uses capacity-free space to determine where to place the new volume.¹³ This is why PowerStore can support different models with different capacities in the same “cluster,” because data is located only on one appliance at a time. And this hand-off takes time, incurring at least some amount of latency.
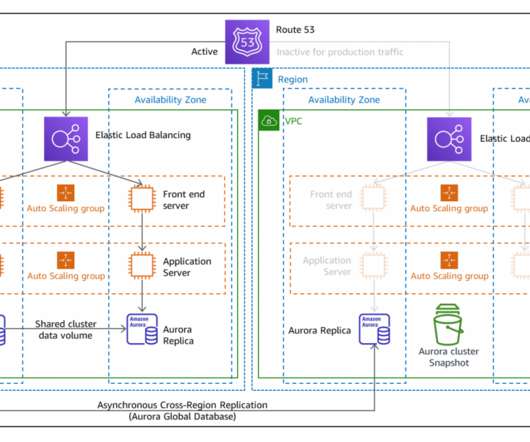
Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources.
Using AWS as a DR site also saves costs, as you only pay for what you use with limitless burst capacity. Testing failovers frequently and non-disruptively in an isolated environment provides users with the confidence to create a recovery workflow and set clear expectations for stakeholders.
semi-manual deployments, schema updates/rollbacks, changing storage quotas, network changes, user adds, adding capacity, DNS changes, service failover). For the organization, high-levels of toil lead to: Shortages of team capacity. This capacity requirement is why toil is such a central concept for SRE.
During failover, scale up resources and increase traffic to the Region. This pattern works well for applications that must respond quickly but don’t need immediate full capacity. Besides the cost of maintaining some minimal capacity as in the warm standby approach, you scale each Region to have some extra capacity.
These two technologies work together to give you backup solutions and provide failover if a single drive fails. If you decide to build a backup solution for your network with potentially petabytes of storage capacity, a NAS is an array of drives that work together to store data. What Does a NAS RAID Mean? Benefits of RAID and NAS.
This optimizes storage and allows the same storage capacity to store more recovery points. Zerto In-Cloud for AWS Updates Reverse Replication For more seamless full recovery options, reverse replication can now be configured to automatically replicate back to the selected region after failover to the recovery site.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward.
PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover. Get started with Portworx—try it for free. .
With business growth and changes in compute infrastructures, power equipment and capacities can become out of alignment, exposing your business to huge risk. Some of them use manual runbooks to perform failover/failbacks. This puts compute infrastructures at risk of overheating should there be a generator failure.
When most storage vendors talk about non-disruptive upgrade (NDU) they’re focusing on software upgrades, or adding storage capacity to an existing storage array. Pairing the FlashArray’s architecture with the Purity operating environment, which handles dynamic controller failovers, allows the controllers to be completely transparent.
Over time, these plans can be expanded as resources, capacity, and business functionality increase. RTOs and RPOs guide the rest of the DR planning process as well as the choice of recovery technologies, failover options, and data backup platforms. This makes RTO and RPO calculations a key part of the DR planning process.
Pulling myself out of bed and rolling into the office at 8am on a Saturday morning knowing I was in for a full day of complex failover testing to tick the regulator’s box was a bad start to the weekend. Part 4 will show how to use this for real DR failover scenarios and subsequent failbacks.
Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations. Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failover event. Multi-direction replication.
To counteract this challenge, Nissan Australia runs its manufacturing workloads on VMware in an active-active configuration across two data centers that leverage Pure Storage® FlashArray//X ™ with ActiveCluster ™ for seamless failovers. What’s more, they had to pay for two systems concurrently during those crossover periods.
Easily create, delete, and edit VMFS, vVol, and NFS datastores and FlashArray snapshots; manage replication operations; perform failover/failback for virtual volumes; manage capacity; monitor performance; restore VMs from the vSphere UI; and many, many more functions that will make your life easier. Get this one—it’s a must-have.
They knew that they had failover servers and had assumed that during a cyber attack they would get access back within 15 minutes. There was some debate about whether there was sufficient capacity in other hospitals, if large numbers had to move to another hospital.
Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. These include automated capacity management capabilities, data and application disaster recovery, application-aware high availability, migrations, and backup and restore. This is where Portworx comes in.
Minimum business continuity for failover. This allows us to adjust capacity needs by forecasting usage patterns along with configurable warm-up time for application bootstrap. In the following sections, we show you the steps we took to improve system resiliency for our example company. Standardize observability.
Non-disruptive infrastructure upgrades allow for storage device firmware updates, enterprise storage expansion, and reliable seamless failover (from unexpected infrastructure incidents), while keeping the data pipelines and low-latency analytics product applications running smoothly and continuously.
More complex systems requiring better performance and storage capacity might be better using the ZFS file system. Using Btrfs, administrators can offer fault tolerance and failover should a copy of a saved file get corrupted. Btrfs and ZFS are the two main systems to choose from when you partition your disks. What Is Btrfs?
Using Docker, you can take advantage of your full compute capacity. . Enterprise-grade resiliency with automated failover and self-healing data access integrity. Advantages of Kubernetes. Kubernetes is an orchestration platform that streamlines the tasks of managing Docker containers. . Policy-based provisioning.
Later generations of Symmetrix were even bigger and supported more drives with more capacity, more data features, and better resiliency. . Today, Pure1 can help any type of administrator manage Pure products while providing VM-level and array-level analytics for performance and capacity planning. HP even shot its array with a.308
HA cannot be left as a homework exercise: Requiring a customer to buy two machines and then figure out how to configure failover, resync and failback policies is not what we mean by HA. It is self-healing. Enterprise HA is crucial for compatibility with existing enterprise workloads like VMware, Oracle, Microsoft, et al.
New SafeMode Snapshot replication, capacity management with threshold customization release notes (Pure1 ® login required) Purity//FA 6.4.3: Once the failover completes, the current secondary controller gets upgraded. Purity//FA 6.4 Release Highlights Here are some of the features we introduced in 6.4: Purity//FA 6.4.10: NFS 4.1
This means that organizations can avoid overprovisioning and underutilization of resources, paying only for the capacity they need when they need it. The cloud provider offers a range of tools for data backup, failover, and recovery, minimizing risks associated with data loss and downtime.
That’s why “ resiliency ,” the capacity to withstand or recover quickly from difficulties, is key. How to Build Resilience against the Risks of Operational Complexity Mitigation: Adopt a well-defined cloud strategy that accounts for redundancy and failover mechanisms. Things will go wrong.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content