This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How to Set Up a Secure Isolated Recovery Environment (SIRE) by Pure Storage Blog If youve suffered a breach, outage, or attack, theres one thing you should have completed and ready to go: a secure isolated recovery environment (SIRE). Heres why you need a secure isolated recovery environment and how to set one up. Why Do You Need a SIRE?
For my current client, I first considered this system’s potential after a hypothetical hurricane or extreme weather event. While Aruba has not faced a severe hurricane in living memory, such a system could still be valuable after an event causing widespread damage.
Events like KubeCon highlight the need for ongoing learning, tooling, and collaboration to manage Kubernetes effectively. Whats often referred to as an incident can range from routine IT tasks (like increasing system capacity) to major outages. Treating all incidents the same way can lead to unnecessary complexity.
I think with cyber threats and power outages being the focus of the moment, occupying us business continuity folks, we have forgotten about a good old threat: the computer outage. There is very little spare capacity in the system to accommodate delayed passengers and cancelled flights, so the effects take days to sort out.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. .
Cyber resilience refers to an organization’s capacity to sustain operations and continue delivering to customers during a critical cyber event, whether it’s an internal disruption or an external threat. Adaptability and agility are key components of cyber resilience, allowing businesses to respond effectively to such events.
Many are asking why the airline didn’t have backup systems, where their planning for this type of event was and why the plan hadn’t been exercised, as this would have greatly improved their response. When you run your operations at near capacity, the disruption has a long tail of knock-on effects.
Many are asking why the airline didn’t have backup systems, where their planning for this type of event was and why the plan hadn’t been exercised, as this would have greatly improved their response. When you run your operations at near capacity, the disruption has a long tail of knock-on effects.
Aside from data backup and replication considerations, IT organizations and teams also need to design robust disaster recovery (DR) plans and test these DR plans frequently to ensure quick and effective recovery from planned and unplanned outageevents when they occur. The right technologies and resources can help you achieve this.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. This Year, 10 Is Pure’s Magic Number A decade ago, customers needed giant arrays stretching across multiple racks for the kind of problems they solved with our early FlashArray systems.
Remember, after an outage, every minute counts…. Pure SafeMode is a built-in feature of the Purity Operating Environment that prevents data from being manually deleted before the policy/timer expires, allowing you to recover quickly in the event of a mistake or malicious activity.
If we don’t meet the performance or capacity obligations, we proactively ship more storage arrays and set them up at no cost to you. This is because Pure Storage® is committing to a performance and capacity obligation. Pure’s Capacity Management Guarantee . We’re clear about our obligation in our product guide.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. DR Strategies. OpenSearch Service.
If you’ve suffered a breach, outage, or attack, there’s one thing you should have completed and ready to go: a staged recovery environment (SRE). This should be set up in advance, tested, and in a ready state to be transitioned into quickly after an event. During an event, and. After an event. It’s all about speed.
Capacity, speed, and reliability of data storage rapidly improved from floppy disks, to hard disks, to today’s modern flash drives. Modern data center operations have evolved – planned and unplanned outages have direct impact on business operations, so maintenance windows have become razor-thin and unexpected outages are not tolerated.
Cloud services rely on the provider’s infrastructure, which means their service disruptions or outages can affect your business operations. You have limited control over uptime since outages are out of users control. The cons: Storing data off-site means you may have less control over security.
Data center outages come in many forms and often occur at the most unfortunate of times. An unplanned uninterruptible power system (UPS) failure, human error, or weather event has the potential of sending an organization into a data-driven tailspin. In the guide, you’ll find: Key trends driving infrastructure modernization.
Modern space-efficient storage infrastructure has helped reduce cost and complexity, increased availability, and provided greater capacity, allowing us to support these ever-growing data set demands. . Data Loss and Corruption. Traditional Database Recovery. In-place Surgical Data Fix.
From storms triggering electrical outages to droughts and heat domes that can contribute to wildfires (which in turn can cause poor air quality), all these hazards have the potential to cause detrimental impacts to your organization. Have alternatives in the event of utility outages All businesses and organizations are reliant on utilities.
This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Scope of impact for a disaster event.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. This Year, 10 Is Pure’s Magic Number A decade ago, customers needed giant arrays stretching across multiple racks for the kind of problems they solved with our early FlashArray systems.
It involves defining and implementing policies and procedures to ensure an effective response in the event of a major disruption so that you can continue to provide an acceptable level of service. BCM (business continuity management) is a form of risk management that deals with the threat of business activities or processes being interrupted.
About FlashBlade//E FlashBlade//E is a new all-flash capacity-optimized unified file and object storage platform from Pure Storage. The backup data can be instantly rolled back to any snapshot, preventing malicious or accidental deletion of backup data to enable fast recovery from ransomware attacks and similar events.
CIOs can use the capacity required immediately via OPEX, manage costs over time based upon discounting, and have the ability to burst into the type of high IO (a.k.a. It’s simple to activate snapshots and set up replication, which can help you facilitate quick recovery in the event of a system failure or data loss. .
. Due to COVID-19, businesses may not be operating at a normal capacity. Some may still be vacant, while others are operating at a reduced capacity or with strict COVID protocols. Your building maintenance team may be operating at a reduced capacity or solely depending on a single person. BACKUP POWER. . Standby generator.
These events could be man-made (industrial sabotage, cyber-attacks, workplace violence) or natural disasters (pandemics, hurricanes, floods), etc. It is a strategy designed to help businesses continue operating with minimal disruption during a disruptive event. Business Continuity Plan vs. Disaster Recovery Plan.
This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. You can fail over to Pure Cloud Block Store in the event of an on-prem failure and fail back when needed. Scalability and Flexibility The cloud enables businesses to quickly provision resources as needed.
In today’s post we’ll look at why organizations still need to be adept at IT disaster recovery (IT/DR) and describe the four phases of restoring IT services after an outage. Phase 1: Preparation Technically, preparation is not a phase of disaster recovery since it happens before the outage. Estimate how long the outage will last.
They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. The system can quickly detect outages and report them to the utility, leading to faster restoration of services. Customers are also informed about the state of outages in real time.
Decoupling integrations using event-driven design patterns. This allows us to adjust capacity needs by forecasting usage patterns along with configurable warm-up time for application bootstrap. Production outages are scary for everyone, but with the right system monitoring solution, they can be made less stressful.
The key to running the data centres is the work which goes into the infrastructure to ensure that any possible event which could lead to downtime is eliminated. As the data centre industry is very small, if you have an outage your rivals will very quickly hear about it and will use this when they are bidding against you.
The key to running the data centres is the work which goes into the infrastructure to ensure that any possible event which could lead to downtime is eliminated. As the data centre industry is very small, if you have an outage your rivals will very quickly hear about it and will use this when they are bidding against you.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. For instance, if an outage occurs, having a unified view can help teams quickly identify and resolve issues, minimizing the impact on customer experience. Take the product tour.
For a hyperconnected digital business, even a small disruptive event can ripple through the entire organization. With business growth and changes in compute infrastructures, power equipment and capacities can become out of alignment, exposing your business to huge risk. Today most businesses have BCDR plans.
We’re gearing up for an amazing event, and I can’t wait to share what we’ve been working on. They also offer non-disruptive workload mobility enabling migration of services between geographically close sites without the need for sustaining an outage.
A few months ago, a global pandemic with the capacity to bring the world to a standstill was almost unthinkable. Initiation, training and communication across the organisation are crucial in the event that the team is unable to fulfil its role, for whatever reason. Yet, here we are. Business Continuity Plan Checklist .
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. For instance, if an outage occurs, having a unified view can help teams quickly identify and resolve issues, minimizing the impact on customer experience. Take the product tour.
FlashArray//C provides a 100% NVMe all-flash foundation for capacity-oriented applications, user/file shares, test and development workloads, multisite disaster recovery, and data protection. Once verified, you can recover your snapshots to get your data back online quickly and safely. . Learn More.
Combining the data-reducing capabilities of FlashArray with Pure1 ® AIOps forecasting , planning for future capacity and performance needs for an SAP deployment becomes trivial, allowing for business needs to be met in advance of unexpected growth periods. By 2025, approximately 1.2
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. Other reasons include to minimize the operational, financial, legal, reputational and other material consequences arising from such events. Architecture Walkthrough.
Once that information was gathered, I would verify that the switch had a “suitable for use as service equipment” (SUSE) label, and that it had proper capacity, ratings, listing, and labeling. If everything checks out, then I would have the installer initiate a power outage scenario to make sure all systems were functioning properly.
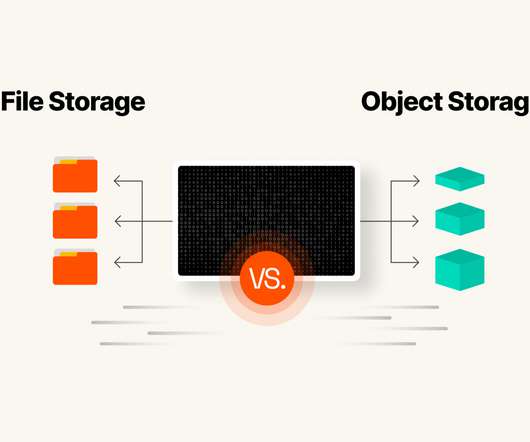
Because of the differences in structure, file storage and object storage have significantly different capacity to scale. While file storage isn’t considered extremely expensive, it can result in higher costs as you add capacity. In this article, we’ll take a look at the common differences between traditional object and file storage.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. This Year, 10 Is Pure’s Magic Number A decade ago, customers needed giant arrays stretching across multiple racks for the kind of problems they solved with our early FlashArray systems.
The manufacturing processes they support—like the aluminum casting required to produce powertrain and engine components—are energy-intensive and prone to outages. With Pure Evergreen//Forever ™, Nissan Australia can continuously scale its capacity and upgrade its arrays with zero disruption to its operations. “I
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content