This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. DR objectives. Related information.
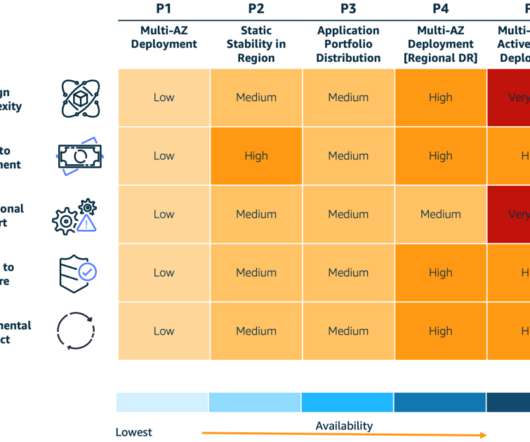
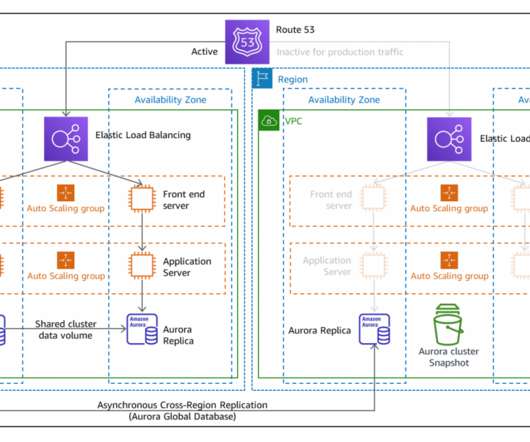
P1 is less expensive because it provisions less compute capacity and relies on launching new instances in case of a failure. P4 – Multi-AZ deployment (multi-Region disasterrecovery). Data is actively replicated and application infrastructure is pre-provisioned in the disasterrecovery (DR) Region. Trade-offs.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Previously, I introduced you to four strategies for disasterrecovery (DR) on AWS. Related information.
Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements. This allows us to adjust capacity needs by forecasting usage patterns along with configurable warm-up time for application bootstrap.
NOTE: DRII takes this definition from the Business Continuity Institute BCI and DisasterRecovery Journal DRJ. Can personnel on shifts work longer or different shifts without impacting output or capacity? Business Continuity and DisasterRecovery. Do we need to hire new workers? Continuity. BCP and BCP Meaning.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content