This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Disasters are unpredictable, but your response to them shouldn’t be. A well-thought-out disasterrecovery (DR) plan is your best defense against unexpected disruptions. During a disaster, the duration of the recovery period can be uncertain, and underestimating your compute needs can lead to significant disruptions.
To navigate these challenges, organizations must adopt a comprehensive disasterrecovery (DR) strategy. Networking ensures the rapid recovery of critical systems and data, directly influencing key metrics like Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs).
Automating DisasterRecovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disasterrecovery can offer many advantages for organizations. Customers only pay for resources when needed, such as during a failover or DR testing.
Solutions Review’s listing of the best DisasterRecovery as a Service companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. Technically speaking, DisasterRecovery as a Service (DRaaS) tools are often labeled as stand-alone offerings.
Solutions Review’s listing of the best cloud disasterrecovery solutions is an annual sneak peek of the solution providers included in our Buyer’s Guide for DisasterRecovery as a Service. To make your search a little easier, we’ve profiled the best cloud disasterrecovery solutions all in one place.
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. DR objectives.
In part I of this series, we introduced a disasterrecovery (DR) concept that uses managed services through a single AWS Region strategy. Health checks are necessary for configuring DNS failover within Route 53. DisasterRecovery with AWS Managed Services, Part I: Single Region. Other posts in this series.
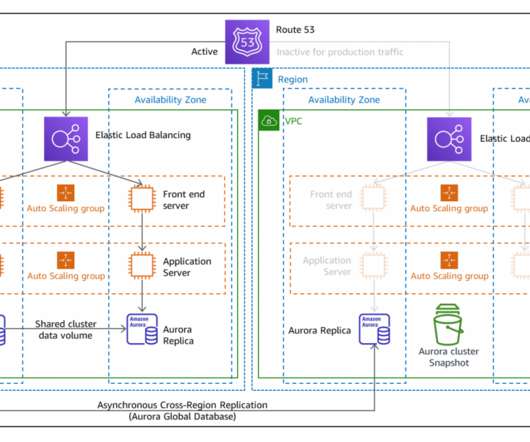
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disasterrecovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Figure 1. Amazon RDS database.
This consolidation simplifies management, enhances disasterrecovery (DR), and offers a treasure trove of benefits. Disasterrecovery woes, begone: Testing and maintaining DR plans for every array is a complex beast. Vanquish backup nightmares: Tired of late nights managing backups from individual arrays?
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Previously, I introduced you to four strategies for disasterrecovery (DR) on AWS. Recovery with pilot light or warm standby.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Cost-effective DisasterRecovery . More efficient data movement, resulting in more consistent recovery point objectives . Figure 1: The //V10 and //V20 versions of Pure Cloud Block Store.
HDD devices are slower, but they have a large storage capacity. Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. Also, HDDs can hold more data currently, so they’re preferred for long-term storage with fewer reads, such as storage reservoirs for disasterrecovery and backups.
Constantly Running Out of Capacity Symptom: Were always scrambling for more storage space, and adding capacity is expensive and disruptive. Root Cause: Some IT teams try to address performance and capacity issues by spinning up more VMs or increasing allocated resources per VM, leading to inefficiencies.
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. You also have thin provisioning, dedupe, and compression.
These events could be man-made (industrial sabotage, cyber-attacks, workplace violence) or natural disasters (pandemics, hurricanes, floods), etc. Business Continuity Plan vs. DisasterRecovery Plan. What Is A DisasterRecovery Plan? Learn More About what is DisasterRecovery Plan.
We also discuss how Zerto in Cloud for AWS can protect and recover Amazon EC2 instances across Availability Zones (AZs) and AWS Regions, scaling to recover thousands of virtual instances with cloud-native disasterrecovery. Using AWS as a DR site also saves costs, as you only pay for what you use with limitless burst capacity.
Aside from data backup and replication considerations, IT organizations and teams also need to design robust disasterrecovery (DR) plans and test these DR plans frequently to ensure quick and effective recovery from planned and unplanned outage events when they occur.
This quarter I will fill you in on all the recent updates to Zerto and HPE GreenLake for DisasterRecovery. Updates to the Zerto Virtual Manager appliance (ZVMA) Journal Storage Optimization For more efficient storage use, we now offer compression for recovery journal storage.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward.
Executive builders should center their resilience strategies around availability, performance, and disasterrecovery (DR). Availability and disasterrecovery. Multi-Region disasterrecovery patterns. During failover, scale up resources and increase traffic to the Region. Active-active (Tier 1).
MySQL Workloads DisasterRecovery MySQL databases are the heart of many businesses. This means, of course, that admins need a disaster-recovery plan in place in case a database disruption occurs. Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations.
Minimum business continuity for failover. Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements. Earlier, we were able to restore from the backup but wanted to improve availability further.
PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover. Get started with Portworx—try it for free. .
Business continuity and disasterrecovery (BCDR) plans need to keep pace with increasing business demands and growth in physical and compute infrastructures. With business growth and changes in compute infrastructures, power equipment and capacities can become out of alignment, exposing your business to huge risk.
With data centers in different locations worldwide, AWS ensures high availability, disasterrecovery, and performance optimization, making it a preferred cloud provider for organizations of all sizes. Are you aiming to reduce costs, improve disasterrecovery, or enhance scalability? Why Migrate VMware to AWS EC2?
Easily create, delete, and edit VMFS, vVol, and NFS datastores and FlashArray snapshots; manage replication operations; perform failover/failback for virtual volumes; manage capacity; monitor performance; restore VMs from the vSphere UI; and many, many more functions that will make your life easier. Get this one—it’s a must-have.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 1 of 4 by Pure Storage Blog In this four-part series, I’ll explore using ActiveDR ™ for managing Oracle disasterrecovery. Part 4 will show how to use this for real DR failover scenarios and subsequent failbacks.
Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. These include automated capacity management capabilities, data and application disasterrecovery, application-aware high availability, migrations, and backup and restore.
That’s why “ resiliency ,” the capacity to withstand or recover quickly from difficulties, is key. How to Build Resilience against the Risks of Operational Complexity Mitigation: Adopt a well-defined cloud strategy that accounts for redundancy and failover mechanisms. Things will go wrong.
Concerns about the ability to meet 99.99% SLAs in the cloud for business critical applications will prompt companies to implement sophisticated application-aware high availability and disasterrecovery solutions.” ” More Investment in DisasterRecovery. ” Michael Lauth, CEO at iXsystems.
Rapid recovery and migrations with Zerto for AWS Whether migrating or protecting virtual instances on premises or to AWS, Zerto uses the unlimited capacity of the public cloud while minimizing downtime and data loss so you can achieve your recovery point objectives (RPOs) and recovery time objectives (RTOs) with ease.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content