
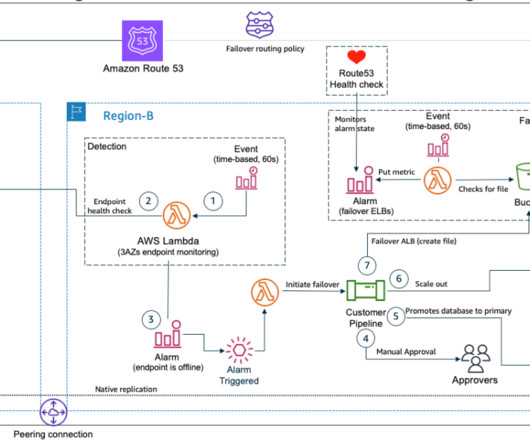
How an insurance company implements disaster recovery of 3-tier applications
AWS Disaster Recovery
NOVEMBER 11, 2024
A good strategy for resilience will include operating with high availability and planning for business continuity. AWS recommends a multi-AZ strategy for high availability and a multi-Region strategy for disaster recovery. In this blog, we are going to focus on how one of our financial services customer implements it.



















Let's personalize your content