This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How Pure Protect //DRaaS Shields Your Business from Natural Disasters by Pure Storage Blog Summary Pure Protect //DRaaS shields your business from the rising threat of natural disasters. Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability.
Give your organization the gift of Zerto In-Cloud DR before the next outage . At the end of November, I blogged about the need for disaster recovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then.
Downtime Will Cost You: Why DRaaS Is No Longer Optional by Pure Storage Blog Summary Unforeseen disruptions like natural disasters, cyberattacks, or hardware failures can pose a significant threat to companies and their financial and reputational health. Investing in disaster recovery as a service (DRaaS) can help businesses stay resilient.
Automating Disaster Recovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disaster recovery can offer many advantages for organizations. This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster.
It helps keep your multi-tier applications running during planned and unplanned IT outages. For those organizations that choose to migrate and run their mission-critical applications on the cloud, Pure Cloud Block Store ™ offers built-in protection against outages of availability zones, regions, and even clouds.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. power outages, email outages, etc).
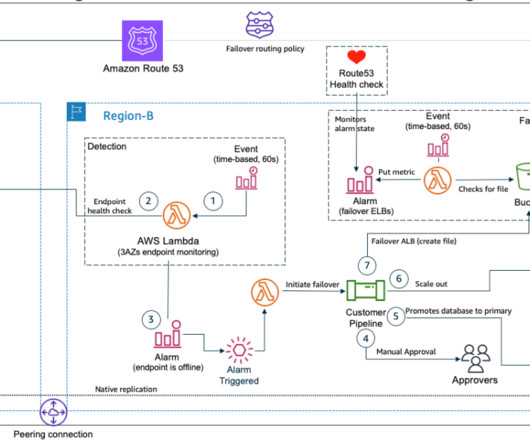
Using multiple Regions ensures resiliency in the most serious, widespread outages. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. DR Strategies. ElastiCache.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
This blog post shows how to architect for disaster recovery (DR) , which is the process of preparing for and recovering from a disaster. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. All requests are now switched to be routed there in a process called “failover.”
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1,
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 4 of 4 by Pure Storage Blog This is the fourth and final part of this series, which explores using ActiveDR for managing Oracle disaster recovery. In Part 2, we learned how to build a DR database from our replicated volumes. Read more about it in my Medium post.
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
In part 2 of our three-part cloud data security blog series, we discussed the issue of complexity. Combined with the container-level backup capabilities of PX-Backup, customers now have a way to quickly recover their containerized workloads in case of outages. In part 3, we’ll discuss the issue of getting control. .
Synchronous replication is mainly used for high-end transactional applications that require instant failover if the primary node fails. If there’s an accident or outage, then transactions and data that aren’t replicated at the time of the incident will be lost, and data in secondary storage may not always be current.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 1 of 4 by Pure Storage Blog In this four-part series, I’ll explore using ActiveDR ™ for managing Oracle disaster recovery. Once complete, our database volumes have replicated to the DR array and are safe in the event of any failure/outage at the PROD site.
How to Accelerate MySQL Workloads by Pure Storage Blog This article on MySQL Workloads was coauthored by Andrew Sillifant and Nihal Mirashi. In a previous blog post, I covered 4 common MySQL issues and how to solve them. Single-command failover. The post How to Accelerate MySQL Workloads appeared first on Pure Storage Blog.
Winner for APJ by Pure Storage Blog From the family-friendly Qashqai SUV to the all-electric Leaf compact, Nissan Australia has a mobility solution for every Australian. Winner for APJ appeared first on Pure Storage Blog. Breakthrough Award: Nissan Australia, Our G.O.A.T. Congratulations to you and everyone at Nissan Australia!
Typically, backup systems are called into action for discrete outages. A proper DR plan does not necessarily require a hot failover site. If you don’t have a failover site, mission-critical apps and their resources can be stored as replicas, which can be quickly transferred to a secondary data center.
by Pure Storage Blog When the unexpected happens, poorly prepared businesses run the risk that everything could come to a screeching halt. This typically involves detailed technical strategies for system failover, data recovery, and backups. appeared first on Pure Storage Blog.
by Pure Storage Blog When the unexpected happens, poorly prepared businesses run the risk that everything could come to a screeching halt. This typically involves detailed technical strategies for system failover, data recovery, and backups. appeared first on Pure Storage Blog.
In fact, over the course of a 3-year period, 96% of businesses can expect to experience at least one IT systems outage 1. Unexpected downtime can be caused by a variety of issues, such as power outages, weather emergencies, cyberattacks, software and equipment failures, pandemics, civil unrest, and human error.
According to the Veeam Data Protection Report 2021 , the average hourly toll of downtime is $84,650, the typical outage taking around 79 minutes to resolve. An IT pro might do a failover or two in their entire career – we handle multiple ones on a monthly basis. Why the need for disaster recovery specialists? There’s cost.
They can set up automated failovers that will automatically shift workloads from one server or data center to another in case the main one fails or crashes unexpectedly. MSPs can implement robust backup and disaster recovery solutions that prevent data loss.
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. If not, a single controller failure could cause a data outage or corruption.
IT’s 4 Biggest Risks and How to Build Resilience against Them by Pure Storage Blog IT departments face risks and challenges on a daily basis—not all of which are necessarily within their ultimate control. Such outages can cripple operations, erode customer trust, and result in financial losses. Things will go wrong.
Relational vs. Non-relational Databases by Pure Storage Blog Relational databases and non-relational databases primarily differ in the types of data they store and how that data is organized. The post Relational vs. Non-relational Databases appeared first on Pure Storage Blog. Built-in replication.
These examples illustrate how AI can play a crucial role in enhancing IT disaster recovery by automating processes, optimizing resource allocation, and preemptively calling for maintenance and repair to prevent outages improving overall resilience in the face of technological disruptions.
This design needs to keep costs at a minimum, and it needs to allow for failure detection and manual failover of resources. The solution Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environments.
Warning: A single failurecyberattack, outage, or human errorcould result in total data loss and extended downtime. Businesses that go beyond the 3-2-1 framework by implementing immutability, isolation, and rapid failover solutions are the ones that stay operational, no matter the disruption. Are You Up for the Backup Challenge?
Architect for high availability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions. Deploy AI-driven monitoring and anomaly detection Use predictive analytics to detect and mitigate failures before they escalate into major outages.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content