This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Pure//Launch Blog October Edition by Pure Storage Blog Summary We’ve been hard at work making enhancements to the Pure Storage platform to augment data protection, help you get more out of your Kubernetes environment, triage issues faster, and more. We’re never finished innovating here at Pure Storage.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Active-active vs. Active-passive: Decoding High-availability Configurations for Massive Data Networks by Pure Storage Blog Configuring highavailability on massive data networks demands precision and understanding. Related reading: What Is Oracle HighAvailability? and What Is MySQL HighAvailability?
So, given its importance, you want to make sure you have a solid solution for ensuring it’s highly available or protected in the event of a disaster. Most SAP HANA customers today are using SAP HANA system replication (HSR) to ensure the highavailability and disaster recovery systems remain in sync.
Pure Cloud Block Store offers built-in data protection that leverages multiple high-availability zones (AZs), to reduce physical fault domain exposure. Pure Cloud Block Store removes this limitation with an architecture that provides highavailability. Kunal Kapoor, Director Product Management, Pure Storage.
In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. AWS Regions are built with multiple isolated and physically separate Availability Zones (AZs). We’ve chosen some AWS Solutions and AWS Blogs to help you! Considerations before getting started.
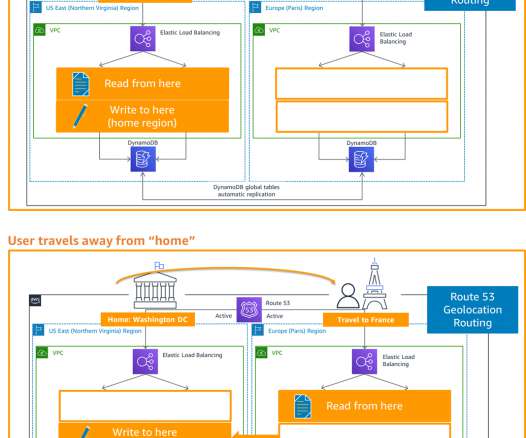
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1,
Introducing Pure Protect //Disaster Recovery as a Service (DRaaS) by Pure Storage Blog In today’s unpredictable world, natural disasters are ramping up in both frequency and intensity. The plan typically includes regular backups both on-site and off-site, redundant hardware for highavailability (HA), and failover systems.
Top 8 VMware Alternatives by Blog Home Summary Virtualization software is a powerful tool that can help businesses increase efficiency, reduce costs, and improve resource utilization. While VMware holds a significant market share, several other offerings are available to fit various needs and budgets.
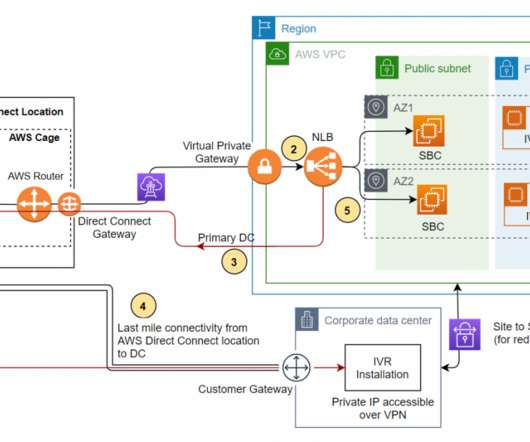
Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. Load balancing across AWS and on-premises resources using the same load balancer streamlines migrate-to-cloud, burst-to-cloud, or failover-to-cloud. Conclusion.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
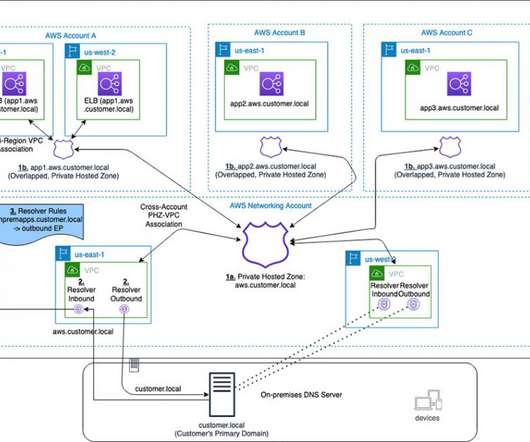
This blog presents an architecture that provides a unified view of the DNS while allowing different AWS accounts to manage subdomains. It utilizes PHZs with overlapping namespaces and cross-account multi-region VPC association for PHZs to create an efficient, scalable, and highly available architecture for DNS. Architecture Overview.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). This makes your infrastructure more resilient and highly available and allows business continuity with minimal impact on production workloads. Amazon RDS database.
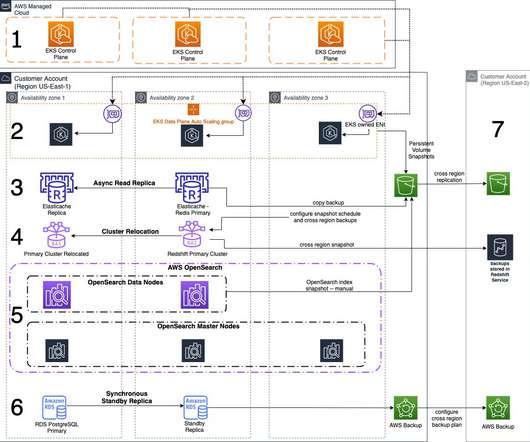
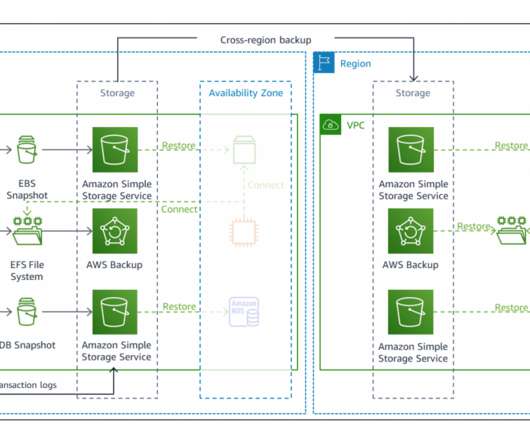
This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. In Part I, we’ll discuss the single AWS Region/multi-Availability Zone (AZ) DR strategy. Amazon RDS PostgreSQL. Backing up data across Regions.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Availability groups can be created to provide highavailability, read scale, or disaster recovery. .
How to Accelerate MySQL Workloads by Pure Storage Blog This article on MySQL Workloads was coauthored by Andrew Sillifant and Nihal Mirashi. It offers numerous high-availability solutions. In addition, MySQL delivers high performance; if a website receives millions of queries a day, users experience timely responses.
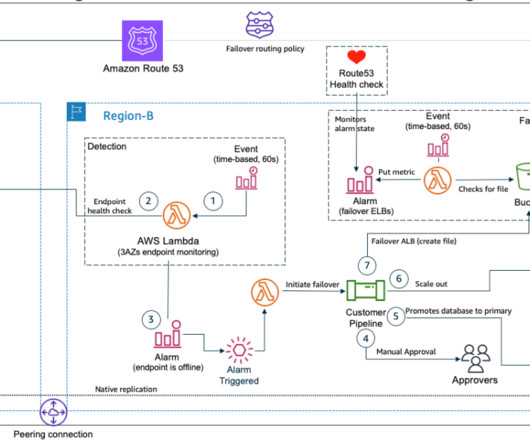
In my first blog post of this series , I introduced you to four strategies for disaster recovery (DR). Each Region hosts a highly available, multi- Availability Zone (AZ) workload stack. Figure 2 shows Amazon Route 53 , a highly available and scalable cloud Domain Name System (DNS) , used for routing.
Bogus Statements) by Pure Storage Blog (For the purposes of this post, “B.S.” This really matters in the performance during a path failover, controller failure, or controller upgrade. Since both back ends can individually handle 100% of the system load, there’s no tangible performance impact if there’s ever a controller failover.
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
In a previous blog post , I introduced you to four strategies for disaster recovery (DR) on AWS. By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. Availability: Concerns to solve for highavailability (HA) and DR. Now let’s discuss how we can address these concerns in the AWS Cloud. Warm standby (Tier 3). Conclusion.
Pure Storage with VMware Integrations: Get the Most Out of Your Storage by Pure Storage Blog When folks think about Pure Storage, and more specifically, Pure Storage ® FlashArray ™ , in the context of VMware, the first few things that come to mind usually are lightning-fast IOPS, sub-1ms latencies, and ease of management. And the best part?
3 Reasons Software Defines the Best All-Flash Array by Pure Storage Blog This article was originally published in 2012. True Enterprise High-availability (HA) By enterprise HA we mean that the storage system has been hardened to support automatic, rapid isolation and recovery from underlying hardware and software faults.
How to Migrate VMware to AWS EC2 by Pure Storage Blog Summary Migrating VMware workloads to AWS EC2 can transform how a business manages its IT infrastructure, offering flexibility, reducing operational costs, and providing scalability. Let’s Go The post How to Migrate VMware to AWS EC2 appeared first on Pure Storage Blog.
It provides built-in automation, highavailability, rolling updates, role-based access control, and more—right out of the box. These include automated capacity management capabilities, data and application disaster recovery, application-aware highavailability, migrations, and backup and restore.
Relational vs. Non-relational Databases by Pure Storage Blog Relational databases and non-relational databases primarily differ in the types of data they store and how that data is organized. Related reading: What is MySQL HighAvailability? The post Relational vs. Non-relational Databases appeared first on Pure Storage Blog.
Organizations of all sizes were generating data that they needed to store on centralized, highly available platforms. Now, everyone wanted shared storage with highavailability and a variety of data-service features. So current PowerStore customers are utilizing RAID 5, which can’t offer that level of availability in my opinion.
A good strategy for resilience will include operating with highavailability and planning for business continuity. AWS recommends a multi-AZ strategy for highavailability and a multi-Region strategy for disaster recovery. In this blog, we are going to focus on how one of our financial services customer implements it.
Architect for highavailability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions. Conduct regular disaster recovery testing Validate business continuity plans through frequent failover simulations and compliance-driven audits.
From Storage to Stream: A Comparison of Leader Election in Portworx, Kafka, and Raft by Pure Storage Blog Summary While Portworx, Kafka, and Raft share the common goal of ensuring smooth operation if there are node failures, they differ when it comes to the leader election process and consensus algorithms.
Hyper-V vs. OpenStack: A Comprehensive Comparison of Virtualization Platforms by Pure Storage Blog Summary Hyper-V is a Type-1 hypervisor developed by Microsoft and known for its seamless integration with Windows environments. Hyper-V supports large VMs with high resource limits (e.g., Supports large VMs (240 vCPUs, 12TB RAM).
VMware vs. OpenStack: Choosing the Right Cloud Management Solution by Pure Storage Blog Summary VMware provides a suite of tools for managing virtualized environments and offers enterprise-level support and reliability. OpenStack is an open source cloud computing platform that offers flexibility and cost savings.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content