This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Pure//Launch Blog October Edition by Pure Storage Blog Summary We’ve been hard at work making enhancements to the Pure Storage platform to augment data protection, help you get more out of your Kubernetes environment, triage issues faster, and more. We’re never finished innovating here at Pure Storage.
Weve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channels original scope, and your readership this last year has proven that decision was the right one. Well, its been another historic year!
However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy. Because of this, you should develop an organizational multi-Region failover strategy that provides the necessary coordination and consistency to make your approach successful.
How Pure Protect //DRaaS Shields Your Business from Natural Disasters by Pure Storage Blog Summary Pure Protect //DRaaS shields your business from the rising threat of natural disasters. Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Downtime Will Cost You: Why DRaaS Is No Longer Optional by Pure Storage Blog Summary Unforeseen disruptions like natural disasters, cyberattacks, or hardware failures can pose a significant threat to companies and their financial and reputational health. Investing in disaster recovery as a service (DRaaS) can help businesses stay resilient.
Automating Disaster Recovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disaster recovery can offer many advantages for organizations. Customers only pay for resources when needed, such as during a failover or DR testing.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community.
This blog post shows how to architect for disaster recovery (DR) , which is the process of preparing for and recovering from a disaster. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. All requests are now switched to be routed there in a process called “failover.”
It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. . First, it can synchronously replicate at the memory layer, so, in the event of a failover, there’s no waiting for memory loads to happen before the system can be considered up.
Read more about the performance and functionality of EDA tools running in Azure VM with data hosted on FlashBlade ® in an Equinix location in the blog post, Scaling Software Builds in Azure with FlashBlade in a Cloud-Adjacent Architecture . The failover and failback capabilities can also be achieved using Ansible playbooks.
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. Fan-in deduplicates data across source arrays before sending it to the target, maximizing your storage efficiency.
Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover. The steps are either pre-action or post-action and can be either manual action or a script to execute steps during a failover. Add Orchestration for Your DR Plan. Next, the assigned post-action automation runbook will be prompted.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. When you are structuring your DR plan, consider creating isolated networks specifically for failover testing. This includes updating the escalation plan and contact lists.
In a previous blog post on business continuity and disaster recovery (DR), we shared how the City of New Orleans adopted ActiveDR™ for their DR requirements and realized impactful business results through its simplicity and innovation. The post Rethinking Disaster Recovery with Simplicity Part 1 of 3 appeared first on Pure Storage Blog.
And it allows you to test failover without disrupting applications or workloads, increasing your confidence in new protection mechanisms that have no effect on your existing, continual replication. Now it’s simple to set up an entire disaster recovery plan and enable single-click failover.
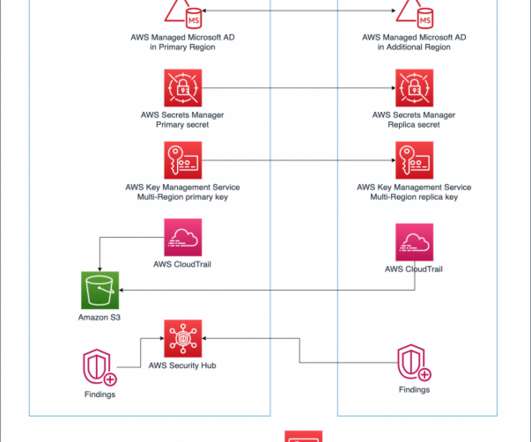
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1,
At the end of November, I blogged about the need for disaster recovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. I covered this topic in more detail in my last blog post , but the highlights bear repeating in light of these recent outages. How Safe is the Cloud? It’s Complicated .
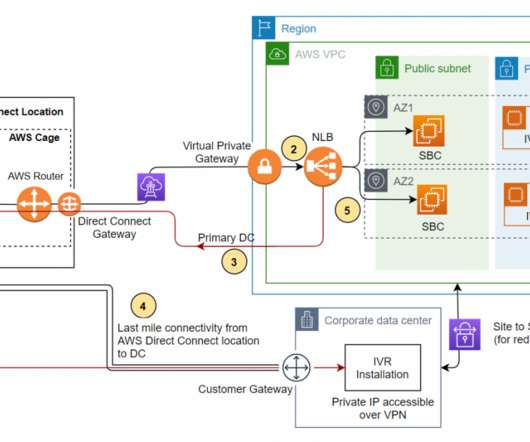
Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. Load balancing across AWS and on-premises resources using the same load balancer streamlines migrate-to-cloud, burst-to-cloud, or failover-to-cloud. Conclusion.
You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. The post Delivering Multicloud Agility with Software-defined Storage appeared first on Pure Storage Blog. Visit the Azure Marketplace to learn more.
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Disaster Recovery Architecture on AWS blog series. Related posts.
In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. If a larger failure occurs, the Route 53 Application Recovery Controller can simplify the monitoring and failover process for application failures across Regions, AZs, and on-premises. Ready to get started?
In this blog post, we’ll explore key considerations to help you make an informed decision when selecting a DRaaS provider. Zerto runs failover, dev , and other QA tests at any time without production impact, ensuring aggressive SLAs are met. Non-disruptive testing.
When designing a Disaster Recovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. Scenario 1: Full Replication Failover. You take the on-premises Active Directory, and failover to another Region. Walkthrough. Prerequisites. Walkthrough.
Introducing Pure Protect //Disaster Recovery as a Service (DRaaS) by Pure Storage Blog In today’s unpredictable world, natural disasters are ramping up in both frequency and intensity. The plan typically includes regular backups both on-site and off-site, redundant hardware for high availability (HA), and failover systems.
ZTNA vs. VPN by Pure Storage Blog Summary As data breaches become more common, organizations need a better way to protect their data. Protect Your Data The post ZTNA vs. VPN appeared first on Pure Storage Blog.
Move to Pure: The Last Storage vMotion You’ll Ever Need to Do by Pure Storage Blog Back to Las Vegas! Not just the data, but the state, configurations, metadata and key application coordination to ensure successful migration, failover, and recovery. Tightly integrated backup and restore, disaster recovery, and more. NVMe-oF), VASA 5.0
Top 8 VMware Alternatives by Blog Home Summary Virtualization software is a powerful tool that can help businesses increase efficiency, reduce costs, and improve resource utilization. OpenShift also works with containers , has built-in security, and has data storage failover across multiple disks.
Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources.
Leveraging Pure Protect //DRaaS for Cybersecurity: The Role of Clean Rooms in Forensic Investigations by Blog Home Summary As cyber threats increase, having a robust disaster recovery solution is essential. Seamless Integration with Pure Protect //DRaaS 5.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). The event-driven serverless architecture performs failover by updating the weights of the Route 53 record. Fail over with event-driven serverless architecture.
The Storage Architecture Spectrum: Why “Shared-nothing” Means Nothing by Pure Storage Blog This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive.
Every write action causes degradation on the drive, so it will eventually fail, making it important to have failover and backups. They can be mirrored for failover and used to store as much data as you store on an SSD in case of a disaster. appeared first on Pure Storage Blog. Another disadvantage is degradation.
DXC Technology: Turning Ideas into Real Business Impact by Blog Home Summary When this leading technology services provider needed a robust disaster recovery (DR) solution for its Managed Container Services platform, DXC Technology chose Portworx by Pure Storage.
by Pure Storage Blog Summary When reconsidering their VM strategies, many organizations might overlook the fact that legacy data storage could be making their VM problems worse. appeared first on Pure Storage Blog. Are You Treating the Symptoms of Your VM Pain, or Curing the Cause?
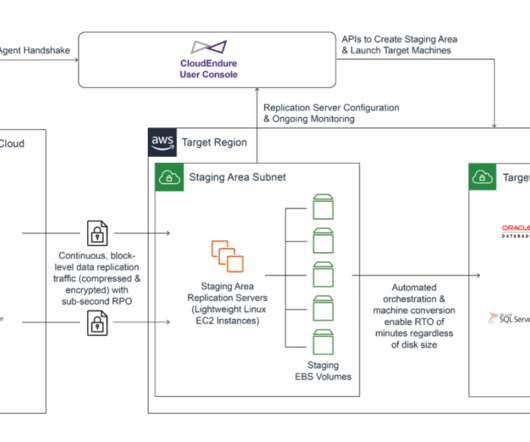
This final blog post in the one-to-many replication series will discuss how to leverage Zerto, a Hewlett Packard Enterprise company, to protect and migrate on-premises VMs to EC2 instances with one-to-many replication. Learn all about it in this blog series. Take the plunge into Zerto In-Cloud for AWS.
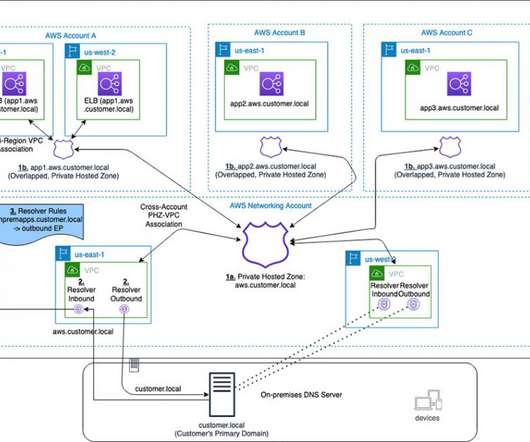
This blog presents an architecture that provides a unified view of the DNS while allowing different AWS accounts to manage subdomains. Failover routing policy is set up in the PHZ and failover records are created. In order to handle the DR, here are some other considerations: For app1.aws.customer.local, Considerations.
In this blog post, we’ll explore how to effectively and efficiently migrate to the cloud using Zerto. Have a look at the Six Common Challenges to Migration Projects and Tips to Overcome Them blog post and review this Migration Checklist to get a sense of all the steps involved. Still not convinced?
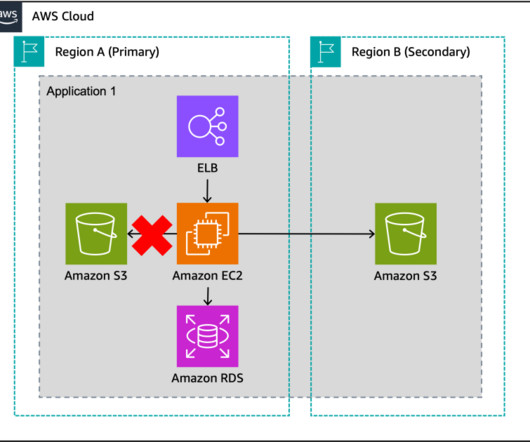
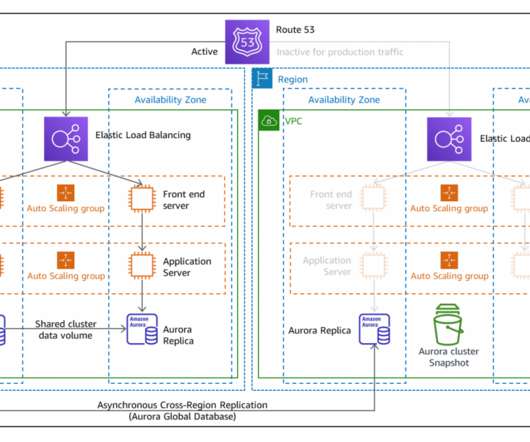
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover.
This blog post will focus on the use of two or more Pure Cloud Block Store instances in different Microsoft Azure availability zones or regions to achieve cost-effective disaster recovery for Microsoft SQL Server instances. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
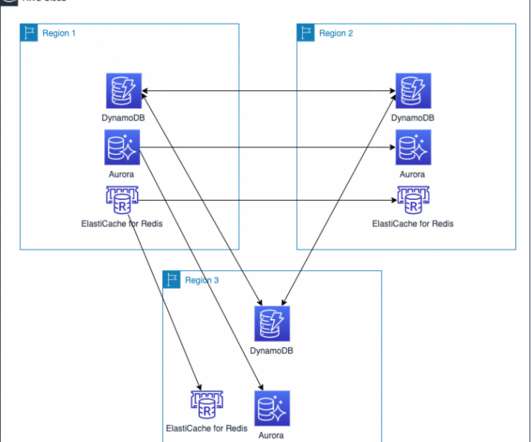
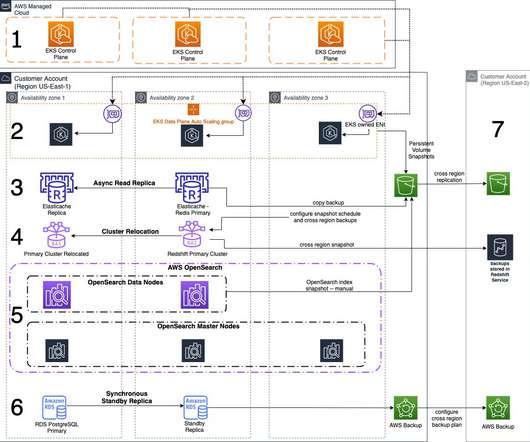
This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. The strategy outlined in this blog post addresses how to integrate AWS managed services into a single-Region DR strategy. Amazon RDS PostgreSQL.
In the previous blog, “The Benefits of One-to-Many Replication,” we provided an overview of Zerto’s one-to-many replication feature. Read more about the failover and move operations using one-to-many with Zerto. Summary Zerto’s one-to-many replication feature adds layers of recoverability to your disaster recovery strategy.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content