This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Pure//Launch Blog October Edition by Pure Storage Blog Summary We’ve been hard at work making enhancements to the Pure Storage platform to augment data protection, help you get more out of your Kubernetes environment, triage issues faster, and more. We’re never finished innovating here at Pure Storage.
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. FlashArray//C is designed to address operational workload requirements. Learn more about FlashArray.
Automating Disaster Recovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disaster recovery can offer many advantages for organizations. Customers only pay for resources when needed, such as during a failover or DR testing.
HDD devices are slower, but they have a large storage capacity. Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. Traditionally, the biggest disadvantages of an SSD have been price, degradation, and capacity. SSD devices are faster, but they also cost more.
by Pure Storage Blog Summary When reconsidering their VM strategies, many organizations might overlook the fact that legacy data storage could be making their VM problems worse. Constantly Running Out of Capacity Symptom: Were always scrambling for more storage space, and adding capacity is expensive and disruptive.
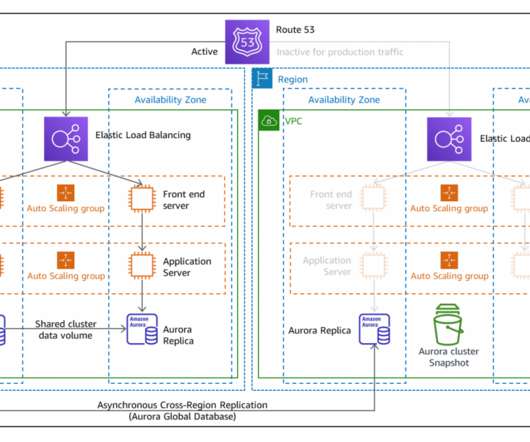
This blog post shows how to architect for disaster recovery (DR) , which is the process of preparing for and recovering from a disaster. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. All requests are now switched to be routed there in a process called “failover.”
The Storage Architecture Spectrum: Why “Shared-nothing” Means Nothing by Pure Storage Blog This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . This blog post will focus on the use of two or more Pure Cloud Block Store instances in different Microsoft Azure availability zones or regions to achieve cost-effective disaster recovery for Microsoft SQL Server instances. .
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. You also have thin provisioning, dedupe, and compression.
Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources.
This final blog post in the one-to-many replication series will discuss how to leverage Zerto, a Hewlett Packard Enterprise company, to protect and migrate on-premises VMs to EC2 instances with one-to-many replication. Using AWS as a DR site also saves costs, as you only pay for what you use with limitless burst capacity.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Amazon RDS database.
Bogus Statements) by Pure Storage Blog (For the purposes of this post, “B.S.” Resource Balancer only uses capacity-free space to determine where to place the new volume.¹³ This is why PowerStore can support different models with different capacities in the same “cluster,” because data is located only on one appliance at a time.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover.
This blog is an update from a popular blog authored by Damon Edwards. . semi-manual deployments, schema updates/rollbacks, changing storage quotas, network changes, user adds, adding capacity, DNS changes, service failover). For the organization, high-levels of toil lead to: Shortages of team capacity.
In part 2 of our three-part cloud data security blog series, we discussed the issue of complexity. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover. The post Cloud Data Security Challenges, Part 3: Getting Control appeared first on Pure Storage Blog.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. During failover, scale up resources and increase traffic to the Region. This pattern works well for applications that must respond quickly but don’t need immediate full capacity.
These two technologies work together to give you backup solutions and provide failover if a single drive fails. If you decide to build a backup solution for your network with potentially petabytes of storage capacity, a NAS is an array of drives that work together to store data. What Does a NAS RAID Mean? Benefits of RAID and NAS.
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
How to Accelerate MySQL Workloads by Pure Storage Blog This article on MySQL Workloads was coauthored by Andrew Sillifant and Nihal Mirashi. In a previous blog post, I covered 4 common MySQL issues and how to solve them. Single-command failover. The post How to Accelerate MySQL Workloads appeared first on Pure Storage Blog.
When most storage vendors talk about non-disruptive upgrade (NDU) they’re focusing on software upgrades, or adding storage capacity to an existing storage array. Pairing the FlashArray’s architecture with the Purity operating environment, which handles dynamic controller failovers, allows the controllers to be completely transparent.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 1 of 4 by Pure Storage Blog In this four-part series, I’ll explore using ActiveDR ™ for managing Oracle disaster recovery. Part 4 will show how to use this for real DR failover scenarios and subsequent failbacks.
Winner for APJ by Pure Storage Blog From the family-friendly Qashqai SUV to the all-electric Leaf compact, Nissan Australia has a mobility solution for every Australian. With Pure Evergreen//Forever ™, Nissan Australia can continuously scale its capacity and upgrade its arrays with zero disruption to its operations. “I
Pure Storage with VMware Integrations: Get the Most Out of Your Storage by Pure Storage Blog When folks think about Pure Storage, and more specifically, Pure Storage ® FlashArray ™ , in the context of VMware, the first few things that come to mind usually are lightning-fast IOPS, sub-1ms latencies, and ease of management. And the best part?
Yourself through Pure1 by Pure Storage Blog I’m happy to announce the release of Purity//FA 6.5.0. Support and Ransomware Protection Enhancements blog Auto-on SafeMode™ blog Purity//FA 6.4.9: Cloud Archival Option, Wasabi Support, and More blog Purity//FA 6.4.7: Upgrade to Purity//FA 6.5.0 Purity//FA 6.5.0 Purity//FA 6.4
Delivering Low-latency Analytics Products for Business Success by Pure Storage Blog This article on low-latency analytics initially appeared on Kirk Borne’s LinkedIn. It has been republished with the author’s credit and consent. All of these system capabilities, which are made available through Pure Storage, have arrived just in time.
Btrfs vs. ZFS by Pure Storage Blog With any new Linux server build, administrators need to determine the file system that supports fault tolerance without negatively impacting performance. More complex systems requiring better performance and storage capacity might be better using the ZFS file system. What Is Btrfs?
3 Reasons Software Defines the Best All-Flash Array by Pure Storage Blog This article was originally published in 2012. HA cannot be left as a homework exercise: Requiring a customer to buy two machines and then figure out how to configure failover, resync and failback policies is not what we mean by HA. It is self-healing.
Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. These include automated capacity management capabilities, data and application disaster recovery, application-aware high availability, migrations, and backup and restore. This is where Portworx comes in.
How to Migrate VMware to AWS EC2 by Pure Storage Blog Summary Migrating VMware workloads to AWS EC2 can transform how a business manages its IT infrastructure, offering flexibility, reducing operational costs, and providing scalability. Let’s Go The post How to Migrate VMware to AWS EC2 appeared first on Pure Storage Blog.
Using Docker, you can take advantage of your full compute capacity. . Enterprise-grade resiliency with automated failover and self-healing data access integrity. The post Docker vs. Kubernetes appeared first on Pure Storage Blog. Advantages of Kubernetes. Policy-based provisioning.
Later generations of Symmetrix were even bigger and supported more drives with more capacity, more data features, and better resiliency. . Today, Pure1 can help any type of administrator manage Pure products while providing VM-level and array-level analytics for performance and capacity planning. HP even shot its array with a.308
IT’s 4 Biggest Risks and How to Build Resilience against Them by Pure Storage Blog IT departments face risks and challenges on a daily basis—not all of which are necessarily within their ultimate control. That’s why “ resiliency ,” the capacity to withstand or recover quickly from difficulties, is key. Things will go wrong.
Relational vs. Non-relational Databases by Pure Storage Blog Relational databases and non-relational databases primarily differ in the types of data they store and how that data is organized. The post Relational vs. Non-relational Databases appeared first on Pure Storage Blog. Built-in replication.
Moreover, the ability to scale storage on demand ensures it can migrate and modernize its legacy systems quickly while reducing storage costs, both in terms of capacity and upgrades. Failover processes became a priority for the bank after one team had to manually fail over 4,000 virtual machines in a single weekend.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content