This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before you know it, your fleet has become a many-headed monster of disparate storage arrays, with siloed data and a complex web of backup jobs. Fan-in unifies backup tasks, replication jobs, and access control under one roof, streamlining your workflow. Enter your knight in shining armor—snapshot consolidation via fan-in replication.
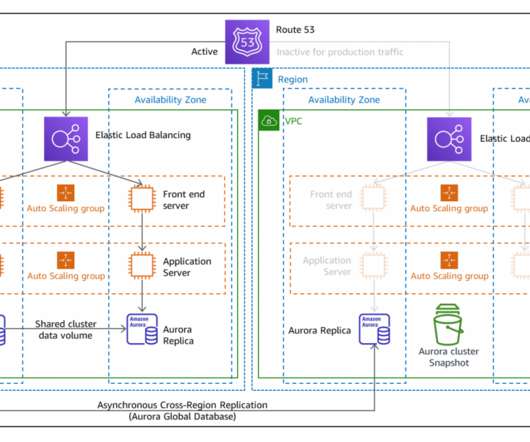
In part two, we introduce a multi-Region backup and restore approach. Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward. Want to see it for yourself?
HDD devices are slower, but they have a large storage capacity. Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. SSDs aren’t typically used for long-term backups, so they’re built for both but are typically used in speed-driven applications.
Constantly Running Out of Capacity Symptom: Were always scrambling for more storage space, and adding capacity is expensive and disruptive. Root Cause: Some IT teams try to address performance and capacity issues by spinning up more VMs or increasing allocated resources per VM, leading to inefficiencies.
All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. If data needs to be restored from backup, this can increase the recovery point (and data loss).
Having a robust data protection and recovery strategy based on backup and recovery is the first step toward ensuring IT resilience. This can be achieved via periodic backups of data and applications to offsite storage to allow for fast recovery. How Do You Ensure IT Resilience?
Acronis provides backup, disaster recovery, and secure access solutions. The provider’s flagship product, Acronis True Image, delivers backup, storage, and restoration capabilities. Acronis ’ Disaster Recovery as a Service ( DRaaS ) solutions address IT requirements for backup, disaster recovery, and archiving.
Acronis provides backup, disaster recovery, and secure access solutions. The provider’s flagship product, Acronis True Image, delivers backup, storage, and restoration capabilities. Acronis ’ Disaster Recovery as a Service ( DRaaS ) solutions address IT requirements for backup, disaster recovery, and archiving.
A great way to make sure it’s protected no matter what happens is through solutions like Pure Storage ® SafeMode ™, a high-performance data protection solution built into FlashArray™ that provides secure backup of all data. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Amazon RDS database.
Then we explored the backup and restore strategy. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover. In addition to replication, both strategies require you to create a continuous backup in the recovery Region. Pilot light DR strategy.
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts. You also have thin provisioning, dedupe, and compression.
When you’re looking into backup and storage options, you’ll come across a redundant array of independent disks (RAID) and network attached storage (NAS). These two technologies work together to give you backup solutions and provide failover if a single drive fails. What Does a NAS RAID Mean? Benefits of RAID and NAS.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward. Want to see it for yourself?
Backup solutions like database and Amazon S3 replication can provide RPO of a few minutes at most, but RTO will vary considerably. Backup and restore (Tier 4). This pattern may incur more data loss depending on backup schedules. During failover, scale up resources and increase traffic to the Region. Pilot light (Tier 2).
With business growth and changes in compute infrastructures, power equipment and capacities can become out of alignment, exposing your business to huge risk. Business continuity best practices suggest that backup sites be built at physically different locations, in different seismic zones.
Minimum business continuity for failover. Earlier, we were able to restore from the backup but wanted to improve availability further. We built a pilot light using point-in-time backups for data stores, cross-Region Amazon RDS read replicas , cross-Region Amazon S3 replication , and AWS CloudFormation templates.
Over time, these plans can be expanded as resources, capacity, and business functionality increase. RTOs and RPOs guide the rest of the DR planning process as well as the choice of recovery technologies, failover options, and data backup platforms. This makes RTO and RPO calculations a key part of the DR planning process.
And it has the protective benefits of specialized cluster servers and regular backups to separate nodes or data centers. A basic approach is to use simple backups. Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations. Single-command failover.
To counteract this challenge, Nissan Australia runs its manufacturing workloads on VMware in an active-active configuration across two data centers that leverage Pure Storage® FlashArray//X ™ with ActiveCluster ™ for seamless failovers. FlashBlade has also allowed Nissan Australia to consolidate its mainframe backups.
More complex systems requiring better performance and storage capacity might be better using the ZFS file system. Using Btrfs, administrators can offer fault tolerance and failover should a copy of a saved file get corrupted. Btrfs and ZFS are the two main systems to choose from when you partition your disks. What Is Btrfs?
Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. These include automated capacity management capabilities, data and application disaster recovery, application-aware high availability, migrations, and backup and restore.
This means that organizations can avoid overprovisioning and underutilization of resources, paying only for the capacity they need when they need it. The cloud provider offers a range of tools for data backup, failover, and recovery, minimizing risks associated with data loss and downtime.
That’s why “ resiliency ,” the capacity to withstand or recover quickly from difficulties, is key. How to Build Resilience against the Risks of Operational Complexity Mitigation: Adopt a well-defined cloud strategy that accounts for redundancy and failover mechanisms. Things will go wrong.
Companies will spend more on DR in 2022 and look for more flexible deployment options for DR protection, such as replicating on-premises workloads to the cloud for DR, or multinode failover clustering across cloud availability zones and regions.” “Simple backup of data storage is no longer sufficient.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content