This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy. Because of this, you should develop an organizational multi-Region failover strategy that provides the necessary coordination and consistency to make your approach successful.
To maintain a business continuity plan, which goes beyond layered threat detection, here are seven strategies your IT team can implement immediately to ensure you have a healthy, immediate failover once a malicious infiltration has occurred. Automated Recovery Testing Gone are the days of manual backup testing.
A zero trust network architecture (ZTNA) and a virtual private network (VPN) are two different solutions for user authentication and authorization. After users authenticate with the VPN system, they’re allowed to access any area of the network provided the user is a part of an authorized group.
Episode Summary: Shane interviews business continuity industry disruptors- Dr. David Lindstedt and Mark Armour- authors of "Adaptive Business Continuity: A New Approach" and creators of the Adaptive Business Continuity movement which started in 2015. Guest Bios: Dr. David Lindstedt is a speaker, author, and champion for business continuity.
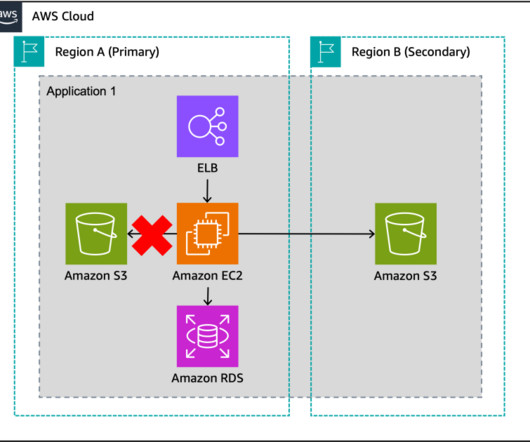
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Episode Summary: Shane continues the discussion with business continuity industry disruptors- Dr. David Lindstedt and Mark Armour- authors of "Adaptive Business Continuity: A New Approach" and creators of the Adaptive Business Continuity movement which started in 2015. 18:16min- Characteristics of those that shift to ABC today. Website. .
His writing led to becoming a self published author of "BlueyedBC – Business Continuity for Junior Professionals" and most recently, becoming elected as a Director to the Business Continuity Institute’s Global Board. And we’re going to talk with him about how he developed a personal brand within our field.
Guest Bios: Dr. David Lindstedt is a speaker, author, and champion for business continuity. Along with Mark Armour he founded AdaptiveBCP.org and authored Adaptive Business Continuity: A New Approach. He is the founder of Adaptive BC Solutions (AdaptiveBCS.com) and creator of three BC software systems.
Creating a security foundation starts with proper authentication, authorization, and accounting to implement the principle of least privilege. If a larger failure occurs, the Route 53 Application Recovery Controller can simplify the monitoring and failover process for application failures across Regions, AZs, and on-premises.
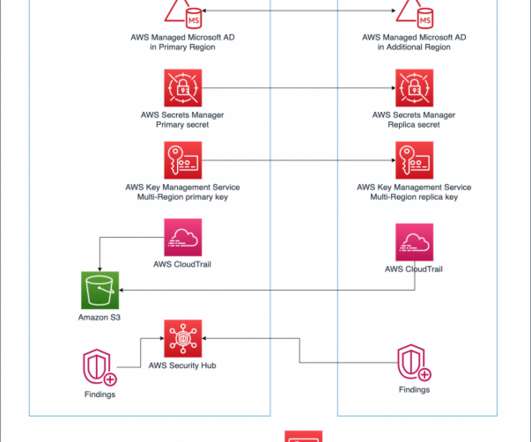
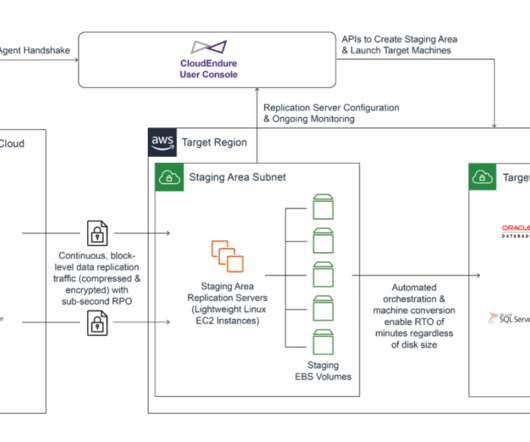
Co-authored by Daniel Covey, Solutions Architect, at CloudEndure, an AWS Company and Luis Molina, Senior Cloud Architect at AWS. When designing a Disaster Recovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. Scenario 1: Full Replication Failover.
In my spare time, I co-author practices in IT supplier management (SIAM) and a digital ITSM (VeriSM), speak at conferences and webinars, facilitate discussions in organizations on technology and enjoy waling the UK with my wife and dog.
Guest Bio: Cyril Moulin Fournier is a facilitator, consultant in management of change, keynote speaker and author. In both of these perspectives, they learned lessons about personal and professional crisis response that are incredibly insightful.
As an example, you should always require security verification (authentication and authorization controls) for downloads to and from unsecured devices. . PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover. Create good technical controls.
Our editors selected the best business continuity software based on each solution’s Authority Score; a meta-analysis of real user sentiment through the web’s most trusted business software review sites and our own proprietary five-point inclusion criteria. Recovery testing can be fully automated or performed on a scheduled basis.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Some things to consider for these incidents: Decide when or if your team should call a deploy freeze, and who will have the authority to make that decision, including executive-level support.
Our editors selected the best Data Protection Software based on each platform’s Authority Score, a meta-analysis of real user sentiment through the web’s most trusted business software review sites, and our own proprietary five-point inclusion criteria.
This blog is an update from a popular blog authored by Damon Edwards. . semi-manual deployments, schema updates/rollbacks, changing storage quotas, network changes, user adds, adding capacity, DNS changes, service failover). The SRE movement calls this type of work “toil.”.
So, what better time than early April for a group of operational resilience professionals to gather in London to analyze the recent changes in the world of resilience: the increase in high probability, high impact events; how we are seeing regulatory focuses shift; and how we are preparing for the future state of resilience programs?
Automated reporting : PagerDuty includes a suite of out-of-the-box dashboards and analytical reports but also allows for integration with external systems, potentially enabling automated reporting of major incidents to the relevant authorities based on predefined criteria.
Only certain members of leadership have the authority to initiate the business continuity plan, and it is regarded with the utmost seriousness if it is enacted. There are many solutions that also allow for an entire technology environment to be “spun up” in the cloud—referred to as failover—in the case of an onsite disaster.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Some things to consider for these incidents: Decide when or if your team should call a deploy freeze, and who will have the authority to make that decision, including executive-level support.
It’s important to do full failover and recovery whenever possible so that you truly can understand the nuances you may face in a real situation. Getting a copy of your data is often the easy part, but building an effective program to address all the other aspects of data continuity is where a lot of the work happens.
Define Your DR Playbook: Document detailed disaster recovery runbooks that outline procedures for failover and failback, escalation paths, key points of contact, testing schedules, and performance metrics. According to Gartner, only 23% of organizations regularly test their DR plans, significantly impacting their preparedness.
Businesses that go beyond the 3-2-1 framework by implementing immutability, isolation, and rapid failover solutions are the ones that stay operational, no matter the disruption. With immutable storage, automated testing, real-time threat detection, and rapid failover, we help businesses stay operationalno matter what.
Architect for high availability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions. Conduct regular disaster recovery testing Validate business continuity plans through frequent failover simulations and compliance-driven audits.
It has been republished with the authors credit and consent. This is a fair question, as its fairly rare (in my experience) to run a standalone SQL instance in productionmost instances are in some form of HA setup, be it a failover cluster instance or an availability group.
To maintain a business continuity plan that goes beyond layered threat detection, here are seven strategies your IT team can implement immediately to ensure you have a healthy, immediate failover once a malicious infiltration has occurred. Automated Recovery Testing Gone are the days of manual backup testing.
Disaster recovery and backup: Hyper-V supports live migration, replication, and failover clustering, making it a popular choice for business continuity and disaster recovery solutions. To scale out, Hyper-V uses failover clustering, which allows multiple physical hosts to be grouped together in a cluster.
Identity management: Keystone is OpenStack’s identity service, which handles authentication, authorization, and service discovery. OpenStack’s Keystone service is responsible for authentication, authorization, and identity management.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content