This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Redundancy ensures resilience by maintaining connectivity during outages. Data Protection and Recovery Architecture Why It Matters: Data loss during a disaster disrupts operations, damages reputations, and may lead to regulatory penalties. Are advanced security measures like zero trust architecture in place?
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other other localized disruptions, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need. Architecture of the DR strategies. Backup and restore DR architecture. Pilot light DR architecture.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
This and other security controls are aspects of zero trust architectures , which should be looked at as a journey, not a destination. The backbone of cyber resilience comes from a foundation: a data-resilient security architecture deeply integrated with tech partners who can uphold the latest standards and frameworks. Let’s dig in.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Due to its monolithic architecture, the application didn’t scale quickly with sudden increases in traffic because of its high bootstrap time. Predictive scaling for EC2.
One Pure Storage customer has done this to their original FlashArray FA-420 purchased in 2013 to include their controllers, bus architectures, and DirectFlash® Modules (DFMs) to become a FlashArray//X70 R3. This will present a system stability problem in an unexpected component outage because critical data will be lost.
Using multiple Regions ensures resiliency in the most serious, widespread outages. Architecture overview. In our architecture, we use CloudWatch alarms to automate notifications of changes in health status. Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery. OpenSearch Service.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. Moreover, cloud-services providers are themselves susceptible to outages and failed recoveries.
Benefit: Maintains cloud infrastructure consistency, minimizing the risk of configuration drift, which can lead to unexpected outages or security vulnerabilities. Benefit: Ensures uninterrupted, secure communication and prevents service outages due to expired SSL certificates, safeguarding customer trust and service reliability.
Though ransomware has dominated conversations in the data protection sphere for quite some time, stories of recent outages due to this threat still circulate. The conversation delved into the technical design aspects of the vault, its architecture, and the rationale behind crucial decisions.
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. If not, a single controller failure could cause a data outage or corruption.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or application outages.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Business Data Loss and Corruption. Data Loss and Corruption. In-place Surgical Data Fix.
It helps keep your multi-tier applications running during planned and unplanned IT outages. For those organizations that choose to migrate and run their mission-critical applications on the cloud, Pure Cloud Block Store ™ offers built-in protection against outages of availability zones, regions, and even clouds.
Remember, after an outage, every minute counts…. Jointly architectured by two of the industry’s most trusted companies, FlashRecover//S is designed specifically to deliver a powerful yet easy-to-use solution with multiple levels of built-in ransomware protection that can provide petabyte-scale recovery of data in just hours. .
Flexibility gives you the confidence to recover when needed, whether its during planned migrations or unplanned outages. With Zerto, youre not confined by rigid architectures, vendor lock-in, or outdated solutions. Anytime Disasters dont wait for a convenient time, and neither should your recovery.
As you review the key objectives and recommendations, ask yourself: Is my security architecture resilient? Those investments add up to one concept: a tiered resiliency architecture. A three-tiered resiliency architecture can protect your entire data estate, which I outlined how to do do this in this article.
Effective failover methods must include independent, automated channels (online and offline) for both notifications and critical data access, and a distributed system architecture, integrated with backup systems and tools. Take the next step toward true operational resilience. Or, get hands on and sign up for a free trial today.
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
An IT outage of any sort can adversely impact people’s lives. Scalability and Performance: Zerto’s architecture is designed to scale and perform efficiently, even in large and complex environments. Zerto’s journal-based recovery approach provides an added layer of protection against ransomware threats.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object.
Will That Cause an Outage? A modern cloud-like storage service should never require “planned downtime” or require outage windows to perform routine software, hardware upgrades and maintenance. Our Evergreen architecture already eliminates the industry’s traditional method of upgrading storage by replacing and junking existing systems.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. This architecture also helps customers to comply with various data sovereignty regulations in a given country. Architecture Overview. Architecture Walkthrough.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
The new multi-VRA architecture scales out protection for VMs in Azure rather than using multiple ZCAs. Zerto for Azure Architecture Enhanced scalability enables protection of up to 5000 VMs to, from, or within Azure. This means that users can now have multiple VRAs for enhanced replication and recovery capabilities.
The New Resilience Imperative: Tiered Storage Architectures A tiered data storage architecture assumes at least one system is going to be compromised and builds in layers of safety to protect the other parts of that system, or other systems, from also getting compromised.
Service outages ultimately frustrate customers, leading to churn and loss of trust. Zero trust architecture ensures a “never trust, always verify” approach to limit access and minimize potential damage from breaches. Reputational Damage Even if businesses recover financially, their reputation may suffer long-term damage.
In Part II, we’ll explore the technical considerations related to architecture and patterns. It’s also sometimes mixed with concerns about highly publicized security or outage events. Like other architecture attributes, resilience is measured on a scale (that is, a degree to which a system is resilient). Architecture reviews.
Outages can also become more complex in the cloud, with hundreds of services all being interconnected and dependent on each other. Ensure everyone has complete visibility and clear ownership across your technical and business services as you shift to a microservices architecture. PagerDuty + AWS .
They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. The system can quickly detect outages and report them to the utility, leading to faster restoration of services. Customers are also informed about the state of outages in real time.
The recent global outage reminds us that identifying issues and their impact radius is just the first part of a lengthy process to remediation. See the diagram below for a sample architecture. Incidents are inevitable; how we prepare for and learn from them is what sets teams up to respond more effectively next time.
An active-active cluster architecture is actively running the same service simultaneously on two or more nodes. While this architecture can ensure that the application is always online, it comes at a cost. In doing so, an application can serve multiple clients access by load balancing.
However, because setting it up involves rebuilding much of the organization’s network security architecture, implementing it is a serious burden and a major project, one that typically takes multiple years. Once it’s in place, Zero Trust is highly secure and very convenient.
Consider engaging in a discussion with the CISO about the benefits of tiered security architectures and “ data bunkers ,” which can help retain large amounts of data and make it available immediately. Understand what the restore process looks like, what will be manual, and how long it could take.
But even internally, an outage can be disastrous. The city had to spend $10 million on recovery efforts, not including the $8M in lost revenue from a two-week outage of bill payment systems and real estate transactions. Learn how a tiered backup architecture with a data bunker can set your recovery efforts up for success. .
As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. Both dependencies might violate static stability, because we are relying on resources in our DR plan that might be affected by the outage we’re seeing.
The largest hyperscale clouds have a highly redundant architecture that copies data in multiple places throughout its infrastructure. After all, while cloud outages aren’t very common, they do occur. Microsoft Azure, March 2020: Azure experienced a six-hour outage in the Eastern U.S. The cloud certainly has a lot going for it.
This means higher costs for rack space overages with potential service outages. FlashBlade’s architecture accelerates everything in the EDA workflow: time-to-design, time-to-test, time-to-market, while at the lowest energy cost per TB in the industry. AI-based workflows push the limits of traditional data center infrastructure designs.
If there are any issues with the fulfillment of our performance or capacity obligations, you can trust Pure to resolve this with our best-in-class NPS score of 83+ and our Evergreen™ and Evergreen architecture. We provide the ability to schedule these upgrades through Pure1 at a time convenient to you. That’s outlined in our terms as: .
Second is a disturbing trend of late: targeting essential service providers that lead to massive outages and widespread disruptions. Learn more about how to design an airtight, hyper-accessible, and secure data backup architecture with Pure SafeMode snapshots. Hackers are preying on the urgency to get back online.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object.
When we build our monitors and corresponding alerts, we are usually doing so with the service in question in mind but we can’t always effectively map how dependencies will respond to each other’s latencies and outages. When we think about how we configure alerts, how we end up in those situations on the response side starts to make sense.
The process of indexing the data (merging the data, in particular) is quite computationally expensive on the Elasticsearch cluster and running it at a rate to repopulate large amounts of data will likely affect other indices on the cluster that may be running queries at the same time (if they were unaffected by the outage).
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























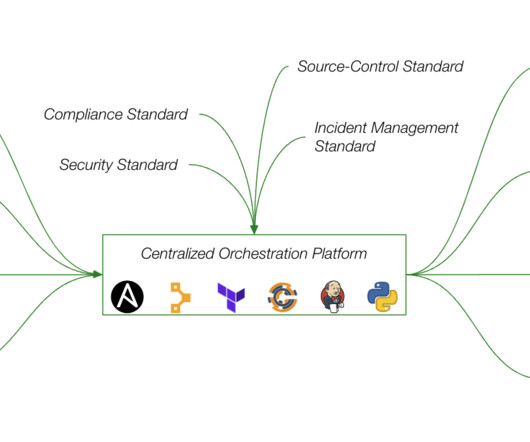


















Let's personalize your content