This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Redundancy ensures resilience by maintaining connectivity during outages. BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. How to Achieve It: Implement multi-layered security with firewalls, intrusion prevention systems, zero trust architecture, and encryption.
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other other localized disruptions, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need. All requests are now switched to be routed there in a process called “failover.” Multi-Region strategy.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. Production outages are scary for everyone, but with the right system monitoring solution, they can be made less stressful.
It helps keep your multi-tier applications running during planned and unplanned IT outages. For those organizations that choose to migrate and run their mission-critical applications on the cloud, Pure Cloud Block Store ™ offers built-in protection against outages of availability zones, regions, and even clouds.
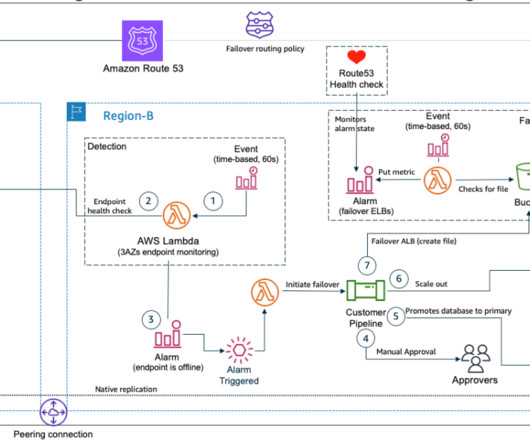
Using multiple Regions ensures resiliency in the most serious, widespread outages. Architecture overview. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Learn more about the PagerDuty Operations Cloud platform and how we can help teams like yours stay ahead of outages by taking this product tour.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
An IT outage of any sort can adversely impact people’s lives. With Zerto, state, local, and education entities can easily create and manage recovery plans, perform non-disruptive testing, and streamline the failover/failback processes.
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. If not, a single controller failure could cause a data outage or corruption.
The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes.
As more enterprises adopt containers and Kubernetes architectures for their applications, the reliance on microservices requires a solid data protection strategy. In the event of an outage due to a ransomware attack completely taking your primary site down, Zerto for Kubernetes helps users fight back by performing a failover live operation.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy.
Zerto for Azure stands out as an exceptional choice as a scalable DR solution that provides seamless failovers and migrations to, from, and within the Azure cloud environment. The new multi-VRA architecture scales out protection for VMs in Azure rather than using multiple ZCAs.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. Combined with the container-level backup capabilities of PX-Backup, customers now have a way to quickly recover their containerized workloads in case of outages.
While competing solutions start the recovery process only after AD goes down, Guardian Active Directory Forest Recovery does it all before an AD outage happens. This helps minimize downtime in the event of outages or cyberattacks. Read on for more SIOS Unveils LifeKeeper for Linux 9.9.0
Pulling myself out of bed and rolling into the office at 8am on a Saturday morning knowing I was in for a full day of complex failover testing to tick the regulator’s box was a bad start to the weekend. So let’s get started and take a look at a logical architecture diagram of what we’re about to build.
IT organizations have mainly focused on physical disaster recovery - how easily can we failover to our DR site if our primary site is unavailable. While this does require tooling and support in both Cloud Operations and Cybersecurity, it provides resiliency protection against outages fully taking down entire operations.
According to the Veeam Data Protection Report 2021 , the average hourly toll of downtime is $84,650, the typical outage taking around 79 minutes to resolve. An IT pro might do a failover or two in their entire career – we handle multiple ones on a monthly basis. Why the need for disaster recovery specialists? There’s cost.
Pure offers additional architectural guidance and best practices for deploying MySQL workloads on VMware in the new guide, “ Running MySQL Workloads on VMware vSphere with FlashArray Storage.” Single-command failover. This component determines which array will continue data services should a power outage occur.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Learn more about the PagerDuty Operations Cloud platform and how we can help teams like yours stay ahead of outages by taking this product tour.
When a hurricane leads to widespread power outages, flooding, and workforce disruption, for example, an effective disaster recovery plan ensures that IT systems remain up and running and that operations can come back online as soon as possible. The primary objective is a rapid return to normalcy while minimizing losses.
When a regional storm makes travel difficult and causes short-term power outages, for example, an effective business continuity plan will have already laid out the potential impact, measures to mitigate associated problems, and a strategy for communicating with employees, vendors, customers, and other stakeholders.
It’s important to do full failover and recovery whenever possible so that you truly can understand the nuances you may face in a real situation. Securing your data is just the start: once you have a data protection strategy in place, it’s critical to consider recovery of that data should any disruption, outage, or cyber-attack occur.
NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases high availability but also failover and fault tolerance in the event of a failure or outage. Built-in replication. Sharding, which improves scalability and load balancing.
These examples illustrate how AI can play a crucial role in enhancing IT disaster recovery by automating processes, optimizing resource allocation, and preemptively calling for maintenance and repair to prevent outages improving overall resilience in the face of technological disruptions.
Companies will spend more on DR in 2022 and look for more flexible deployment options for DR protection, such as replicating on-premises workloads to the cloud for DR, or multinode failover clustering across cloud availability zones and regions.” However, SQL Server AGs with automatic failover have not been supported in Kubernetes.
This design needs to keep costs at a minimum, and it needs to allow for failure detection and manual failover of resources. The solution Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environments.
Use API-driven architecture Enable secure, scalable, and efficient connectivity between cloud and on-premises environments with standardized APIs. Architect for high availability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content