This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Being able to choose between different compute architectures, such as Intel and AMD, is essential for maintaining flexibility in your DR strategy. Zerto excels in this area by offering an agnostic approach to DR, ensuring flexibility and compatibility across various platforms, whether you are using Intel or AMD architectures.
AWS offers resources and services to build a DR strategy that meets your business needs. All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover.
It employs a zero-trust architecture and hardened Linux virtual appliances that follow the principles of least privilege. Leverage the built-in features of Zerto Recovery Reports used during live and test failovers as well as Zerto Analytics to prove Service Level Agreements (SLAs) for auditing and compliance.
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. Consolidated VPG State View— in addition to creating VPGs and performing failover operations, you can now view a simplified VPG state directly from the cloud console.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Paired with regular system testing, this helps teams to quickly understand and resolve incidents, even when primary systems fail.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. Current Architecture with improved resiliency and standardized observability. Predictive scaling for EC2. Conclusion.
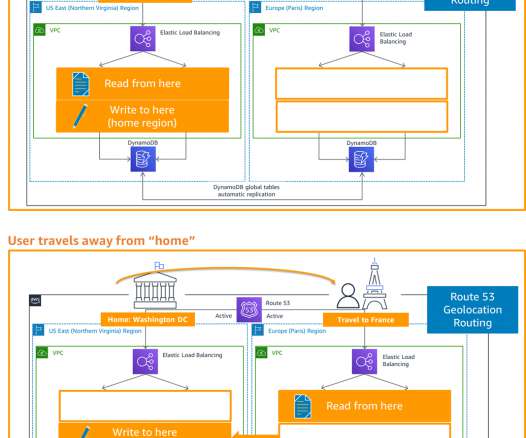
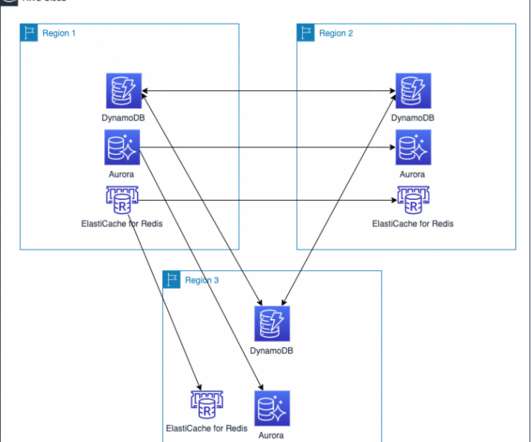
The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. To maintain low latencies and reduce the potential for network error, serve all read and write requests from the local Region of your multi-Region active/active architecture. DR strategies.
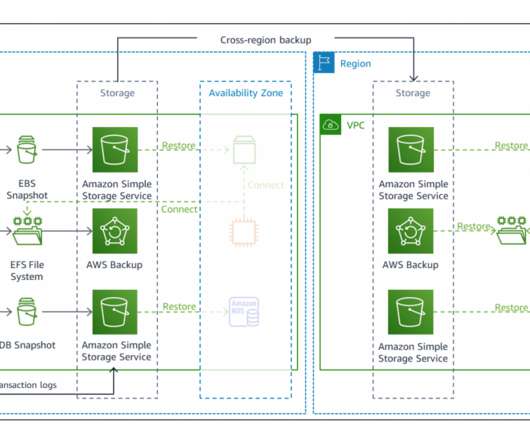
Failover and cross-Region recovery with a multi-Region backup and restore strategy. In Figure 5, we show a possible architecture for detecting and responding to events that impact your workload availability. Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud. Conclusion. Related information.
In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns. Resilience is an overarching concern that is highly tied to other architecture attributes. Let’s evaluate architectural patterns that enable this capability.
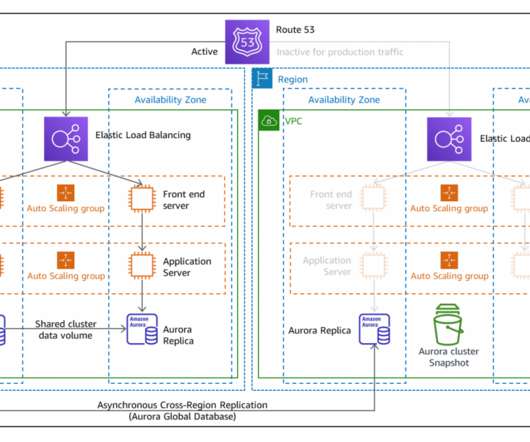
The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover. When a disaster occurs, successful recovery depends on detection of the disaster event, restoration of the workload in the recovery Region, and failover to send traffic to the recovery Region.
If low replication lag is critical, S3 Replication Time Control can help meet requirements by replicating 99.99% of objects within 15 minutes, and most within seconds. Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Purpose-built global database architecture. Related posts.
The Gold Standard: Meeting Your Business SLA Requirement. Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover. The steps are either pre-action or post-action and can be either manual action or a script to execute steps during a failover. Add Orchestration for Your DR Plan.
Architecture overview. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Looking for more architecture content? Related information.
With a wide array of options available, it can be overwhelming to determine which solution best meets your needs. Real-time replication and automated failover / failback ensure that your data and applications are restored quickly, minimizing downtime and maintaining business continuity.
In short, the sheer scale of the cloud infrastructure itself offers layers of architectural redundancy and resilience. . Whether you are on-premises, a hybrid cloud, or born in the cloud, you should make sure your strategy is meeting your needs to avoid downtime and data loss; and not being held back by legacy technologies and procedures.
Assured Data Protection tailors its solutions to meet the individual business needs of mid-market enterprises, making them affordable and achievable, from on-premise private clouds to hybrid cloud approaches. . The product is built on an architecture that the company refers to as “High Availability Anywhere.”
Assured Data Protection tailors its solutions to meet the individual business needs of mid-market enterprises, making them affordable and achievable, from on-premise private clouds to hybrid cloud approaches. . The product is built on an architecture that the company refers to as “High Availability Anywhere.”
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy.
UDP provides comprehensive Assured Recovery for virtual and physical environments with a unified architecture, backup, continuous availability, migration, email archiving, and an easy-to-use console. Users are enabled to retain business data in order to meet compliance requirements.
Item #3: “ Active/Active Controller Architecture”¹⁴ Is a Good Thing We see this B.S. ” ¹⁵ PowerStore claims “active/active controller architecture where both nodes are servicing I/O simultaneously.” ¹⁶ Frankly, that has been the legacy over the course of VNX to Unity to now PowerStore. The six PowerStore B.S. PowerStore B.S.
The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes.
This new cloud offering uses the same: True CDP: Based on our three key differentiators: Near-synchronous replication Hyper-granular journaling technology App-centric recovery Nondisruptive testing: with no impact to your production environment, you can test failovers or failbacks during regular business hours.
It presents an opportunity to redefine your architecture. This ensures that your IT teams can meet even the most stringent disaster-recovery requirements. ActiveCluster provides seamless failover to deliver zero to near-zero RPO and RTO. . The explosion of digital business has exacerbated the need for an infrastructure rehaul.
This does not easily allow for failover or recovery at a granular level. Choose the technology, or technologies, that best meet your organization’s need and look for ways to combine them for maximum benefit. Recovery is therefore of the entire volume as well.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Paired with regular system testing, this helps teams to quickly understand and resolve incidents, even when primary systems fail.
enables customers to deploy a multitarget high availability environment in which HANA operates on a primary node and, in the event of a failure or disaster, can failover to a secondary and/or a tertiary target node located in a different cloud Availability Zone or on-premises disaster recovery location. Read on for more. [ Read on for more.
Pure FlashArray//X uses a scale-up storage architecture that allows a simpler and more flexible upgrade path. PowerMax: So should you look to Dell PowerMax for true “scale-out” architecture? It’s an interesting claim since PowerMax can’t meet that without some help (see the PowerMax section below).
NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases high availability but also failover and fault tolerance in the event of a failure or outage. Using Non-relational Databases As mentioned above, NoSQL databases are able to meet the unique demands of modern data and applications.
It’s important to do full failover and recovery whenever possible so that you truly can understand the nuances you may face in a real situation. Getting a copy of your data is often the easy part, but building an effective program to address all the other aspects of data continuity is where a lot of the work happens.
Concerns about the ability to meet 99.99% SLAs in the cloud for business critical applications will prompt companies to implement sophisticated application-aware high availability and disaster recovery solutions.” Data protection that meets the demands of the moment can’t just be an item on a checklist in 2022.
Use API-driven architecture Enable secure, scalable, and efficient connectivity between cloud and on-premises environments with standardized APIs. Architect for high availability and failover Design multi-cloud and multi-region redundancy to prevent single points of failure and minimize business disruptions.
This architecture allows for more efficient resource allocation and better performance. Disaster recovery and backup: Hyper-V supports live migration, replication, and failover clustering, making it a popular choice for business continuity and disaster recovery solutions. What Is Hyper-V?
Its flexible architecture allows for both on-premises and cloud integration. Its flexible, modular architecture has made it a cornerstone of many large-scale private clouds and hybrid cloud deployments. Architecture VMware products are tightly integrated and controlled within its ecosystem.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content