This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
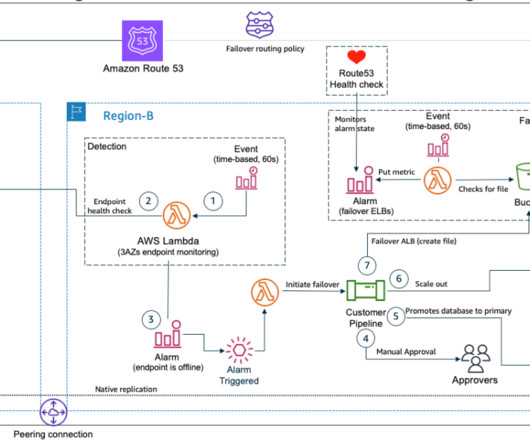
Since this file was created for our failover event, the pipeline will now remove this file. This design showcases the company’s ability to tailor their architecture to their specific requirements. It ensures minimal disruption to business operations during regional outages.
Event-driven automation is a powerful approach to managing enterprise IT environments, allowing systems to automatically react to enterprise events (Observability / Monitoring / Security / Social / Machine) and reducing or removing the need for manual intervention. Guard rails can be easily added to prevent accidental overscaling.
Preparing for Cyber Events Beyond day-to-day operations, Commvault uses an isolated recovery environment to simulate cyberattacks and validate its disaster recovery plans. We simulate everything from full data center outages to ransomware events and ensure we can recover the critical systems quickly.”
Data] now has become a huge liability in terms of its susceptibility to cybersecurity events.” Patch-friendly architecture: Infrastructure that allows non-disruptive patching—upgrades with zero downtime—is vital for busy agencies that can’t risk service outages. And that requires modern systems capable of these demands.
Good backups guarantee a business can survive a data loss event, like ransomware, and continue making business decisions based on its data. A single point of failure, slow recovery from outages, and the increasing complexity of modern data environments demand a re-evaluation of storage strategies.
The ripple effects of slow queries can be felt across the business: abandoned shopping carts, missed service level agreements, overtime for remediation, and reputational harm that outlasts the outage. The New Storage Baseline for Modern Database Workloads Legacy storage architectures weren’t built for today’s database demands.
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Scope of impact for a disaster event.
This and other security controls are aspects of zero trust architectures , which should be looked at as a journey, not a destination. The backbone of cyber resilience comes from a foundation: a data-resilient security architecture deeply integrated with tech partners who can uphold the latest standards and frameworks. Let’s dig in.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Decoupling integrations using event-driven design patterns. But we found the key to troubleshooting: observability and event correlation, as explained in the following sections.
Undoubtedly, VMware Explore stands out as one of my favorite events of the year. While basking in the lively atmosphere of the event, one dominant theme echoed throughout our booth discussions – ransomware. While basking in the lively atmosphere of the event, one dominant theme echoed throughout our booth discussions – ransomware.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. Architecture overview. DR Strategies. OpenSearch Service.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. There is an order of magnitude difference between the two.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Business Data Loss and Corruption. Data Loss and Corruption. Traditional Database Recovery. In-place Surgical Data Fix.
Remember, after an outage, every minute counts…. Jointly architectured by two of the industry’s most trusted companies, FlashRecover//S is designed specifically to deliver a powerful yet easy-to-use solution with multiple levels of built-in ransomware protection that can provide petabyte-scale recovery of data in just hours. .
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. If not, a single controller failure could cause a data outage or corruption.
As you review the key objectives and recommendations, ask yourself: Is my security architecture resilient? Those investments add up to one concept: a tiered resiliency architecture. A three-tiered resiliency architecture can protect your entire data estate, which I outlined how to do do this in this article.
An IT outage of any sort can adversely impact people’s lives. In the event of an incident, organizations can easily recover their data from any point in time, reducing the potential for data loss and minimizing downtime. This minimizes the risk of data loss and enables entities to achieve lower Recovery Point Objectives (RPOs).
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
Does your heart sink a bit when you think about how much your rulesets have sprawled in order to manage your event processing needs? That’s why we released Event Orchestration earlier this year to help teams reduce the amount of manual work that goes into event management. What is Event Orchestration?
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. Other reasons include to minimize the operational, financial, legal, reputational and other material consequences arising from such events. Architecture Overview.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object.
Data availability ensures that users have access to the data they need to maintain day-to-day business operations at all times, even in the event that data is lost or damaged. Additionally, the platform utilizes a scale-out architecture that starts with a minimum of three nodes and scales without disruption by adding nodes to the cluster.
In Part II, we’ll explore the technical considerations related to architecture and patterns. It’s also sometimes mixed with concerns about highly publicized security or outageevents. Like other architecture attributes, resilience is measured on a scale (that is, a degree to which a system is resilient).
What if the very tools that we rely on for failover are themselves impacted by a DR event? As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. How do we reduce additional dependencies?
Consider engaging in a discussion with the CISO about the benefits of tiered security architectures and “ data bunkers ,” which can help retain large amounts of data and make it available immediately. How often do we test how our systems would perform in the event of an attack? Or 10 hours?”
But even internally, an outage can be disastrous. The city had to spend $10 million on recovery efforts, not including the $8M in lost revenue from a two-week outage of bill payment systems and real estate transactions. Event logging and analytics layers. Data from ESG research shared during Pure//Accelerate® Digital 2021.
The largest hyperscale clouds have a highly redundant architecture that copies data in multiple places throughout its infrastructure. After all, while cloud outages aren’t very common, they do occur. Microsoft Azure, March 2020: Azure experienced a six-hour outage in the Eastern U.S. The cloud certainly has a lot going for it.
But before we get to that, let’s look at a common failure event. Failure scenarios could come in the form of an event where the data storage is lost. Figure 3: Architecture used to test data ingestion and restore speed with a four-node system. FlashBlade Object Storage can make this whole process easier and faster.
In the event of a primary server failure, processes running the services are moved to the standby cluster. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes. While this architecture can ensure that the application is always online, it comes at a cost.
Surging ransomware threats elevate the importance of data privacy and protection through capabilities such as encryption and data immutability in object storage – capabilities that protect sensitive data and enable teams to get back to business fast in the event of such an attack.
As more enterprises adopt containers and Kubernetes architectures for their applications, the reliance on microservices requires a solid data protection strategy. In the event of an outage due to a ransomware attack completely taking your primary site down, Zerto for Kubernetes helps users fight back by performing a failover live operation.
If there are any issues with the fulfillment of our performance or capacity obligations, you can trust Pure to resolve this with our best-in-class NPS score of 83+ and our Evergreen™ and Evergreen architecture. This sounds like a purchasing event that’s non co-terminus and really not an obligation or a service.
However, because setting it up involves rebuilding much of the organization’s network security architecture, implementing it is a serious burden and a major project, one that typically takes multiple years. It is common for recovery plans and strategies to identify substitutes to perform various roles during an event.
While competing solutions start the recovery process only after AD goes down, Guardian Active Directory Forest Recovery does it all before an AD outage happens. This helps minimize downtime in the event of outages or cyberattacks. The goal?
They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. The system can quickly detect outages and report them to the utility, leading to faster restoration of services. Customers are also informed about the state of outages in real time.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. Unexpected power outages and equipment failures were familiar events that crippled technology but not manual procedures.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. Unexpected power outages and equipment failures were familiar events that crippled technology but not manual procedures.
These include ensuring that they have a solid business case that considers all aspects of the implementation to get the best return on investment, that the right architecture is chosen for the business strategy, that they manage the data appropriately prior to starting the transformation, and more.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object.
As organizations migrate to the cloud and deploy cloud-native architectures, the increased complexity can cause more (expensive) incidents. Many organizations run in complex cloud architectures containing several interconnected services — many existing ephemerally — that are deployed across different availability zones and accounts.
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. Get the Guide What Is Disaster Recovery Planning?
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. What Is Disaster Recovery Planning?
Simple Architecture, Simple Scale. Figure 2: NetBackup, FlashArray//C, and VMware architecture. If your environment suffers an outage, whether from a ransomware attack or another type of disaster scenario, your authorized administrator needs to contact Pure Customer Support to authenticate access. Format and mount the devices.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content