This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Storage Architecture Spectrum: Why “Shared-nothing” Means Nothing by Pure Storage Blog This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. And just as important, why there is more to any product or platform than just architecture.
This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Scope of impact for a disaster event.
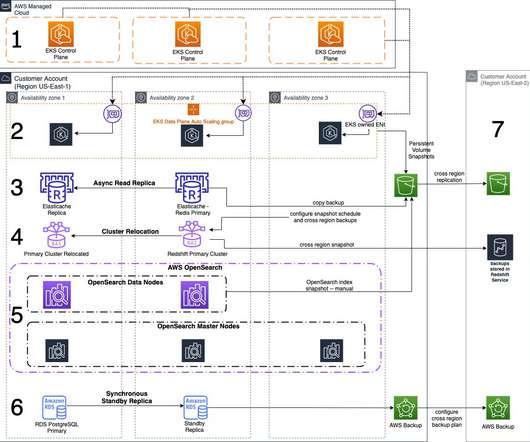
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). The main traffic flows through the primary and the secondary Region acts as a recovery Region in case of a disaster event. This keeps RTO and RPO low.
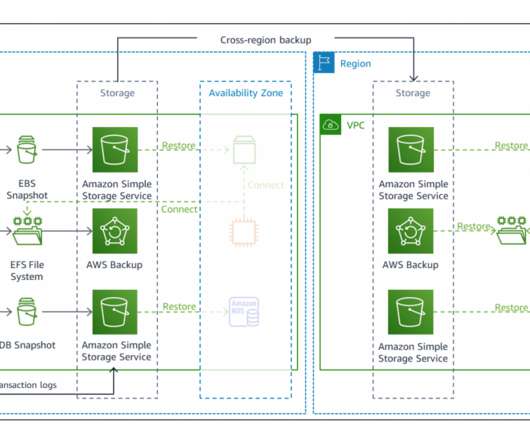
By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions. Failover and cross-Region recovery with a multi-Region backup and restore strategy.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. Decoupling integrations using event-driven design patterns. Predictive scaling for EC2. Centralized logging.
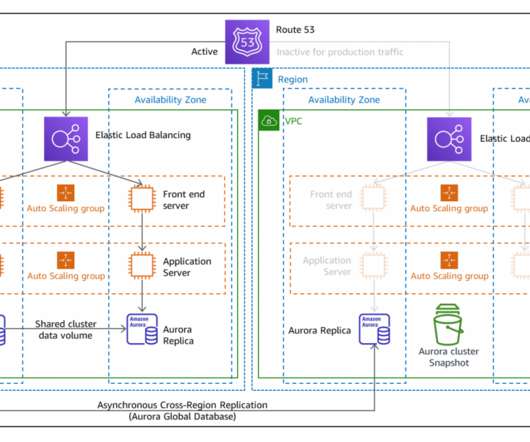
Like other DR strategies, this enables your workload to remain available despite disaster events such as natural disasters, technical failures, or human actions. The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. DR strategies.
Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. Zerto pulls a “gold copy” of the infected VM initially backed up before the event to a repository. Get Your Files Back!
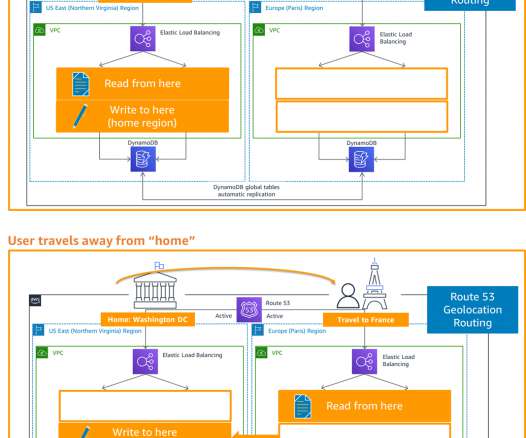
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover.
In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns. Resilience is an overarching concern that is highly tied to other architecture attributes. Let’s evaluate architectural patterns that enable this capability.
A zero trust network architecture (ZTNA) and a virtual private network (VPN) are two different solutions for user authentication and authorization. Administrators can use single sign-on (SSO) solutions, but these solutions must integrate with your zero trust network architecture for data protection. What Is VPN?
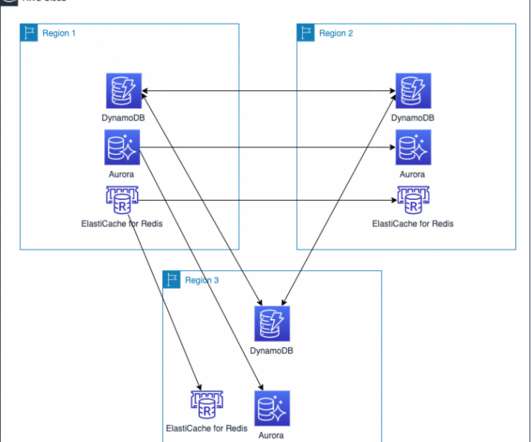
To monitor the replication status of objects, Amazon S3 events and metrics will track replication and can send an alert if there’s an issue. Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Purpose-built global database architecture. Related posts.
Application-consistent points in time will be indicated as a checkpoint in the Zerto journal of changes to ensure visibility when performing a move, failover, or failover test in Zerto. In the event of a crash recovery, the database will recover from a specific checkpoint and behave like it is recovering from a failure.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. Architecture overview. DR Strategies. Related information.
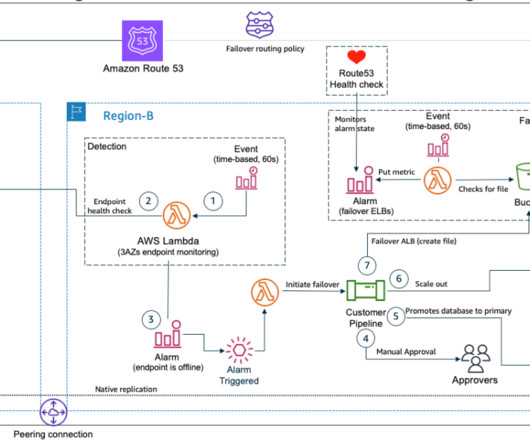
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Static stability.
In the event of an incident, organizations can easily recover their data from any point in time, reducing the potential for data loss and minimizing downtime. With Zerto, state, local, and education entities can easily create and manage recovery plans, perform non-disruptive testing, and streamline the failover/failback processes.
In short, the sheer scale of the cloud infrastructure itself offers layers of architectural redundancy and resilience. . We accomplish this by automating and orchestrating snapshots and replication within EBS to efficiently move data across regions and allow rapid failover between regions in a disaster event.
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. This brings two challenges: data consistency and complexity.
With Zerto, SREs can replicate data in real-time, ensuring that the most recent version of data is always available in the event of a disaster. This eliminates the need for manual intervention and reduces the risk of human error when initiating a failover. Zerto also automates DR processes. Another important aspect of DR is testing.
As more enterprises adopt containers and Kubernetes architectures for their applications, the reliance on microservices requires a solid data protection strategy. In the event of an outage due to a ransomware attack completely taking your primary site down, Zerto for Kubernetes helps users fight back by performing a failover live operation.
A new comprehensive reference architecture from Pure Storage and Rubrik provides a multi-layered approach that strengthens cyber resilience. This evolving threat landscape requires a more sophisticated, automated, cyber-resilient architecture to ensure comprehensive data security.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1 or later.
The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests. In the event of a primary server failure, processes running the services are moved to the standby cluster.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The company’s Disaster Recovery as a Service ( DRaaS ) solution, Recovery Cloud, provides recovery of business-critical applications to reduce data loss in the event of a disaster.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. The company’s Disaster Recovery as a Service ( DRaaS ) solution, Recovery Cloud, provides recovery of business-critical applications to reduce data loss in the event of a disaster.
Data availability ensures that users have access to the data they need to maintain day-to-day business operations at all times, even in the event that data is lost or damaged. Additionally, the platform utilizes a scale-out architecture that starts with a minimum of three nodes and scales without disruption by adding nodes to the cluster.
Companies will spend more on DR in 2022 and look for more flexible deployment options for DR protection, such as replicating on-premises workloads to the cloud for DR, or multinode failover clustering across cloud availability zones and regions.” However, SQL Server AGs with automatic failover have not been supported in Kubernetes.
This example architecture refers to an application that processes payment transactions that has been modernized with AMS. That way, in the rare event of an AZ disruption, two master nodes will still be available. If an AZ or infrastructure fails, Amazon RDS performs an automatic failover to the standby. Amazon RDS PostgreSQL.
IT organizations have mainly focused on physical disaster recovery - how easily can we failover to our DR site if our primary site is unavailable. The issue is, typically those processes are more focused on temporary manual fallback procedures versus switching entirely to a new supplier in the event of a major availability event.
Pure offers additional architectural guidance and best practices for deploying MySQL workloads on VMware in the new guide, “ Running MySQL Workloads on VMware vSphere with FlashArray Storage.” Single-command failover. It helps ensure that they remain available in the event of a site or array failure. Multi-direction replication.
This helps minimize downtime in the event of outages or cyberattacks. This latest version introduces advanced DR features, including synchronous and asynchronous data mirroring, intelligent failover mechanisms, enhanced security management, expanded language support, and additional Linux operating system compatibility. The goal?
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. Get the Guide What Is Disaster Recovery Planning?
Disaster recovery , often referred to simply as “DR,” ensures that organizations can rebound quickly in the face of major adverse events. The primary focus of DR is to restore IT infrastructure and data after a significantly disruptive event. What Is Disaster Recovery Planning?
Pulling myself out of bed and rolling into the office at 8am on a Saturday morning knowing I was in for a full day of complex failover testing to tick the regulator’s box was a bad start to the weekend. So let’s get started and take a look at a logical architecture diagram of what we’re about to build.
Surging ransomware threats elevate the importance of data privacy and protection through capabilities such as encryption and data immutability in object storage – capabilities that protect sensitive data and enable teams to get back to business fast in the event of such an attack.
enables customers to deploy a multitarget high availability environment in which HANA operates on a primary node and, in the event of a failure or disaster, can failover to a secondary and/or a tertiary target node located in a different cloud Availability Zone or on-premises disaster recovery location. Read on for more. [
As we have remarked before f lash memory is so radically different from hard drives that it requires wholly new software controller architecture. HA cannot be left as a homework exercise: Requiring a customer to buy two machines and then figure out how to configure failover, resync and failback policies is not what we mean by HA.
Disaster recovery (DR) is a mix of plans, procedures, and data protection and recovery options that is performance optimized to restore your IT services and data as fast as possible with little data loss after a disruptive event. DR for many organizations is a necessity for service-level agreements (SLAs or industry rules.
Apache Kafka is an event-streaming platform that runs as a cluster of nodes called “brokers.” Portworx can provide the same abstraction and benefits for your Kafka on Kubernetes architecture regardless of the cloud or infrastructure. Kafka is extremely fast. We’ve benchmarked Kafka write speeds at 5 million messages/sec on Flasharray.
Application: In the event of a cybersecurity breach, AI automates the identification, containment, and eradication of threats, reducing response time. Application: During a disruptive event or disaster, AI dynamically adjusts cloud resources to ensure critical applications receive the necessary computing power.
NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases high availability but also failover and fault tolerance in the event of a failure or outage. Here’s where eventual consistency helps, propagating changes made to a database across nodes over time. Built-in replication.
This design needs to keep costs at a minimum, and it needs to allow for failure detection and manual failover of resources. The solution Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environments.
Its flexible architecture allows for both on-premises and cloud integration. Its flexible, modular architecture has made it a cornerstone of many large-scale private clouds and hybrid cloud deployments. Architecture VMware products are tightly integrated and controlled within its ecosystem.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content