This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To navigate these challenges, organizations must adopt a comprehensive disasterrecovery (DR) strategy. Networking ensures the rapid recovery of critical systems and data, directly influencing key metrics like Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs).
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. Architecture of the DR strategies.
In disasterrecovery , resilience is the ultimate goal. Weve explored the critical roles that speed and integrity play in recovery, but theres one more critical piece to the equation: flexibility. As businesses move toward hybrid and multi-cloud environments, a rigid recovery solution becomes a liability.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. Moreover, cloud-services providers are themselves susceptible to outages and failed recoveries.
Give your organization the gift of Zerto In-Cloud DR before the next outage . At the end of November, I blogged about the need for disasterrecovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then.
In part I of this series, we introduced a disasterrecovery (DR) concept that uses managed services through a single AWS Region strategy. Using multiple Regions ensures resiliency in the most serious, widespread outages. Architecture overview. In part two, we introduce a multi-Region backup and restore approach.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
What does static stability mean with regard to a multi-Region disasterrecovery (DR) plan? As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. Testing your disasterrecovery plan.
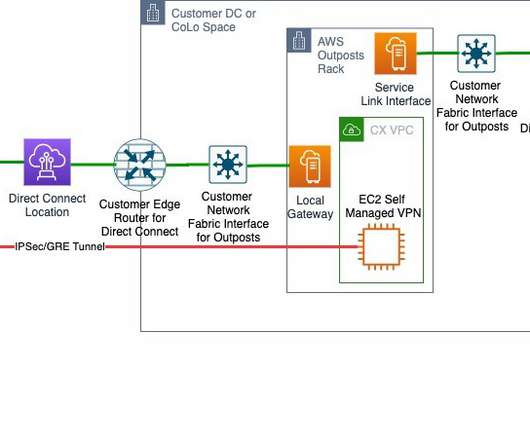
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. During an outage in the primary Region, Velero restores volumes from the latest snapshots in the standby cluster.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. That’s why many customers replicate their mission-critical workloads in multiple places using a DisasterRecovery (DR) strategy suited for their needs. Prerequisites.
Business Continuity vs. DisasterRecovery: What’s the Difference? It’s important to understand the distinctions between business continuity planning (BCP) and disasterrecovery planning (DRP) because they each entail a different set of problems, priorities, and solutions. Get the Guide What Is DisasterRecovery Planning?
Business Continuity vs. DisasterRecovery: What’s the Difference? It’s important to understand the distinctions between business continuity planning (BCP) and disasterrecovery planning (DRP) because they each entail a different set of problems, priorities, and solutions. What Is DisasterRecovery Planning?
Planning your business disasterrecovery solution is an exhausting process that requires a lot of rehearsal testing and allocation of expensive resources. In a disasterrecovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible.
How to Create a Network DisasterRecovery Plan by Pure Storage Blog When Colonial Pipeline fell victim to a devastating cyberattack in May 2021, the company’s operations came to a standstill, leading to widespread fuel shortages throughout the eastern United States. Get the Guide What Is a Network DisasterRecovery Plan?
How to Create a Network DisasterRecovery Plan by Pure Storage Blog When Colonial Pipeline fell victim to a devastating cyberattack in May 2021, the company’s operations came to a standstill, leading to widespread fuel shortages throughout the eastern United States. What Is a Network DisasterRecovery Plan?
Cyber Recovery vs. DisasterRecovery by Pure Storage Blog Data infrastructures aren’t just built for storage, performance, and scale—they’re designed for resilience. Two key areas of concern include disasterrecovery in general, and, more specifically, cyber recovery.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of high availability (HA) and disasterrecovery (DR) is paramount. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes.
An IT outage of any sort can adversely impact people’s lives. Zerto delivers solutions to help navigate SLED data management needs, particularly in the areas of continuous data protection , ransomware detection , disasterrecovery and multi-cloud environments. Read a Zerto SLED cloud success story from the City of Tyler, Texas.
Data protection is a broad field, encompassing backup and disasterrecovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disasterrecovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
Benefit: Maintains cloud infrastructure consistency, minimizing the risk of configuration drift, which can lead to unexpected outages or security vulnerabilities. Automated Backup and Recovery Description: Regular backups are critical for business continuity. Automated backups ensure that data is always recoverable. — 10.
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Many databases use storage replication for high availability (HA) and disasterrecovery (DR). Business Data Loss and Corruption.
In 2022, IDC conducted a study to understand the evolving requirements for ransomware and disasterrecovery preparation. The native Kubernetes solution drives a “data protection as code” strategy, integrating backup and disasterrecovery operations into the application development lifecycle from day one.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. The law practice did not have a formal business continuity or disasterrecovery plan. The damage was not limited to this building.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. The law practice did not have a formal business continuity or disasterrecovery plan. The damage was not limited to this building.
As you review the key objectives and recommendations, ask yourself: Is my security architecture resilient? Those investments add up to one concept: a tiered resiliency architecture. A three-tiered resiliency architecture can protect your entire data estate, which I outlined how to do do this in this article.
In Part II, we’ll explore the technical considerations related to architecture and patterns. After asking follow up questions, it became clear their concern was about how to implement a two-site data center disasterrecovery (DR) in the cloud. Architecture reviews. Customer challenges.
In an ever-changing IT landscape where it’s crucial to maintain uninterrupted business operations, robust disasterrecovery (DR) solutions like Zerto for Azure are an absolute necessity. This means that users can now have multiple VRAs for enhanced replication and recovery capabilities. The post What’s New in Zerto 10 for Azure?
by Pure Storage Blog Recovery time objective (RTO) and recovery point objective (RPO) are two important concepts used in disasterrecovery planning. RTO is the service level defining how long a recovery may take before unacceptable levels of damage occur from an outage. After that time, the business suffers.
by Pure Storage Blog Recovery time objective (RTO) and recovery point objective (RPO) are two important concepts used in disasterrecovery planning. RTO is the service level defining how long a recovery may take before unacceptable levels of damage occur from an outage. After that time, the business suffers.
Good and consistent disasterrecovery doesn’t hurt either, Houle added, and that’s where the idea of tiers comes into play. Watch the entire tech talk to learn about creating a data protection plan that prevents disruption from things like unplanned outages.
As part of Solutions Review’s ongoing coverage of the enterprise storage, data protection, and backup and disasterrecovery markets, lead editor Tim King offers this nearly 7,000-word resource. This includes the availability of emergency backup services, such as batteries and generators, in case of power outages.
The cloud has a lot going for it as a backup and disasterrecovery (DR) target. The largest hyperscale clouds have a highly redundant architecture that copies data in multiple places throughout its infrastructure. After all, while cloud outages aren’t very common, they do occur. The cloud certainly has a lot going for it.
They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. The system can quickly detect outages and report them to the utility, leading to faster restoration of services. Customers are also informed about the state of outages in real time.
Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. Pure FlashBlade’s Rapid Restore enables 270TB/hr data recovery speed. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
Why the need for disasterrecovery specialists? According to the Veeam Data Protection Report 2021 , the average hourly toll of downtime is $84,650, the typical outage taking around 79 minutes to resolve. Disasterrecovery services on target or overkill? There’s cost. There’s threat increases.
As part of Solutions Review’s ongoing coverage of the enterprise storage, data protection, and backup and disasterrecovery markets, our editors bring you an exclusive curation of World Backup Day 2025 insights from our expert community. This World Backup Day, take the time to review your backup and disasterrecovery strategies.”
While competing solutions start the recovery process only after AD goes down, Guardian Active Directory Forest Recovery does it all before an AD outage happens. This helps minimize downtime in the event of outages or cyberattacks.
Let’s explore the transformative role of innovations and emerging technologies in shaping the future of business continuity, along with crisis management and disasterrecovery to enhance organizational resilience. Performing real-time diagnostics, automating backup and recovery procedures and more.
Pure offers additional architectural guidance and best practices for deploying MySQL workloads on VMware in the new guide, “ Running MySQL Workloads on VMware vSphere with FlashArray Storage.” MySQL Workloads DisasterRecovery MySQL databases are the heart of many businesses. Single-command failover. Multi-direction replication.
Decsription: In this course, you’ll be introduced to the architecture of Veeam’s backups, getting to know the methods that Veeam can use to store data. Additionally, you’ll learn how to configure replication jobs to a secondary disasterrecovery site. Managing Cybersecurity Incidents and Disasters.
For both backup and recovery operations, NetBackup’s ability to process in parallel and the native block and file storage capabilities of FlashArray//C deliver the performance your business needs. Simple Architecture, Simple Scale. Figure 2: NetBackup, FlashArray//C, and VMware architecture. Format and mount the devices.
For example, many architectures on AWS, even those that split workloads into multiple availability zones, have one central data lake or bucket. The biggest myths in AWS architecture are often related to resilience. In addition to the regulatory commitments of an organization, data needs to be operationally resilient.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content