This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
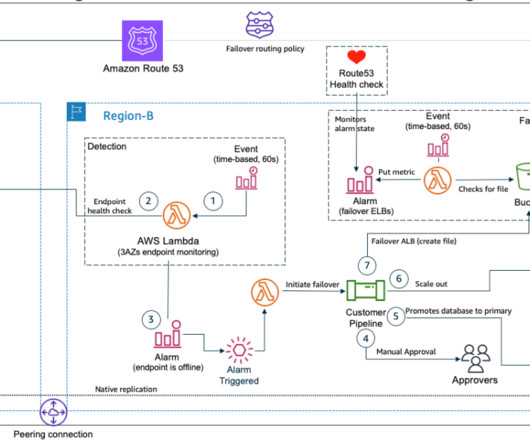
It also accounts for the incidence of natural disasters, such as earthquakes or floods and technical failures, such as power failure or network connectivity. AWS recommends a multi-AZ strategy for high availability and a multi-Region strategy for disasterrecovery. Failover Our customer decided to test the Pilot Light scenario.
Disasters are unpredictable, but your response to them shouldn’t be. A well-thought-out disasterrecovery (DR) plan is your best defense against unexpected disruptions. Being able to choose between different compute architectures, such as Intel and AMD, is essential for maintaining flexibility in your DR strategy.
To navigate these challenges, organizations must adopt a comprehensive disasterrecovery (DR) strategy. Networking ensures the rapid recovery of critical systems and data, directly influencing key metrics like Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs).
Weve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channels original scope, and your readership this last year has proven that decision was the right one. Well, its been another historic year!
And perhaps most importantly How robust your backup and disasterrecovery strategy is and whether your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are optimized to minimize downtime and data loss. Automated Recovery Testing Gone are the days of manual backup testing. Which brings us to 3.
Your AI features run right where your data already lives, leveraging existing security and availability features, simplifying architectures, and accelerating time to value. AlwaysOn availability groups: Your AI-enabled databases can participate in availability groups, providing high availability and disasterrecovery for your AI workloads.
Your AI features run right where your data already lives, leveraging existing security and availability features, simplifying architectures, and accelerating time to value. AlwaysOn availability groups: Your AI-enabled databases can participate in availability groups, providing high availability and disasterrecovery for your AI workloads.
Business continuity professionals must ensure robust disasterrecovery plans, while IT professionals grapple with the technical complexities of maintaining uptime. In finance, real-time transaction processing demands zero-downtime architectures. Invest in Technologies that Reduce Errors and enable Faster Recovery.
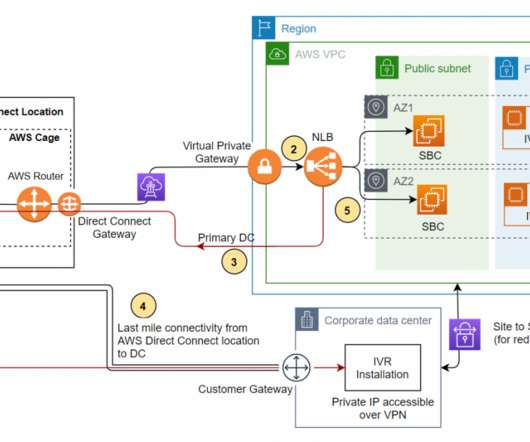
A zero trust network architecture (ZTNA) and a virtual private network (VPN) are two different solutions for user authentication and authorization. Administrators can use single sign-on (SSO) solutions, but these solutions must integrate with your zero trust network architecture for data protection. What Is VPN?
For example, legacy SAN/NAS architectures reliant on vendor-specific SCSI extensions or non-standardized NFSv3 implementations create hypervisor lock-in. A unified storage platform supporting vVols with per-VM IOPS limits and failover priorities reduces manual intervention and automates these processes to free up IT resources (e.g.,
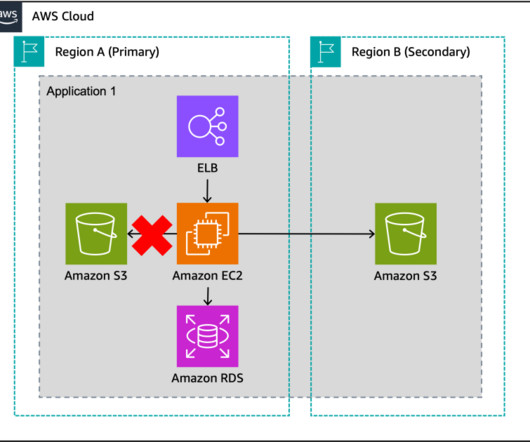
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. Architecture of the DR strategies.
This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. Component-level failover Applications are made up of multiple components, including their infrastructure, code and config, data stores, and dependencies.
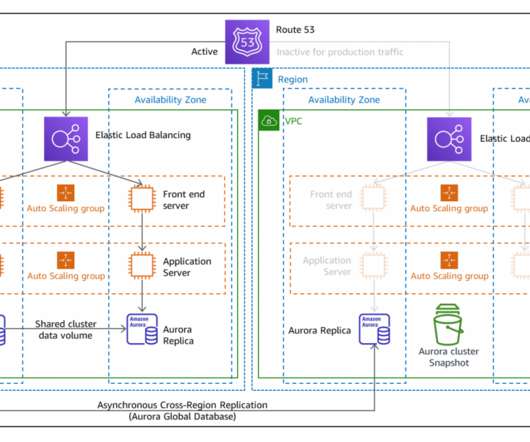
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disasterrecovery (DR). DR implementation architecture on multi-Region active/passive workloads. Fail over with event-driven serverless architecture. Figure 1.
Since the primary objective of a backup site is disasterrecovery (DR) management, this site is often referred to as a DR site. DisasterRecovery on AWS. DR strategy defines the recovery objectives for downtime and data loss. The workload has a recovery time objective (RTO) and a recovery point objective (RPO).
Solutions Review’s listing of the best DisasterRecovery as a Service companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. Technically speaking, DisasterRecovery as a Service (DRaaS) tools are often labeled as stand-alone offerings.
In part I of this series, we introduced a disasterrecovery (DR) concept that uses managed services through a single AWS Region strategy. Architecture overview. Health checks are necessary for configuring DNS failover within Route 53. DisasterRecovery with AWS Managed Services, Part I: Single Region.
Solutions Review’s listing of the best cloud disasterrecovery solutions is an annual sneak peek of the solution providers included in our Buyer’s Guide for DisasterRecovery as a Service. To make your search a little easier, we’ve profiled the best cloud disasterrecovery solutions all in one place.
This post is the third in a series of three that explores some insights from the IDC white paper, sponsored by Zerto— The State of DisasterRecovery and Cyber Recovery, 2024–2025: Factoring in AI ¹. With a wide array of options available, it can be overwhelming to determine which solution best meets your needs.
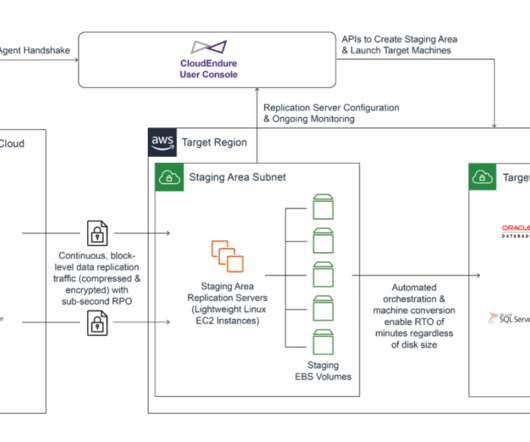
In a previous blog post , I introduced you to four strategies for disasterrecovery (DR) on AWS. These strategies enable you to prepare for and recover from a disaster. For your recovery Region, you should use a different AWS account than your primary Region, with different credentials. Related information.
Solutions Review’s listing of the best backup and disasterrecovery companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. These changes speak to the cloud’s continued rise, significantly impacting the backup and disasterrecovery market over recent years.
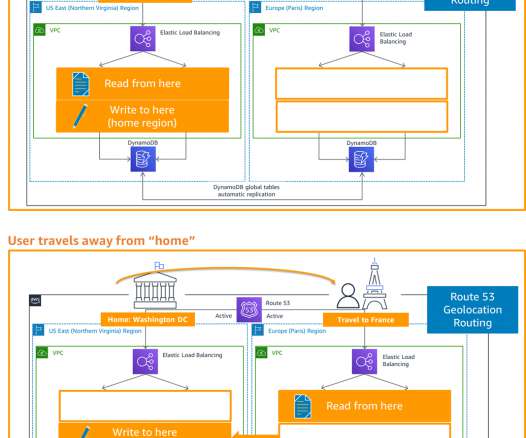
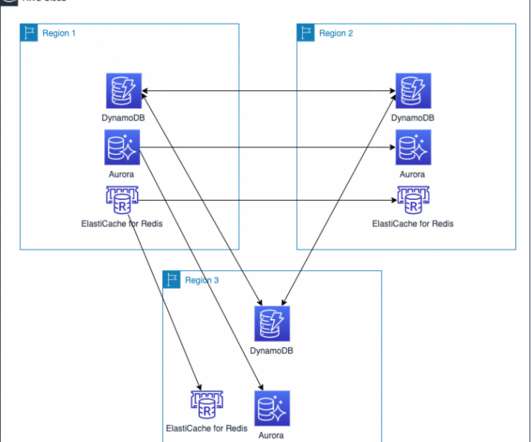
In my first blog post of this series , I introduced you to four strategies for disasterrecovery (DR). The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. I use Amazon DynamoDB for the example architecture in Figure 2.
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. Around the same time, HPE GreenLake for DisasterRecovery , built with Zerto and integrated into the HPE GreenLake Platform, became generally available.
What does static stability mean with regard to a multi-Region disasterrecovery (DR) plan? What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted.
Solutions Review’s listing of the best disasterrecovery tools for healthcare is an annual mashup of products that best represent current market conditions, according to the crowd. To make your search a little easier, we’ve profiled the best disasterrecovery tools for healthcare providers all in one place.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Previously, I introduced you to four strategies for disasterrecovery (DR) on AWS. Pilot light DR strategy.
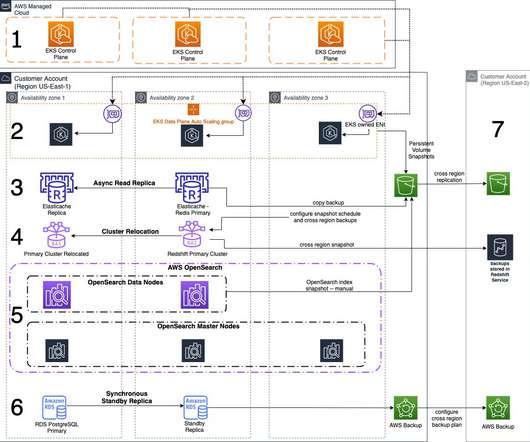
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. You would just need to create the records and specify failover for the routing policy.
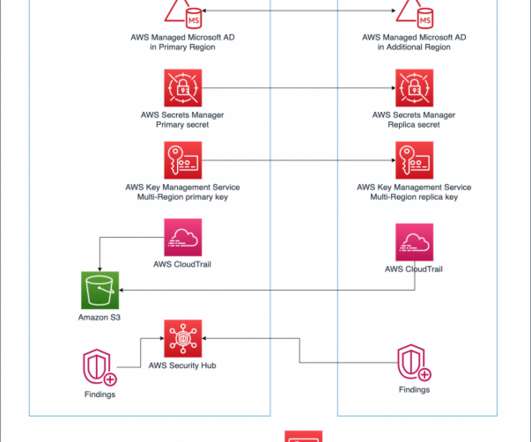
When designing a DisasterRecovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. Overview of architecture. In the following architecture, we show how you can protect domain-joined workloads in the case of a disaster.
This is ideal for those that require a recovery point objective (RPO) of seconds. Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. Get Your Files Back!
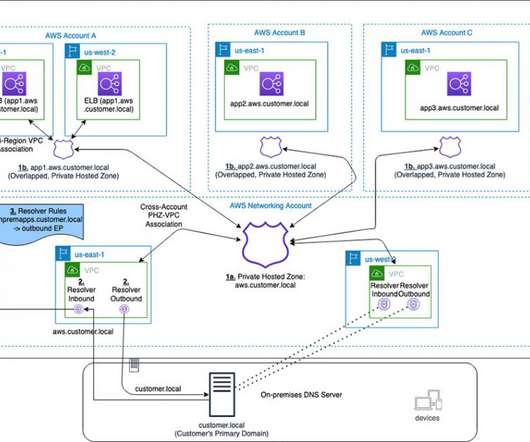
Route 53 Private Hosted Zones (PHZs) and Resolver endpoints on AWS create an architecture best practice for centralized DNS in hybrid cloud environment. Your business units can use flexibility and autonomy to manage the hosted zones for their applications and support multi-region application environments for disasterrecovery (DR) purposes.
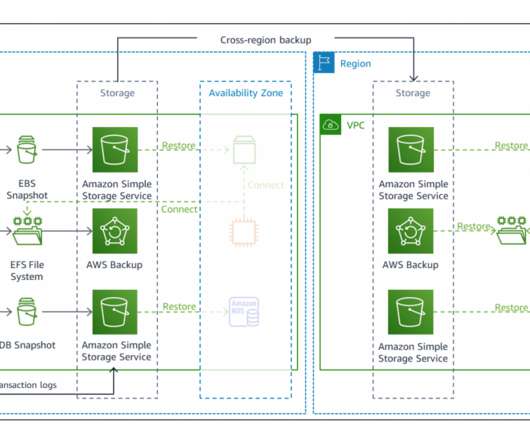
This 3-part blog series discusses disasterrecovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. This example architecture refers to an application that processes payment transactions that has been modernized with AMS. Amazon RDS PostgreSQL.
Zerto, a Hewlett Packard Enterprise company, simplifies the protection of a business’s most precious assets by providing disasterrecovery for databases at scale. As the size and number of these server instances increase, so does the complexity and requirements when it comes to disasterrecovery and replication.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. Current Architecture with improved resiliency and standardized observability. Predictive scaling for EC2. Conclusion.
At the end of November, I blogged about the need for disasterrecovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. In short, the sheer scale of the cloud infrastructure itself offers layers of architectural redundancy and resilience. . Let me explain a little more what that is. .
Planning your business disasterrecovery solution is an exhausting process that requires a lot of rehearsal testing and allocation of expensive resources. In a disasterrecovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible.
This consolidation simplifies management, enhances disasterrecovery (DR), and offers a treasure trove of benefits. Disasterrecovery woes, begone: Testing and maintaining DR plans for every array is a complex beast. Vanquish backup nightmares: Tired of late nights managing backups from individual arrays?
Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming. Reducing Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO) as part of disasterrecovery (DR) plan. Ready to get started?
In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns. Resilience is an overarching concern that is highly tied to other architecture attributes. Let’s evaluate architectural patterns that enable this capability.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of high availability (HA) and disasterrecovery (DR) is paramount. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes.
HPE GreenLake for DisasterRecovery Is Generally Available Experience Zerto wherever and however you want! Now customers can also experience Zerto as a simple, flexible SaaS-based disasterrecovery (DR) solution on HPE GreenLake, the edge-to-cloud platform. What Is the HPE GreenLake Edge-to-Cloud Platform?
Failover routing is also automatically handled if the connectivity or availability to a bucket changes. It can even be used to sync on-premises files stored on NFS, SMB, HDFS, and self-managed object storage to AWS for hybrid architectures. Purpose-built global database architecture. Related posts.
These backup appliances are also dabbling in delivering disasterrecovery capabilities using VM snapshots. Apart from traditional VM backup, software-based backup solutions are also looking to deliver disasterrecovery capabilities using VM snapshots. Scale-out architecture, scale from a few VM to thousands with ease.
Zerto delivers solutions to help navigate SLED data management needs, particularly in the areas of continuous data protection , ransomware detection , disasterrecovery and multi-cloud environments. Zerto’s journal-based recovery approach provides an added layer of protection against ransomware threats.
Business Continuity vs. DisasterRecovery: What’s the Difference? It’s important to understand the distinctions between business continuity planning (BCP) and disasterrecovery planning (DRP) because they each entail a different set of problems, priorities, and solutions. Get the Guide What Is DisasterRecovery Planning?
Business Continuity vs. DisasterRecovery: What’s the Difference? It’s important to understand the distinctions between business continuity planning (BCP) and disasterrecovery planning (DRP) because they each entail a different set of problems, priorities, and solutions. What Is DisasterRecovery Planning?
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content