This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Being able to choose between different compute architectures, such as Intel and AMD, is essential for maintaining flexibility in your DR strategy. Key Takeaways: Thorough capacity planning : Accurately assess your compute requirements to ensure you have sufficient capacity for an extended DR scenario.
BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. Data Protection and Recovery Architecture Why It Matters: Data loss during a disaster disrupts operations, damages reputations, and may lead to regulatory penalties. Are advanced security measures like zero trust architecture in place?
The Storage Architecture Spectrum: Why “Shared-nothing” Means Nothing by Pure Storage Blog This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. And just as important, why there is more to any product or platform than just architecture.
All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. Architecture of the DR strategies. Backup and restore DR architecture. Pilot light.
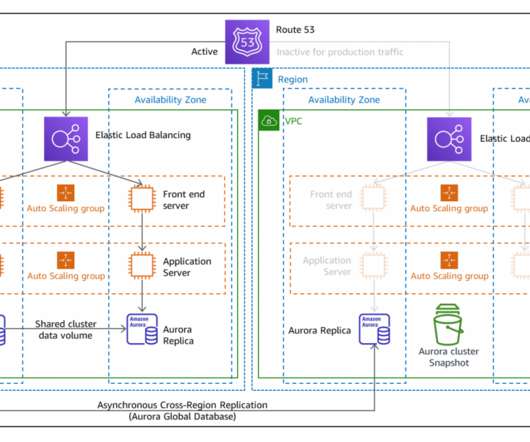
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. This keeps RTO and RPO low.
For example, legacy SAN/NAS architectures reliant on vendor-specific SCSI extensions or non-standardized NFSv3 implementations create hypervisor lock-in. Constantly Running Out of Capacity Symptom: Were always scrambling for more storage space, and adding capacity is expensive and disruptive.
Sleep soundly through hardware battles: Hardware failures are inevitable, but with fan-in replication and orchestrated failovers to the centralized target, your data is always protected, ensuring restful nights. FlashArray//C is designed to address operational workload requirements.
In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns. Resilience is an overarching concern that is highly tied to other architecture attributes. Let’s evaluate architectural patterns that enable this capability.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. This allows us to adjust capacity needs by forecasting usage patterns along with configurable warm-up time for application bootstrap.
The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover. The warm standby strategy deploys a functional stack, but at reduced capacity. Pilot light DR strategy. Warm standby DR strategy. Similarities between these two DR strategies.
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. The unique architecture enables us to upgrade any component in the stack without disruption. . Pure Cloud Block Store removes this limitation with an architecture that provides high availability.
Architecture overview. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Looking for more architecture content? Related information.
Using AWS as a DR site also saves costs, as you only pay for what you use with limitless burst capacity. This feature can greatly help solutions architects design AWS DR architectures (2). Zerto In-Cloud for AWS empowers users with the ability to logically select all EC2 instances that make up a particular application.
Resource Balancer only uses capacity-free space to determine where to place the new volume.¹³ This is why PowerStore can support different models with different capacities in the same “cluster,” because data is located only on one appliance at a time. Item #3: “ Active/Active Controller Architecture”¹⁴ Is a Good Thing We see this B.S.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Druva customers can reduce costs by eliminating the need for hardware, capacity planning, and software management.
Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. Druva customers can reduce costs by eliminating the need for hardware, capacity planning, and software management.
It’s not always an easy engineering feat when there are fundamental architectural changes in our platforms, but it’s a core value that you can upgrade your FlashArrays without any downtime and without degrading performance of business services. . The only observable activity is path failovers, which are non-disruptively handled by MPIO.
Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover. Get started with Portworx—try it for free. .
Pure offers additional architectural guidance and best practices for deploying MySQL workloads on VMware in the new guide, “ Running MySQL Workloads on VMware vSphere with FlashArray Storage.” Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations. Single-command failover.
Pulling myself out of bed and rolling into the office at 8am on a Saturday morning knowing I was in for a full day of complex failover testing to tick the regulator’s box was a bad start to the weekend. So let’s get started and take a look at a logical architecture diagram of what we’re about to build.
Be sure to carefully consider how to ensure persistence, data protection, security, data mobility, and capacity management for Kafka. These include automated capacity management capabilities, data and application disaster recovery, application-aware high availability, migrations, and backup and restore. This is where Portworx comes in.
Non-disruptive infrastructure upgrades allow for storage device firmware updates, enterprise storage expansion, and reliable seamless failover (from unexpected infrastructure incidents), while keeping the data pipelines and low-latency analytics product applications running smoothly and continuously.
As we have remarked before f lash memory is so radically different from hard drives that it requires wholly new software controller architecture. HA cannot be left as a homework exercise: Requiring a customer to buy two machines and then figure out how to configure failover, resync and failback policies is not what we mean by HA.
Later generations of Symmetrix were even bigger and supported more drives with more capacity, more data features, and better resiliency. . Today, Pure1 can help any type of administrator manage Pure products while providing VM-level and array-level analytics for performance and capacity planning. HP even shot its array with a.308
NoSQL’s ability to replicate and distribute data across the nodes mentioned above gives these databases high availability but also failover and fault tolerance in the event of a failure or outage. Here’s where eventual consistency helps, propagating changes made to a database across nodes over time. Built-in replication.
Companies will spend more on DR in 2022 and look for more flexible deployment options for DR protection, such as replicating on-premises workloads to the cloud for DR, or multinode failover clustering across cloud availability zones and regions.” However, SQL Server AGs with automatic failover have not been supported in Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content