This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Give your organization the gift of Zerto In-Cloud DR before the next outage . At the end of November, I blogged about the need for disaster recovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then.
This blog post shows how to architect for disaster recovery (DR) , which is the process of preparing for and recovering from a disaster. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. Architecture of the DR strategies. Backup and restore DR architecture. Pilot light.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
Cybersecurity Awareness Month 2024: Doing Our Part to #SecureOurWorld by Pure Storage Blog The 20th Cybersecurity Awareness Month is upon us, and we’re taking the month to spotlight resources and insights to help you improve cyber resilience and build a culture of security. Learn more in “ Why Identity Is the New Network Perimeter.”
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
Non Disruptive Upgrades: The Pure Storage Ship of Theseus by Pure Storage Blog Summary With FlashArray, upgrades can be done non-disruptively in just one to two hours, providing both technical and financial benefits to organizations. Figure 1: Nine years of NDUs across three Pure Storage platforms.
Using multiple Regions ensures resiliency in the most serious, widespread outages. Architecture overview. In our architecture, we use CloudWatch alarms to automate notifications of changes in health status. For more information, refer to the Point-in-time recovery and continuous backup for Amazon RDS with AWS Backup blog post.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or application outages.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . The post Oracle Database Troubleshooting and Problem Resolution with Storage Snapshots appeared first on Pure Storage Blog.
Remember, after an outage, every minute counts…. Jointly architectured by two of the industry’s most trusted companies, FlashRecover//S is designed specifically to deliver a powerful yet easy-to-use solution with multiple levels of built-in ransomware protection that can provide petabyte-scale recovery of data in just hours. .
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. If not, a single controller failure could cause a data outage or corruption.
Pure Storage Now a 10X Gartner® Magic Quadrant™ Leader for Primary Storage by Pure Storage Blog This blog on Pure Storage being named A Leader for Primary Storage was co-authored by Shawn Hansen, Vice President and General Manager of FlashArray, and Prakash Darji, Vice President and General Manager, Digital Experience.
It helps keep your multi-tier applications running during planned and unplanned IT outages. For those organizations that choose to migrate and run their mission-critical applications on the cloud, Pure Cloud Block Store ™ offers built-in protection against outages of availability zones, regions, and even clouds.
Resiliency Is Top Priority in 2023 White House Cybersecurity Strategy by Pure Storage Blog Last week, the White House released the updated National Cybersecurity Strategy for 2023—“A Path to Resilience.” As you review the key objectives and recommendations, ask yourself: Is my security architecture resilient?
This blog was also written by Rahul Shah. Will That Cause an Outage? A modern cloud-like storage service should never require “planned downtime” or require outage windows to perform routine software, hardware upgrades and maintenance. Real SLAs should be clear and transparent, that you can monitor and visualize for yourself.
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
Tips for Securing Your Data by Pure Storage Blog Summary Cyber extortion is a type of cybercrime thats surging. Service outages ultimately frustrate customers, leading to churn and loss of trust. Tips for Securing Your Data appeared first on Pure Storage Blog. What Is Cyber Extortion?
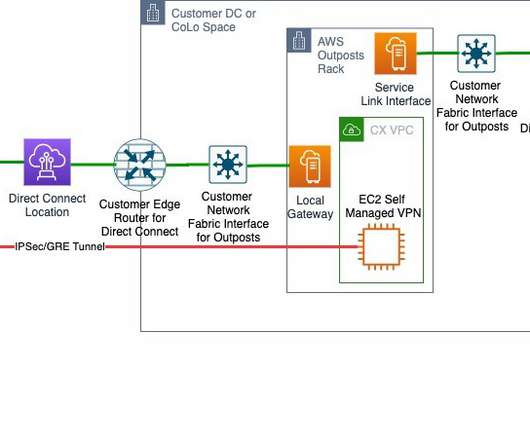
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. In this blog post, I explain how AWS Outposts can be used for DR on AWS. Another advantage of this architecture is the homogeneity of the primary and disaster recovery site.
Security Pros Share the Secret to Data Resilience by Blog Home Summary In a recent Tech Talk, experts from Presidio and Pure Storage discussed how enterprises can take advantage of their increasing amount of data while keeping it secure.
Pure Storage Now a 10X Gartner® Magic Quadrant™ Leader for Primary Storage by Pure Storage Blog This blog on Pure Storage being named A Leader for Primary Storage was co-authored by Shawn Hansen, Vice President and General Manager of FlashArray, and Prakash Darji, Vice President and General Manager, Digital Experience.
Boosting the Power of EDA Workloads on Modern Data Platform by Pure Storage Blog Industry demand and ubiquitous access to chip design tools has caused a resurgence in very large-scale integration (VLSI) designs and smarter electronic design automation (EDA) tools. This means higher costs for rack space overages with potential service outages.
This two-part blog series will provide guidance on implementing IT resilience strategies. In Part II, we’ll explore the technical considerations related to architecture and patterns. It’s also sometimes mixed with concerns about highly publicized security or outage events. Architecture reviews. Customer challenges.
Consider engaging in a discussion with the CISO about the benefits of tiered security architectures and “ data bunkers ,” which can help retain large amounts of data and make it available immediately. The post 5 Questions to Ask Your CISO appeared first on Pure Storage Blog. If we are under attack, how will we communicate?
In part 2 of our three-part cloud data security blog series, we discussed the issue of complexity. Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. The post Cloud Data Security Challenges, Part 3: Getting Control appeared first on Pure Storage Blog.
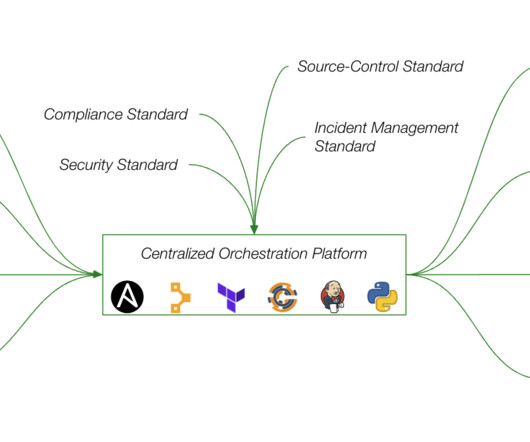
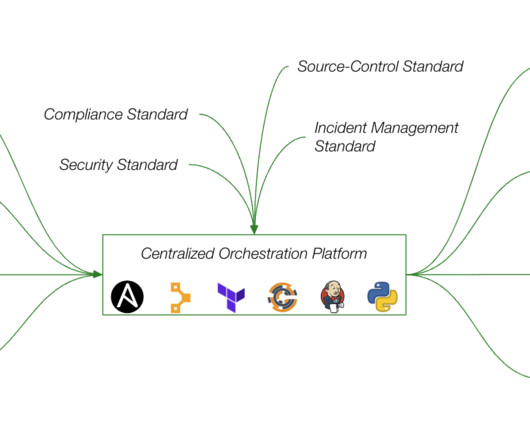
The recent global outage reminds us that identifying issues and their impact radius is just the first part of a lengthy process to remediation. This blog dives into the benefits and challenges of having a centralized automation practice to IT operations. See the diagram below for a sample architecture.
Second is a disturbing trend of late: targeting essential service providers that lead to massive outages and widespread disruptions. Learn more about how to design an airtight, hyper-accessible, and secure data backup architecture with Pure SafeMode snapshots. appeared first on Pure Storage Blog. sh=4401e30e5839.
by Blog Home Summary AMI 2.0 They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. The system can quickly detect outages and report them to the utility, leading to faster restoration of services. Utility companies can use AMI 2.0
FlashArray File Services Certified for SAP HANA by Pure Storage Blog SAP creates and manipulates an organization’s most sensitive customer, financial, and operational data. The post FlashArray File Services Certified for SAP HANA appeared first on Pure Storage Blog.
As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. Both dependencies might violate static stability, because we are relying on resources in our DR plan that might be affected by the outage we’re seeing. Conclusion.
A detailed discussion of Zero Trust is outside scope of the blog, but here’s an introduction pitched to the needs of BC practitioners. However, because setting it up involves rebuilding much of the organization’s network security architecture, implementing it is a serious burden and a major project, one that typically takes multiple years.
But even internally, an outage can be disastrous. The city had to spend $10 million on recovery efforts, not including the $8M in lost revenue from a two-week outage of bill payment systems and real estate transactions. Learn how a tiered backup architecture with a data bunker can set your recovery efforts up for success. .
If there are any issues with the fulfillment of our performance or capacity obligations, you can trust Pure to resolve this with our best-in-class NPS score of 83+ and our Evergreen™ and Evergreen architecture. Broken Subscriptions) appeared first on Pure Storage Blog. That’s outlined in our terms as: .
During an outage in the primary Region, Velero restores volumes from the latest snapshots in the standby cluster. refer to part two of our blog series for guidance on using APIs for cross-Region replication. Full documentation for cross-cluster replication is available in the OpenSearch documentation. or OpenSearch 1.1,
In this blog post series we’ll be discussing the different ways that you can improve the accuracy of Intelligent Alert Grouping for your specific needs. We might think in terms of thresholds where a service can budget for a given amount of latency or outage time, but it’s dependent services might have stricter requirements.
The process of indexing the data (merging the data, in particular) is quite computationally expensive on the Elasticsearch cluster and running it at a rate to repopulate large amounts of data will likely affect other indices on the cluster that may be running queries at the same time (if they were unaffected by the outage).
by Pure Storage Blog “Does Performance Through Failure Matter to You?” The folks over at XtremIO have been busy this holiday season, penning a nearly 2,000-word blog to make the argument for their scale-out architecture vs. dual-controller architectures. never having to ask for an outage window).
The largest hyperscale clouds have a highly redundant architecture that copies data in multiple places throughout its infrastructure. After all, while cloud outages aren’t very common, they do occur. Microsoft Azure, March 2020: Azure experienced a six-hour outage in the Eastern U.S. The cloud certainly has a lot going for it.
I saw the difference between a traditional architecture and a microservices architecture. The answer: The dev team was getting paged in the middle of the night to respond to production outages. Modern application architectures allow us to do that. Just like that, a switch went off in my head.
The recent global outage reminds us that identifying issues and their impact radius is just the first part of a lengthy process to remediation. This blog dives into the benefits and challenges of having a centralized automation practice to IT operations. See the diagram below for a sample architecture.
Simple Architecture, Simple Scale. Figure 2: NetBackup, FlashArray//C, and VMware architecture. If your environment suffers an outage, whether from a ransomware attack or another type of disaster scenario, your authorized administrator needs to contact Pure Customer Support to authenticate access. Format and mount the devices.
by Pure Storage Blog Recovery time objective (RTO) and recovery point objective (RPO) are two important concepts used in disaster recovery planning. RTO is the service level defining how long a recovery may take before unacceptable levels of damage occur from an outage. appeared first on Pure Storage Blog.
by Pure Storage Blog Recovery time objective (RTO) and recovery point objective (RPO) are two important concepts used in disaster recovery planning. RTO is the service level defining how long a recovery may take before unacceptable levels of damage occur from an outage. appeared first on Pure Storage Blog.
The True Power of Agile, Non-disruptive Data Storage by Pure Storage Blog Let’s face it: The world has a data problem. Platform software upgrades can get very complicated very fast and come with unexpected outages and downtime. The post The True Power of Agile, Non-disruptive Data Storage appeared first on Pure Storage Blog.
When critical applications suffer performance degradation—or worse yet, a full outage—engineers rush to find the (apparent) cause of the incident, such that they can remediate the issue as fast as possible. This is the first in a multi-part blog series. Stay inquisitive, my fellow detectives.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content