This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the ArchitectureBlog happily participated, we also made every effort to stay true to our channels original scope, and your readership this last year has proven that decision was the right one. What a winning combo!
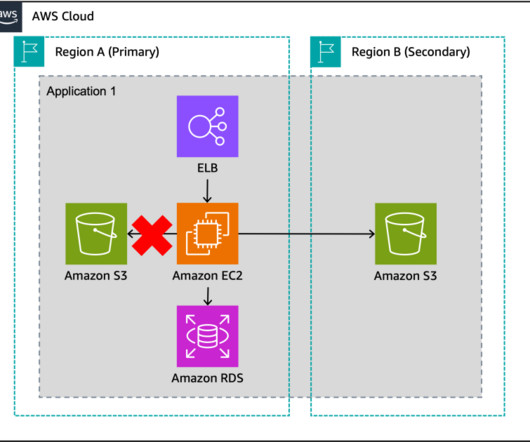
This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. Component-level failover Applications are made up of multiple components, including their infrastructure, code and config, data stores, and dependencies.
The Storage Architecture Spectrum: Why “Shared-nothing” Means Nothing by Pure Storage Blog This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. And just as important, why there is more to any product or platform than just architecture.
This blog post shows how to architect for disaster recovery (DR) , which is the process of preparing for and recovering from a disaster. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. All requests are now switched to be routed there in a process called “failover.”
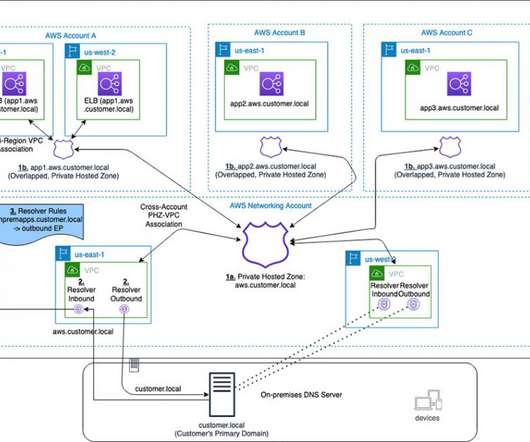
Route 53 Private Hosted Zones (PHZs) and Resolver endpoints on AWS create an architecture best practice for centralized DNS in hybrid cloud environment. This blog presents an architecture that provides a unified view of the DNS while allowing different AWS accounts to manage subdomains. Architecture Overview.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). DR implementation architecture on multi-Region active/passive workloads. Fail over with event-driven serverless architecture. This keeps RTO and RPO low.
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
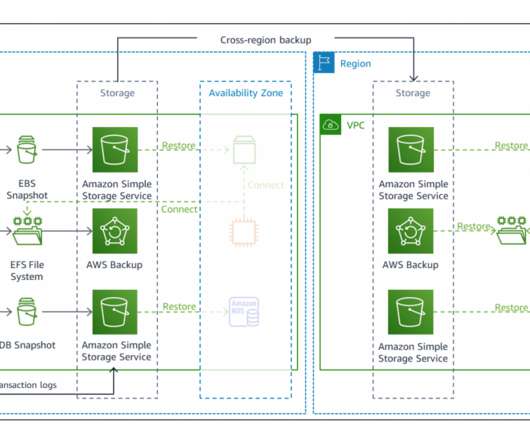
In a previous blog post , I introduced you to four strategies for disaster recovery (DR) on AWS. Failover and cross-Region recovery with a multi-Region backup and restore strategy. In Figure 5, we show a possible architecture for detecting and responding to events that impact your workload availability. Conclusion.
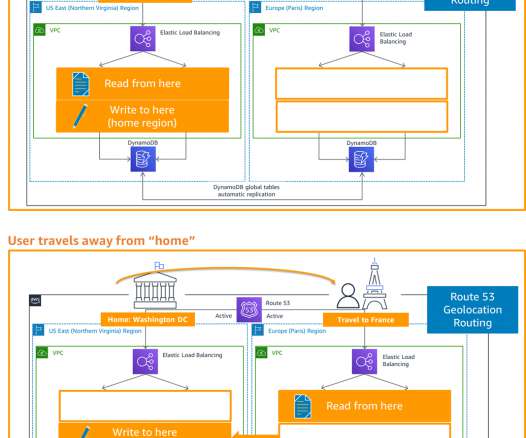
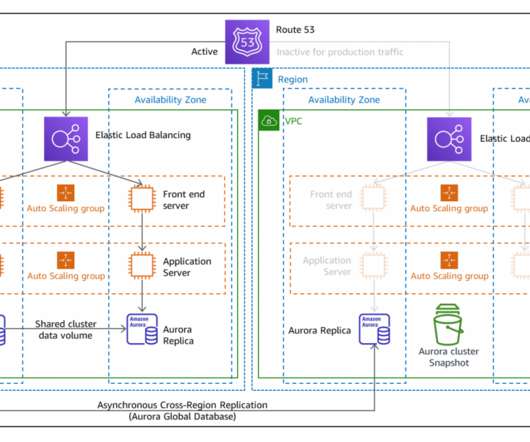
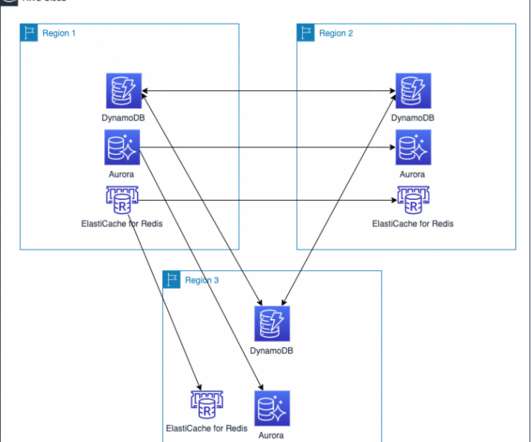
In my first blog post of this series , I introduced you to four strategies for disaster recovery (DR). The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. I use Amazon DynamoDB for the example architecture in Figure 2. DR strategies.
Mitigate Security Risks with a Connected-Cloud Architecture. With a connected cloud architecture, businesses can mitigate security risks for IP and chip design data. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns.
Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming. In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. Looking for more architecture content?
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover.
ZTNA vs. VPN by Pure Storage Blog Summary As data breaches become more common, organizations need a better way to protect their data. A zero trust network architecture (ZTNA) and a virtual private network (VPN) are two different solutions for user authentication and authorization. ZTNA requires additional account verification (e.g.,
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Purpose-built global database architecture. Ready to get started?
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. Fan-in deduplicates data across source arrays before sending it to the target, maximizing your storage efficiency.
by Pure Storage Blog Summary When reconsidering their VM strategies, many organizations might overlook the fact that legacy data storage could be making their VM problems worse. For example, legacy SAN/NAS architectures reliant on vendor-specific SCSI extensions or non-standardized NFSv3 implementations create hypervisor lock-in.
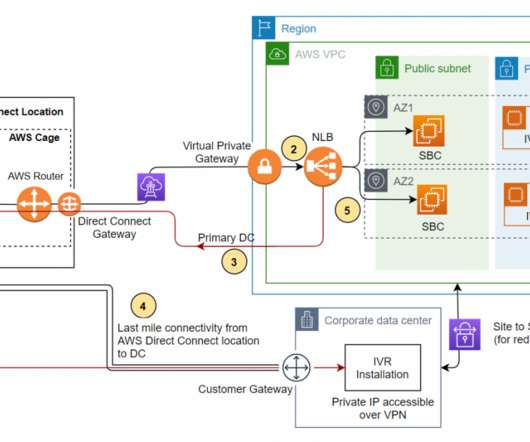
This architecture enables customers facing challenges of cost overhead with redundant Session Initiation Protocol (SIP) trunks for the DC and DR sites. Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. Conclusion.
Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover. The steps are either pre-action or post-action and can be either manual action or a script to execute steps during a failover. Figure 3: High-level solution architecture for protecting Azure VMs across two regions. .
Architecture overview. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Looking for more architecture content? Amazon EKS control plane. ElastiCache.
The unique architecture enables us to upgrade any component in the stack without disruption. . Pure Cloud Block Store removes this limitation with an architecture that provides high availability. You can update the software on controller 2, then failover so that it’s active. Visit the Azure Marketplace to learn more.
This final blog post in the one-to-many replication series will discuss how to leverage Zerto, a Hewlett Packard Enterprise company, to protect and migrate on-premises VMs to EC2 instances with one-to-many replication. This feature can greatly help solutions architects design AWS DR architectures (2).
At the end of November, I blogged about the need for disaster recovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. I covered this topic in more detail in my last blog post , but the highlights bear repeating in light of these recent outages. How Safe is the Cloud? It’s Complicated .
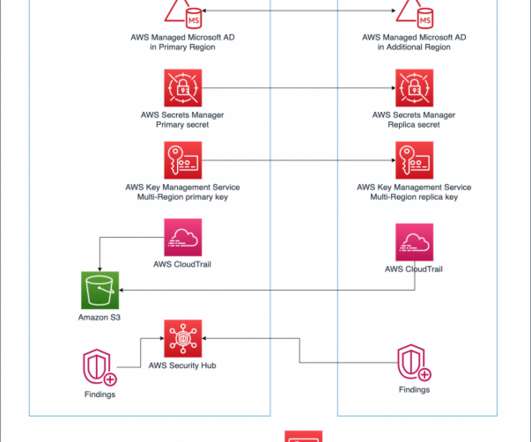
When designing a Disaster Recovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. Overview of architecture. In the following architecture, we show how you can protect domain-joined workloads in the case of a disaster. Walkthrough. Prerequisites.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment. You would just need to create the records and specify failover for the routing policy. or OpenSearch 1.1,
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. This brings two challenges: data consistency and complexity.
Fortifying Cyber Resilience: The Power of Defense-in-Depth from Pure Storage and Rubrik by Pure Storage Blog Summary Cyberattack vectors are evolving quickly and constantly. A new comprehensive reference architecture from Pure Storage and Rubrik provides a multi-layered approach that strengthens cyber resilience.
It employs a zero-trust architecture and hardened Linux virtual appliances that follow the principles of least privilege. Leverage the built-in features of Zerto Recovery Reports used during live and test failovers as well as Zerto Analytics to prove Service Level Agreements (SLAs) for auditing and compliance.
This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. The strategy outlined in this blog post addresses how to integrate AWS managed services into a single-Region DR strategy. Amazon RDS PostgreSQL.
Bogus Statements) by Pure Storage Blog (For the purposes of this post, “B.S.” Item #3: “ Active/Active Controller Architecture”¹⁴ Is a Good Thing We see this B.S. This really matters in the performance during a path failover, controller failure, or controller upgrade. Bogus Statements) appeared first on Pure Storage Blog.
Mitigate Security Risks with a Connected-Cloud Architecture. With a connected cloud architecture, businesses can mitigate security risks for IP and chip design data. Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source.
In part 2 of our three-part cloud data security blog series, we discussed the issue of complexity. Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
It’s not always an easy engineering feat when there are fundamental architectural changes in our platforms, but it’s a core value that you can upgrade your FlashArrays without any downtime and without degrading performance of business services. . The only observable activity is path failovers, which are non-disruptively handled by MPIO.
How to Accelerate MySQL Workloads by Pure Storage Blog This article on MySQL Workloads was coauthored by Andrew Sillifant and Nihal Mirashi. In a previous blog post, I covered 4 common MySQL issues and how to solve them. Single-command failover. The post How to Accelerate MySQL Workloads appeared first on Pure Storage Blog.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 1 of 4 by Pure Storage Blog In this four-part series, I’ll explore using ActiveDR ™ for managing Oracle disaster recovery. So let’s get started and take a look at a logical architecture diagram of what we’re about to build.
It presents an opportunity to redefine your architecture. ActiveCluster provides seamless failover to deliver zero to near-zero RPO and RTO. . The post Improve Business Continuity with Virtualization appeared first on Pure Storage Blog. The explosion of digital business has exacerbated the need for an infrastructure rehaul.
Figure 1: Docker architecture vs. VM architecture. However, Docker containers (with VMs) are better for developing and deploying newer, cloud-native applications on a microservices architecture. Enterprise-grade resiliency with automated failover and self-healing data access integrity. Source: Docker.
Why Some Customers Have All Writes: 1% In some mirrored environments, you might have the mirrored storage for failover only. Here are a few previous blog posts on the topic of benchmarking: What Is SQL Server’s IO Block Size? Here are a few previous blog posts on the topic of benchmarking: What Is SQL Server’s IO Block Size?
Delivering Low-latency Analytics Products for Business Success by Pure Storage Blog This article on low-latency analytics initially appeared on Kirk Borne’s LinkedIn. What Is a Non-Disruptive Upgrade (NDU)? – “Baked into the architecture of FlashArray™.” It has been republished with the author’s credit and consent.
In particular, that means backup and disaster recovery (DR) specialists are needed that can advise on data protection strategy, architecture, recovery options, compliance and a whole lot more. An IT pro might do a failover or two in their entire career – we handle multiple ones on a monthly basis.
by Pure Storage Blog When the unexpected happens, poorly prepared businesses run the risk that everything could come to a screeching halt. This typically involves detailed technical strategies for system failover, data recovery, and backups. appeared first on Pure Storage Blog.
3 Reasons Software Defines the Best All-Flash Array by Pure Storage Blog This article was originally published in 2012. As we have remarked before f lash memory is so radically different from hard drives that it requires wholly new software controller architecture. Flash-centric storage will be no different. It is self-healing.
by Pure Storage Blog When the unexpected happens, poorly prepared businesses run the risk that everything could come to a screeching halt. This typically involves detailed technical strategies for system failover, data recovery, and backups. appeared first on Pure Storage Blog.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content