This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
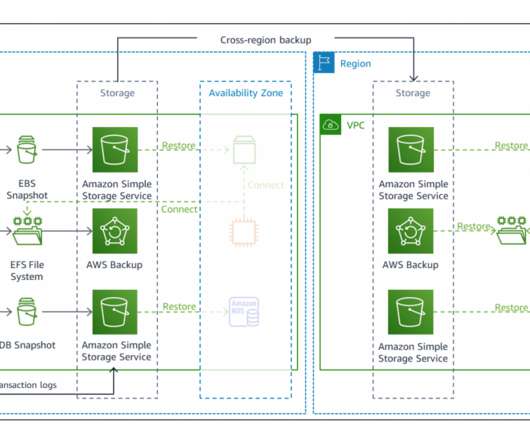
Figure 2 shows the four strategies for DR that are highlighted in the DR whitepaper. If data needs to be restored from backup, this can increase the recovery point (and data loss). If such a disaster results in deleted or corrupted data, it then requires use of point-in-time recovery from backup to a last known good state.
By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions. DR strategies: Choosing backup and restore. Implementing backup and restore.
Backup technology has existed as long as data has needed to be recovered. We’ve seen countless iterations of backup solutions, media types, and ways of storing backup data. This last decade, many new backup tools have come out. Backup Appliances. Software-based Backup.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Earlier, we were able to restore from the backup but wanted to improve availability further. Current Architecture with improved resiliency and standardized observability.
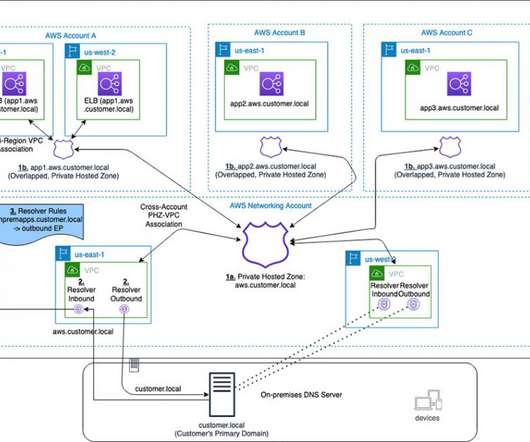
Route 53 Private Hosted Zones (PHZs) and Resolver endpoints on AWS create an architecture best practice for centralized DNS in hybrid cloud environment. This blog presents an architecture that provides a unified view of the DNS while allowing different AWS accounts to manage subdomains. Architecture Overview.
One of the most common ransomware attacks we see today is the destruction of backup data. The ability to recover quickly from this sort of destructive attack is a huge question mark for traditional backup systems or any purpose-built backup solution. Figure 1: FlashRecover//S architecture overview.
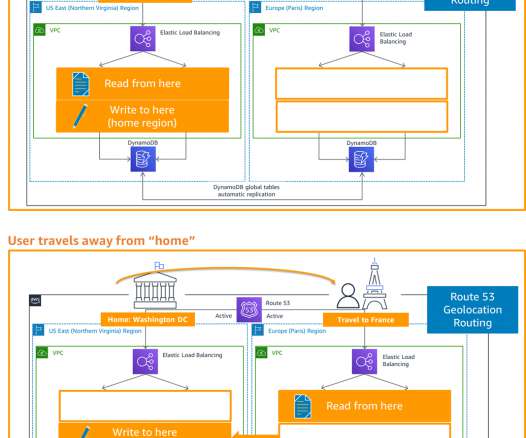
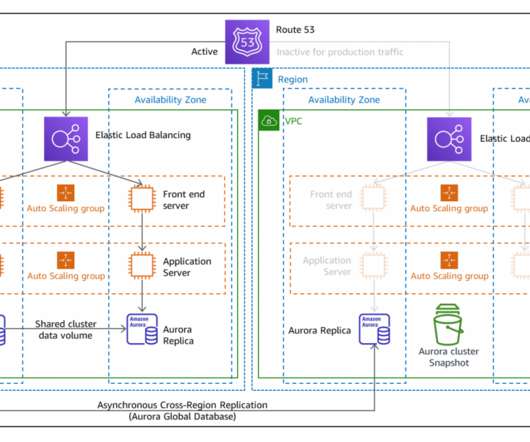
My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. I use Amazon DynamoDB for the example architecture in Figure 2.
Then we explored the backup and restore strategy. In addition to replication, both strategies require you to create a continuous backup in the recovery Region. Backups are necessary to enable you to get back to the last known good state. Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud.
It is important to note that an Oracle database must be placed into hot backup mode to achieve database application consistency. Hot backup mode freezes the system change number (SCN) in the redo logs, and it gives Oracle a specific application-consistent location to which to recover.
The Benefits of Pure Storage Integration with Veeam Agent-less application consistent array-based snapshot backups Veeam coordinates the execution of API calls to the hypervisor and guest OS, like VADP and VSS, eliminating the need for agents to be installed on a VM. This is the bar both looked to build upon with our integration efforts.
Check out the IDC whitepaper The State of Ransomware and Disaster Preparedness. The native Kubernetes solution drives a “data protection as code” strategy, integrating backup and disaster recovery operations into the application development lifecycle from day one. Backup to a Cloud Bucket. CDP-As-Code.
The Availability and Beyond whitepaper discusses the concept of static stability for improving resilience. In the simplest case, we’ve deployed an application in a primary Region and a backup Region. In an event that triggers our DR plan, we manually or automatically switch the DNS records to direct all traffic to the backup Region.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content