This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Most organizations believe they’re prepared for ransomware attacks with a simple strategy: maintain good backups and use them to restore systems if cybercriminals encrypt their data. Recent research from IDC reveals that in 2023, more than half of all ransomware attacks included attempts to compromise backup systems.
This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. The component-level failover strategy helps you recover from individual component impairments.
All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. If data needs to be restored from backup, this can increase the recovery point (and data loss).
DR strategies: Choosing backup and restore. As shown in Figure 1, backup and restore is associated with higher RTO (recovery time objective) and RPO (recovery point objective). However, backup and restore can still be the right strategy for your workload because it is the easiest and least expensive strategy to implement.
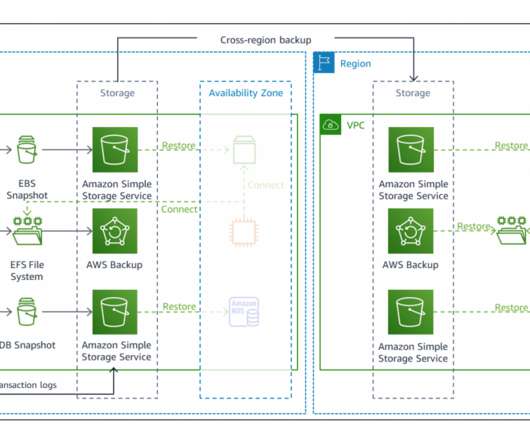
In part two, we introduce a multi-Region backup and restore approach. Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1.
Backup technology has existed as long as data has needed to be recovered. We’ve seen countless iterations of backup solutions, media types, and ways of storing backup data. This last decade, many new backup tools have come out. Backup Appliances. Software-based Backup.
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. I am excited to tell you about some of the latest updates to Zerto, HPE GreenLake for Disaster Recovery, and HPE GreenLake for Backup and Recovery.
Solutions Review’s listing of the best backup and disaster recovery companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. Though backup practices have existed for years, there have been major changes and challenges in the space over the last two years.
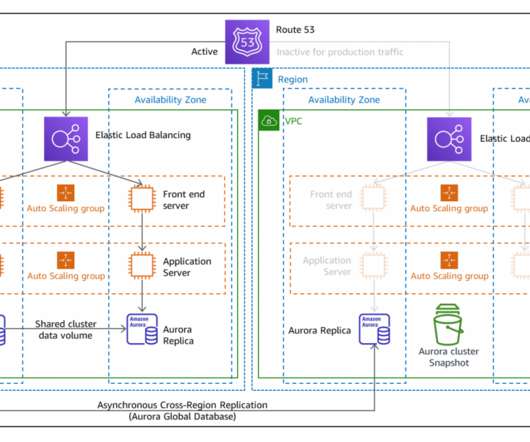
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). DR implementation architecture on multi-Region active/passive workloads. Fail over with event-driven serverless architecture. This keeps RTO and RPO low.
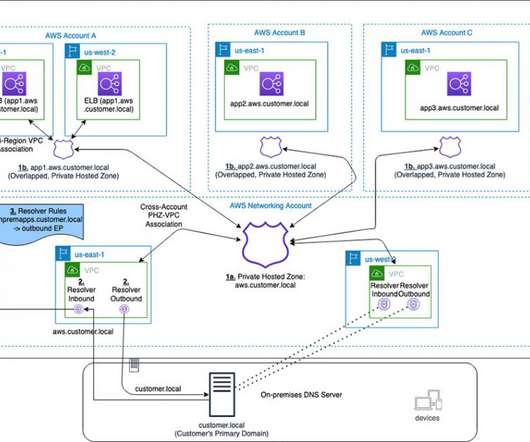
Route 53 Private Hosted Zones (PHZs) and Resolver endpoints on AWS create an architecture best practice for centralized DNS in hybrid cloud environment. This blog presents an architecture that provides a unified view of the DNS while allowing different AWS accounts to manage subdomains. Architecture Overview.
Solutions Review’s Tim King compiled this roundup of 45 World Backup Day quotes from 32 experts for 2023, part of our ongoing coverage of the enterprise storage and data protection market. World Backup Day quotes have been vetted for relevance and ability to add business value.
The Best Backup and Disaster Recovery Tools for Healthcare. With an extensive range of supported environments and integration with copy file sync and share services, organizations can replace multi-vendor piecemeal backup solutions with an all-in-one appliance. In 2020, Barracuda acquired Fyde for an undisclosed amount. Cobalt Iron.
Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. New Backup & Restore Functionality in Zerto 9.5: Instant File Restore for Linux. Get Your Files Back! Avoid Sneaky Infrastructure Meltdowns.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. Minimum business continuity for failover. Earlier, we were able to restore from the backup but wanted to improve availability further. Predictive scaling for EC2.
Before you know it, your fleet has become a many-headed monster of disparate storage arrays, with siloed data and a complex web of backup jobs. Fan-in unifies backup tasks, replication jobs, and access control under one roof, streamlining your workflow. Enter your knight in shining armor—snapshot consolidation via fan-in replication.
Failover routing is also automatically handled if the connectivity or availability to a bucket changes. It can even be used to sync on-premises files stored on NFS, SMB, HDFS, and self-managed object storage to AWS for hybrid architectures. Copying backups. Backup copy times will vary depending on size and change rates.
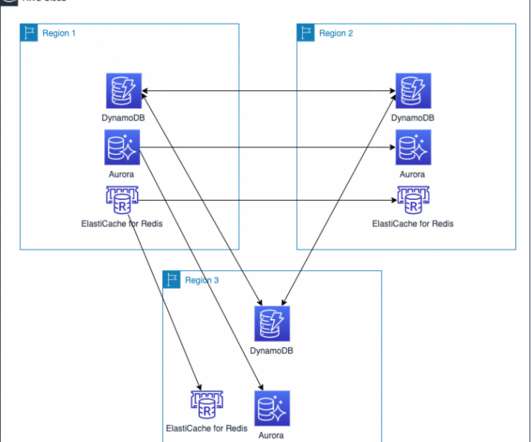
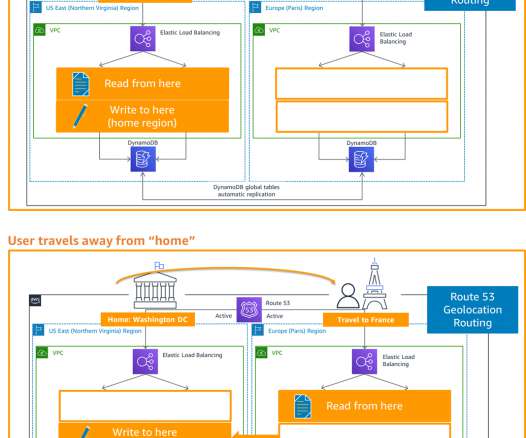
My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. I use Amazon DynamoDB for the example architecture in Figure 2.
You need a robust backup plan and multiple channels of communication and response. This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover.
For example, legacy SAN/NAS architectures reliant on vendor-specific SCSI extensions or non-standardized NFSv3 implementations create hypervisor lock-in. A unified storage platform supporting vVols with per-VM IOPS limits and failover priorities reduces manual intervention and automates these processes to free up IT resources (e.g.,
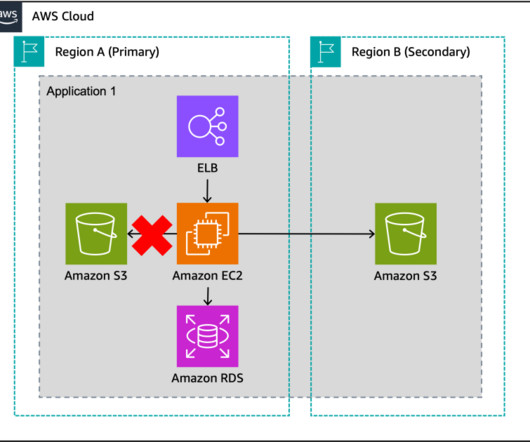
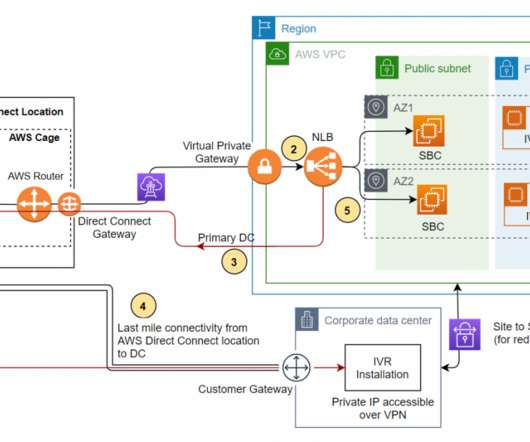
We address a scenario in which you are mandated to host the workload on a corporate data center (DC), and configure the backup site on Amazon Web Services (AWS). Since the primary objective of a backup site is disaster recovery (DR) management, this site is often referred to as a DR site. Disaster Recovery on AWS.
Application-consistent points in time will be indicated as a checkpoint in the Zerto journal of changes to ensure visibility when performing a move, failover, or failover test in Zerto. It is important to note that an Oracle database must be placed into hot backup mode to achieve database application consistency.
In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns. Resilience is an overarching concern that is highly tied to other architecture attributes. Let’s evaluate architectural patterns that enable this capability.
Then we explored the backup and restore strategy. The left AWS Region is the primary Region that is active, and the right Region is the recovery Region that is passive before failover. In addition to replication, both strategies require you to create a continuous backup in the recovery Region. Pilot light DR strategy.
Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming. Applications that have multiple possible origins, such as across Regions, can use CloudFront origin failover to automatically fail over the origin. Ready to get started?
Data protection is a broad field, encompassing backup and disaster recovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disaster recovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
Acronis provides backup, disaster recovery, and secure access solutions. The provider’s flagship product, Acronis True Image, delivers backup, storage, and restoration capabilities. Acronis ’ Disaster Recovery as a Service ( DRaaS ) solutions address IT requirements for backup, disaster recovery, and archiving.
Acronis provides backup, disaster recovery, and secure access solutions. The provider’s flagship product, Acronis True Image, delivers backup, storage, and restoration capabilities. Acronis ’ Disaster Recovery as a Service ( DRaaS ) solutions address IT requirements for backup, disaster recovery, and archiving.
Real-time replication and automated failover / failback ensure that your data and applications are restored quickly, minimizing downtime and maintaining business continuity. By optimizing storage utilization and eliminating the need for redundant backup hardware, Zerto helps you achieve significant cost savings.
In short, the sheer scale of the cloud infrastructure itself offers layers of architectural redundancy and resilience. . We accomplish this by automating and orchestrating snapshots and replication within EBS to efficiently move data across regions and allow rapid failover between regions in a disaster event.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
World Backup Day was first introduced in 2011. It was easy enough back then; IT just had to backup to tape at night, keep a copy or two around for a month and send another offsite for archival storage. Backup has seen great advancement – even the standard 3-2-1 rule has added a digit or two. But those times are long gone.
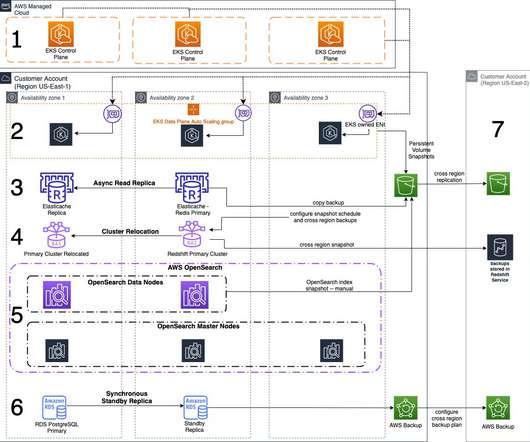
This will minimize maintenance and operational overhead, create fault-tolerant systems, ensure high availability, and protect your data with robust backup/recovery processes. This example architecture refers to an application that processes payment transactions that has been modernized with AMS. Amazon EKS control plane.
Arcserve Platform: Arcserve Continuous Availability Description: Arcserve offers several different backup products, including Arcserve Unified Data Protection (UDP), Arcserve Replication and High Availability, Arcserve UDP Cloud Direct, UDP Cloud Hybrid, and a legacy offering.
A new comprehensive reference architecture from Pure Storage and Rubrik provides a multi-layered approach that strengthens cyber resilience. This evolving threat landscape requires a more sophisticated, automated, cyber-resilient architecture to ensure comprehensive data security.
In part two of this series, we introduced a DR concept that utilizes managed services through a backup and restore strategy with multiple Regions. Amazon Route53 – Active/Passive Failover : This configuration consists of primary resources to be available, and secondary resources on standby in the case of failure of the primary environment.
The unique architecture enables us to upgrade any component in the stack without disruption. . Pure Cloud Block Store removes this limitation with an architecture that provides high availability. You can update the software on controller 2, then failover so that it’s active.
A great way to make sure it’s protected no matter what happens is through solutions like Pure Storage ® SafeMode ™, a high-performance data protection solution built into FlashArray™ that provides secure backup of all data. Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize.
The native Kubernetes solution drives a “data protection as code” strategy, integrating backup and disaster recovery operations into the application development lifecycle from day one. Backup to a Cloud Bucket. The Zerto for Kubernetes failover test workflow can help check that box.
It’s also where you can launch, deploy, and manage HPE GreenLake for Disaster Recovery, as well as other cloud services like HPE GreenLake for Backup and Recovery, networking, storage, compute, and more. Flexible architecture: sits at the hypervisor level and is hardware-, platform-, and storage-agnostic.
This includes developing and testing DR plans, implementing backup and recovery solutions, and providing training for staff on how to respond to a disaster. This eliminates the need for manual intervention and reduces the risk of human error when initiating a failover.
In this feature, Zerto (HPE) ‘s Director of Technical Marketing Kevin Cole offers commentary on backup, disaster recovery, and cyber recovery and supporting the need for speed. Longer downtimes result in increased loss and recovering quickly should be top of mind. How do backup, disaster recovery, and cyber recovery differ?
Supply chain resiliency can be defined as understanding the components of your supply chain for all critical business processes, as well as having backups for each component and a clearly defined plan for switching to a backup. The first step is to document critical business processes and the suppliers used to support each process.
enables customers to deploy a multitarget high availability environment in which HANA operates on a primary node and, in the event of a failure or disaster, can failover to a secondary and/or a tertiary target node located in a different cloud Availability Zone or on-premises disaster recovery location. Read on for more. [ Read on for more.
Top Storage and Data Protection News for the Week of September 27, 2024 Cayosoft Secures Patent for Active Directory Recovery Solution Cayosoft Guardian Forest Recovery’s patented approach solves these issues by functioning as an AD resilience solution rather than a typical backup and recovery tool.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content