This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
government agencies to seamlessly protect, migrate, and recover their critical applications within the secure, compliant environment of AWS GovCloud. This new availability enables U.S. states Christina Rauscher, Global Leader of Alliances at Zerto. government agencies, making it an ideal environment for managing sensitive workloads.
By Debbie OBrien, Chief Communications Officer and Vice President of Global Social Impact at PagerDuty In today’s digitally-connected world, IT outages can be inconvenient at best and extremely challenging at worst. Whether its tomorrow or one year from now, IT outages are no longer a matter of “if” but “when.”
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
How to Set Up a Secure Isolated Recovery Environment (SIRE) by Pure Storage Blog If youve suffered a breach, outage, or attack, theres one thing you should have completed and ready to go: a secure isolated recovery environment (SIRE). Its all about speed. Their focus is speed: Is the business back up and running yet?
Texas winter storm (2021): An energy company in Texas maintained critical operations by using remote data centers and cloud services to ensure data availability despite local power outages. Identify key systems: Prioritize the most critical data and applications for replication.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. Redundancy ensures resilience by maintaining connectivity during outages. A low RTO ensures that organizations maintain productivity, customer trust, and compliance with regulatory requirements.
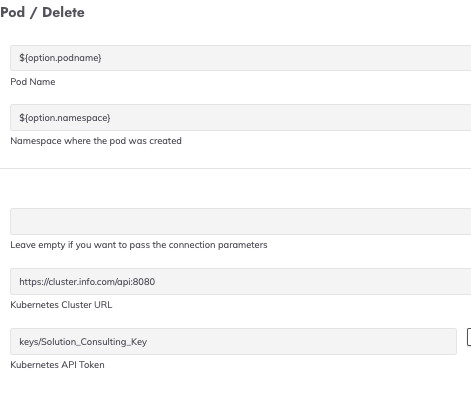
Kubernetes Pod Actions Description: Whilst in Kubernetes environments, a desired state is usually well maintained, occasionally restarting pods can be necessary to refresh the application state or apply new configurations. This automation task restarts pods to ensure they connect to the most updated environment. — 10.
Eradicating Change Management Outages with Pure Professional Services by Pure Storage Blog Executives who invest in Pure Storage technologies don’t do so just for the advanced features—they’re also looking for the assurance of uninterrupted operations. What Are Change Management Outages?
Work with legal counsel to create an incident response plan that aligns with applicable laws. After a breach, outage, or data theft, the first priority is to get systems back online as quickly as possible. Stay informed about changes in regulations to ensure ongoing compliance.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. Moreover, cloud-services providers are themselves susceptible to outages and failed recoveries.
An IT disaster that leaves an organization without its data and applications can be crippling, if not fatal. The world has become increasingly reliant on access to data and digital services, and prolonged outages may cost your organization lost business, impaired productivity and irreparable reputation damage.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or applicationoutages.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1 Figure 2.2.
This system would also assist in less obvious impacts, such as a computer outage affecting specific applications. These should be aligned across the organisation, ensuring that one department’s ‘amber’ does not correspond to another’s ‘green’. Below is an example, illustrating how the system might work in practice.
With the global surge in cybercrime—particularly ransomware attacks —and occasional outages of cloud services , enterprise risk management is just the latest initiative that needs attention. The ripple effects lasted 4400% longer than the outage itself. Customers, as well as internal team members, were severely impacted.
Recovering the virtual instances that make up your applications from the cloud is an essential part of modern business continuity strategies. Using cloud disaster recovery services, organizations can quickly restore critical workloads, applications, and databases to resume operations. What is a cloud recovery site?
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Alternatively, shut down application servers and stop remote database access. . Re-enable full access to the database and application.
IT resilience refers to the ability to continuously keep essential IT systems and applications up and running despite disasters and disruptions. An effective IT resilience strategy focuses on delivering an ‘always-on’ customer experience regardless of unplanned outages and changes to IT infrastructure. What Is IT Resilience?
In this post, we start by discussing the threats against applications running as Kubernetes clusters. We’ll cover the threats against applications running as Kubernetes clusters and how Zerto for Kubernetes and its one-to-many replication functionality protects against them. They’re managed by the Kubernetes control plane.
IT pros and organizations are starting to realize the importance of protecting their Kubernetes applications. This includes human errors, outages, but most importantly: ransomware. . Ransomware attacks are no longer specific to applications run on physical or virtual servers. New capabilities include: . and Rook Ceph .
Cloud hosting means placing compute resourcessuch as storage, applications, processing, and virtualizationin multi-tenancy third-party data centers that are accessed through the public internet. Service providers offer resources such as applications, compute, and storage through free or pay-per-usage models. What Is Cloud Storage?
What really happens when the cloud goes down and how do you protect your critical business applications in such an event? Learn about the anatomy of a cloud outage and best practices to help your business ensure maximum uptime against all odds.
So, as part of the BCMS, youre looking at things like maximum acceptable outages [MAOs] and recovery time objectives [RTOs]. Maybe it runs a specific application. You then ask what that application facilitates from a business perspective how does it help your companys bottom line?
While an emergency can be many things a winter storm , natural disaster, power outage, or man-made incident streamlining and centralizing communications can play a major role in improving the outcome of an event. Our customers needed a better way to manage the lifecycle of an emergency , said Brian Cruver , CEO of AlertMedia.
While an emergency can be many things – a winter storm , natural disaster, power outage, or man-made incident – streamlining and centralizing communications can play a major role in improving the outcome of an event. said Brian Cruver , CEO of AlertMedia.
This could halt operations, prevent employees from accessing essential applications and delay customer transactions. Even a one-hour outage can lead to significant revenue loss and damage to the companys reputation. System outages or slow response times can lead to dissatisfaction, negative reviews and loss of business.
When critical applications suffer performance degradation—or worse yet, a full outage—engineers rush to find the (apparent) cause of the incident, such that they can remediate the issue as fast as possible. Grab all the evidence: Capturing application state for post-incident forensics. Stay inquisitive, my fellow detectives.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery point objective (RPO) : Minimizing data loss .
Follow these seven steps to implement a BC strategy that can help you swiftly recover your business processes in the event of an outage. Applications and systems used and their importance. Functional importance of applications in terms of IT. Interdependencies between processes.
With recovery granularity of seconds, Zerto effectively minimizes data loss and significantly mitigates the impact of outages and disruptions on your organization. Application-centric protection and recovery: Zerto treats applications and workloads as a single cohesive unit.
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
We know our customers want to work where they are, so beyond our own platform, we also prioritize making critical incident data available on other core applications that our customers use, including: ITSM: Bidirectional integrations with ServiceNow and Jira means customers can view important incident data directly in the preferred system of record.
If you’ve suffered a breach, outage, or attack, there’s one thing you should have completed and ready to go: a staged recovery environment (SRE). To stage and orchestrate the reintroduction of critical applications. Work with business stakeholders to prioritize application recovery needs to appropriately size the environment.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
In an age when ransomware attacks are common occurrences, simply having your systems, applications, and data backed up is not enough to ensure your organization is able to recover from a disaster. Remember, after an outage, every minute counts…. As a result, they aren’t able to recover as fast as needed.
SRE : Automate the full journey of an event by building auto-remediation or “human in the middle” automation where applicable. This reduces MTTR, risk, and cost to the business as well as mitigate burnout on first-line response teams. This reduces MTTR and preserves SRE time for valuable initiatives like scaling automation across more teams.
As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. In the simplest case, we’ve deployed an application in a primary Region and a backup Region. Simple Regional failover scenario using Route 53 Application Recovery Controller.
Major incident management and cyber risk : with the rise in digital service outages, data breaches, and ransomware attacks, seamless orchestration of security, IT teams, business processes, and tool integration is vital for reducing MTTR and swiftly restoring services.
Indeed, besides any business’ need to be able to cope with natural disasters or planned outages (maintenance, etc.), As such, you need a data protection management and recovery solution that seamlessly protects your data and workloads across multiple solutions, applications, and environments. What Is Cyber Resilience?
It’s likely that your IT environment changes often during the year as you add or upgrade applications, platforms, and infrastructure. Instead, you may be able to run a test on the recovery of an individual application once a week or every other week. How the Zerto Platform Can Help with Disaster Recovery Testing.
Educators need their applications available to reliably teach to our children, while constituents need access to emergency, financial and social services in their most critical time of need. An IT outage of any sort can adversely impact people’s lives.
Despite basic out-of-the-box protection from SaaS vendors, data residing in SaaS applications is your responsibility, not the vendor’s. This data is exposed to potential risks like outages, accidental deletion, and ransomware attacks that can lead to loss or downtime. Why Monitoring and Analyzing your SaaS Backup Data is important?
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content