This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability. Texas winter storm (2021): An energy company in Texas maintained critical operations by using remote data centers and cloud services to ensure data availability despite local power outages.
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. Redundancy ensures resilience by maintaining connectivity during outages. BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow.
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
Recovering the virtual instances that make up your applications from the cloud is an essential part of modern business continuity strategies. Using cloud disaster recovery services, organizations can quickly restore critical workloads, applications, and databases to resume operations. Ensuring frequent backups with low RPOs.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Learn more about the PagerDuty Operations Cloud platform and how we can help teams like yours stay ahead of outages by taking this product tour.
Customers only pay for resources when needed, such as during a failover or DR testing. This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. JetStream replicates VMs and data into blobs, and compute resources (hosts) can be allocated on demand on failover.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery point objective (RPO) : Minimizing data loss . Add Orchestration for Your DR Plan.
In this post, we start by discussing the threats against applications running as Kubernetes clusters. We’ll cover the threats against applications running as Kubernetes clusters and how Zerto for Kubernetes and its one-to-many replication functionality protects against them. They’re managed by the Kubernetes control plane.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community. power outages, email outages, etc).
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1
IT resilience refers to the ability to continuously keep essential IT systems and applications up and running despite disasters and disruptions. An effective IT resilience strategy focuses on delivering an ‘always-on’ customer experience regardless of unplanned outages and changes to IT infrastructure. What Is IT Resilience?
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
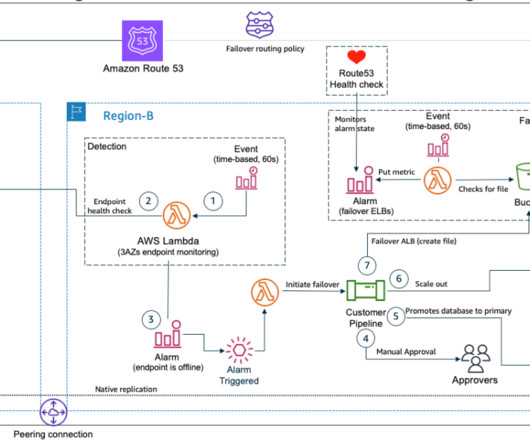
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment.
Educators need their applications available to reliably teach to our children, while constituents need access to emergency, financial and social services in their most critical time of need. An IT outage of any sort can adversely impact people’s lives.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
Step 6: Test the Plan – Use scheduled power outages or major upgrades as a chance to test the plan. You can recover from a failure by using clustering software to failoverapplication operation from a primary server node to a secondary server node over a LAN. RTO is the maximum tolerable length of time of an outage.
Here, we delve into HA and DR, the dynamic duo of application resilience. High Availability is the ability of an application to continue to serve clients who are requesting access to its services. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
It’s likely that your IT environment changes often during the year as you add or upgrade applications, platforms, and infrastructure. Instead, you may be able to run a test on the recovery of an individual application once a week or every other week. How the Zerto Platform Can Help with Disaster Recovery Testing.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . The problem is that most businesses don’t know how to protect their containerized applications. According to Cybersecurity Insiders’ 2022 Cloud Security Report : .
Approaching maintenance in this way allows your organization to be prepared for planned outages within your infrastructure, including patch installation, security updates, and service packs. When using an off-site secondary server, your RTO will be restricted to the amount of time it takes to failover from one server to the other.
Closely aligned with a data center strategy should be a holistic BCDR strategy that considers all types of risks (system failure, natural disaster, human error or cyberattack) and outage scenarios, and provides plans for mitigation with minimal or no impact to the business. Some of them use manual runbooks to perform failover/failbacks.
As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. It is a monolithic application (application server and web server) that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance. The monolith application is tightly coupled with the database.
The cloud providers have no knowledge of your applications or their KPIs. Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. This dependence has brought risk. How should a team handle an incident that lies with an upstream provider?
Part 1 : Configure ActiveDR and protect your DB volumes (why & how) Part 2 : Accessing the DB volumes at the DR site and opening the database Part 3 : Non-disruptive DR drills with some simple scripting Part 4 : Controlled and emergency failovers/failbacks In Part 1, we learned how to configure ActiveDR™. Promote the Oracle-DR pod.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. The Best Data Protection Software.
Synchronous replication is mainly used for high-end transactional applications that require instant failover if the primary node fails. If there’s an accident or outage, then transactions and data that aren’t replicated at the time of the incident will be lost, and data in secondary storage may not always be current.
As generative AI applications like chatbots become more pervasive, companies will train them on their troves of internal data, unlocking even more value from previously untapped information. The result is that large sections of corporate datasets are now created by SaaS applications.
References to Runbooks detailing all applicable procedures step-by-step, with checklists and flow diagrams. RTOs and RPOs guide the rest of the DR planning process as well as the choice of recovery technologies, failover options, and data backup platforms. References to Crisis Management and Emergency Response plans.
Zerto, a Hewlett Packard Enterprise company, empowers customers to run an always-on business by simplifying the protection, recovery, and mobility of on-premises and cloud applications. Users can now easily protect workloads between regions within Azure for in-cloud protection against regional outages and other disruptions like cyberattacks.
IT organizations have mainly focused on physical disaster recovery - how easily can we failover to our DR site if our primary site is unavailable. First, which is much more easily obtained, is to host some applications in one cloud platform and other applications in another cloud platform.
In fact, over the course of a 3-year period, 96% of businesses can expect to experience at least one IT systems outage 1. Unexpected downtime can be caused by a variety of issues, such as power outages, weather emergencies, cyberattacks, software and equipment failures, pandemics, civil unrest, and human error.
And many have chosen MySQL for their production environments for a variety of use cases, including as a relational database or as a component of the LAMP web application stack. But, because database applications like MySQL can be particularly demanding, it’s important to ensure the right resources are allocated to each virtual machine.
You also need various applications to connect with your customers, vendors, and employees. They can set up automated failovers that will automatically shift workloads from one server or data center to another in case the main one fails or crashes unexpectedly. For one, you need technology to be able to manage your operations with ease.
The cloud providers have no knowledge of your applications or their KPIs. Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. This dependence has brought risk. How should a team handle an incident that lies with an upstream provider?
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Learn more about the PagerDuty Operations Cloud platform and how we can help teams like yours stay ahead of outages by taking this product tour.
This key design difference makes them well-suited to very different business functions, applications, and programs. Flash storage can offer an affordable and highly consistent storage solution for relational databases as they grow and support more cloud-based modern applications’ persistent storage needs. Efficiency. Consistency.
Alternatively, firms could manually disable a machine or application or create a PagerDuty test incident to trigger an outage and then practice their response procedures. Incident simulation : Practice, practice, practice! PagerDuty Automation capabilities could be used to initiate a simulated incident.
Application: Predictive analytics enables organizations to rapidly assess risks and proactively implement measures to mitigate the impact of potential disruptions. Application: In the event of a cybersecurity breach, AI automates the identification, containment, and eradication of threats, reducing response time.
Such outages can cripple operations, erode customer trust, and result in financial losses. How to Build Resilience against the Risks of Operational Complexity Mitigation: Adopt a well-defined cloud strategy that accounts for redundancy and failover mechanisms.
Despite the added complexity of running different workloads in different clouds, a multicloud model will enable companies to choose cloud offerings that are best suited to their individual application environments, availability needs, and business requirements. ” Companies Will Reconsider On-Prem Data Centers in Favor of Cloud.
In this post, we explore how one of our customers, a US-based insurance company, uses cloud-native services to implement the disaster recovery of 3-tier applications. At this insurance company, a relevant number of critical applications are 3-tier Java or.Net applications.
Zerto In-Cloud for AWS brings reliability and speed to the protection of enterprise AWS applications with simple automated workflows for failover, recovery, and testing. Get Zerto In-Cloud for AWS on the AWS Marketplace today.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content