This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy.
As data proliferates in the information age, data protection becomes more and more important. The growing need for applications to always be available eventually created a demand for recovery faster than traditional backups could provide. But for data and applications critical to operating a business, lower RPOs and RTOs are needed.
Growing in both volume and severity, malicious actors are finding increasingly sophisticated methods of targeting the vulnerability of applications. Victims are either forced to pay the ransom or face total loss of business-critical applications. by protecting any application using continuous data protection (CDP).
Recovering the virtual instances that make up your applications from the cloud is an essential part of modern business continuity strategies. Using cloud disaster recovery services, organizations can quickly restore critical workloads, applications, and databases to resume operations. Ensuring frequent backups with low RPOs.
Database contents change depending on the applications they serve, and they need to be protected alongside other application components. These databases leverage a Structured Query Language (SQL) in order to organize, manage, and relate with the information stored.
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. See more information on myZerto. Check out our upcoming webinar on December 14th for more information on what’s new with HPE and Zerto.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Guided remediation capabilities , like Incident Roles and Tasks, eliminate guesswork from the response process, so teams can coordinate and act faster.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. To identify potential business impact, ask yourself questions like: Which applications are most important? What virtualized infrastructure makes up those applications?
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover.
In this blog post, we’ll explore key considerations to help you make an informed decision when selecting a DRaaS provider. Because it replicates only the changed information (rather than the entire application), hypervisor-based replication doesn’t impact VM performance. This is true continuous data protection.
Zerto, a Hewlett Packard Enterprise company, empowers customers to run an always-on business by simplifying the protection, recovery, and mobility of on-premises and cloud applications. You can try and buy Zerto with the same confidence and ease that comes with your other Azure-native applications. Why Go through the Azure Marketplace?
The lab exercises allowed them to install Zerto, pair production and recovery sites, restore files and folders, perform test and live failovers, and restore VMs from long-term retention. Zerto makes [replication] so simple and easy for virtual machines and it opened my eyes to a different way of doing business for disaster recovery.
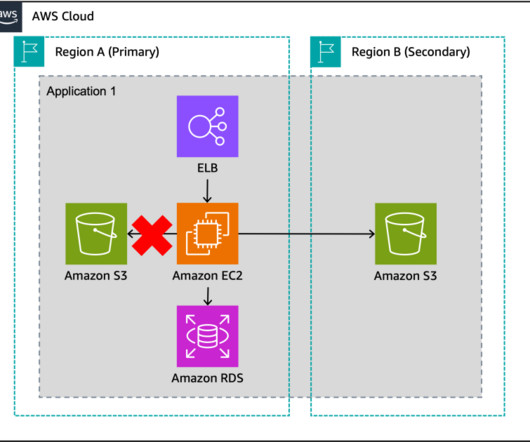
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1 ElastiCache.
In this final post, we will guide you through the essential factors to consider when choosing a DR solution, helping you make an informed choice that aligns with your organization’s goals and ensures robust protection against any potential disaster.
The threat of ransomware was definitely on the mind of one Zerto user who explained, “ We use Zerto to protect our staff information against ransomware , and [it] is outlined in our disaster recovery plan.” It also allowed us to preconfigure the boot sequence for a failover test or actual recovery.” For Amit B.,
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. However, they will run the same version of your application for consistency and availability in event of a failure. Amazon RDS database.
We’ll look at the top alternatives to VMware and outline their strengths and functionalities to help you make an informed decision depending on your specific requirements. Key features of Nutanix AHV: Storage: Nutanix has integrated storage that distributes data across multiple disks, making it better for failover and data integrity.
Information was gathered via online materials and reports, conversations with vendor representatives, and examinations of product demonstrations and free trials. Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy.
Information was gathered via online materials and reports, conversations with vendor representatives, and examinations of product demonstrations and free trials. Fusion also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy.
AWS makes it easy to configure the compute and storage resources needed to meet your application and performance demands. VMs in separate AZs can be configured as a Windows Failover Cluster Instance (FCI), and each node in the FCI connects to a single shared instance of an FSx file system.
A company that suffers an information technology (IT) disaster might never fully recover or may take months to recover. Kim Lagrue, Chief Information Officer, City of New Orleans . Life-supporting applications such as those used by the City of New Orleans’s IT department must always be on. Disaster Recovery Is a Non-negotiable.
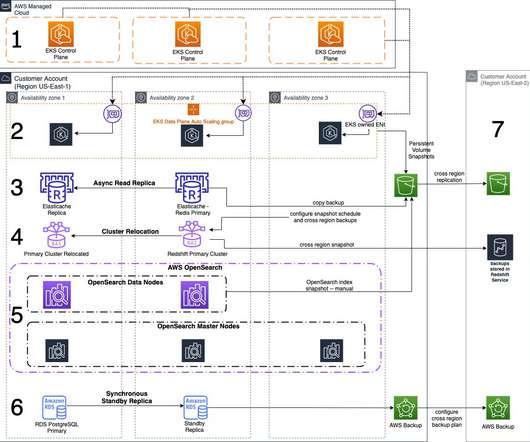
This strategy replicates workloads across multiple AZs and continuously backs up your data to another Region with point-in-time recovery, so your application is safe even if all AZs within your source Region fail. This example architecture refers to an application that processes payment transactions that has been modernized with AMS.
Step 1: Prepare before Planning – Gather information about key personnel, customers, facilities, operating procedures, etc. You can recover from a failure by using clustering software to failoverapplication operation from a primary server node to a secondary server node over a LAN. 3) DR Options.
Here, we delve into HA and DR, the dynamic duo of application resilience. High Availability is the ability of an application to continue to serve clients who are requesting access to its services. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
Arcserve Continuous Availability ensures business continuity with asynchronous, real-time replication and automatic failover to prevent downtime and data loss. Axcient enables users to mirror their entire business in the cloud, thereby simplifying data access and restoration, failovers, and virtualization.
For software replication with Always On availability groups across regions in Microsoft SQL Server 2022, the following benefits can be realized: Volume snapshots and asynchronous replication can be used to ensure that, after failover, disaster recovery posture can be regained rapidly. Seeding and reseeding times can be drastically minimized.
In this article, we’ll delve into two primary high-availability configurations—active-active and active-passive—offering insights into their mechanics, benefits, and ideal applications. Cloud-based applications: Cloud service providers use active-active configurations to deliver services like databases, storage, and applications.
For this year’s datacenter failover exercise, 57 Tier 1 and 2 service applications where declared to be “impacted”. While the previous year’s test was more extensive, this year’s was limited to failover response testing and recovery of underlying information technology infrastructure only.
First, there’s the pre-op work, such as assessing the risks and checking on the health of the arrays, switches, hosts, and applications. The database and application teams needed to fail over their delicate applications to secondary instances. Figure 8: User account information. Many specialist teams had to get involved.
The Australian Signals Directorate (ASD) has developed a set of prioritized mitigation strategies known as the Essential Eight to safeguard internet-connected information technology networks. Easily spin up your environment or applications to create self-serve, high-fidelity clones that can be used for testing.
An “input” is any information sent into a computing system via an external device, such as a keyboard or a mouse. Throughput is a measure of the number of units of information a system can process in a given amount of time. For active applications, SSDs are commonly used since they offer faster IOPS.
Information was gathered via online materials and reports, conversations with vendor representatives, and examinations of product demonstrations and free trials. It’s enabled through a simple consumer-grade interface that is SLA-driven and application-centric in applying data protection.
With regard to data management, the two sections of that technology crucial to data protection software are data lifecycle management and information lifecycle management. It also allows for the automated disaster recovery testing of business-critical systems, applications, and data, without business downtime or impact on production systems.
At a high level, some of the key elements of a BCP are: Information about and/or references to BC governance, policies and standards. References to Runbooks detailing all applicable procedures step-by-step, with checklists and flow diagrams. contact information and responsibilities of individual DR team members.
These conditions make it far too easy to misconfigure a network and can result in devices becoming incompatible with mission-critical applications if the network cannot be accessed. When using an off-site secondary server, your RTO will be restricted to the amount of time it takes to failover from one server to the other.
Commvault provides data protection and information management software to help organizations protect, access, and use all of their data economically. Datto is offered for data on- prem in a physical or virtual server or in the cloud via SaaS applications. Recently, Cohesity raised $250 million in Series E funding. Infrascale.
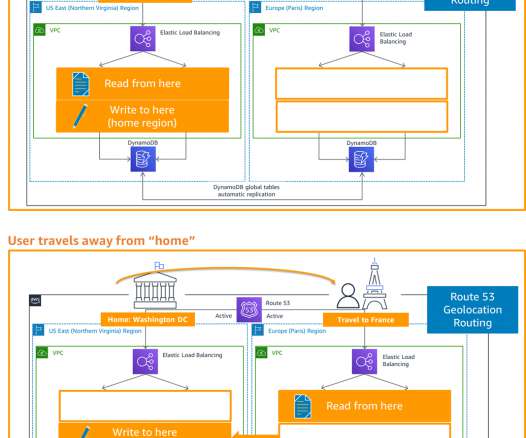
Your data governance strategy helps inform which routing policy to use. If your application cannot handle this and you require strong consistency, use another write pattern to avoid write contention. Alternatively, you can use AWS Global Accelerator for routing and failover. Related information. It does not rely on DNS.
As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. It is a monolithic application (application server and web server) that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance. The monolith application is tightly coupled with the database.
The cloud providers have no knowledge of your applications or their KPIs. Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Keep this information handy and make sure it is up to date as part of your incident preparedness.
As generative AI applications like chatbots become more pervasive, companies will train them on their troves of internal data, unlocking even more value from previously untapped information. The result is that large sections of corporate datasets are now created by SaaS applications.
Synchronous replication is mainly used for high-end transactional applications that require instant failover if the primary node fails. It also introduces latency that slows down the primary application and only works for distances of up to 300 km. Asynchronous replication, on the other hand, is mainly used for data backups. .
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. Guided remediation capabilities , like Incident Roles and Tasks, eliminate guesswork from the response process, so teams can coordinate and act faster.
These media serve as secure repositories for backed-up information. Backup software Backup software are applications or tools used to manage and automate the backup and recovery process. These backups are larger than incremental backups but smaller than full backups.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content