This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
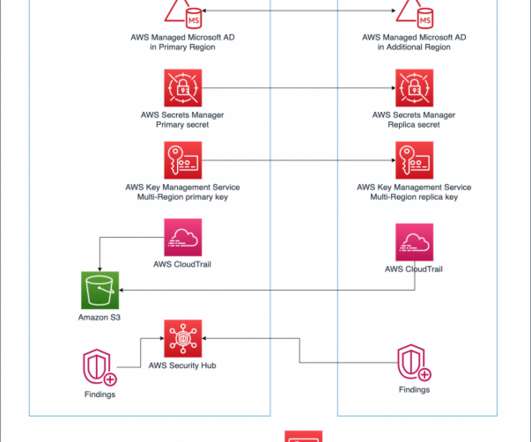
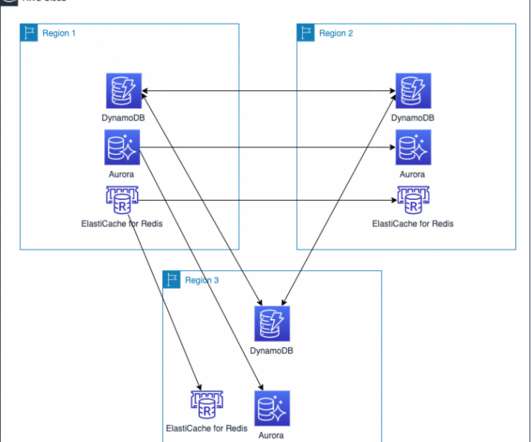
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy.
Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability. Identify key systems: Prioritize the most critical data and applications for replication. Businesses can scale protection based on their evolving needs, keeping costs manageable.
GenAI #7 Creating an organizational multi-Region failover strategy Preparedness is another common theme in this years favorites. When the application experiences an impairment using S3 resources in the primary Region, it fails over to use an S3 bucket in the secondary Region. #6 What a winning combo!
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. Redundancy ensures resilience by maintaining connectivity during outages.
Whether you’re new to AWS, running a hybrid environment, or managing cloud-native applications, Zerto provides seamless protection across your AWS landscape with features like orchestration, automation, and rapid recovery. Why Zerto for AWS through AWS Marketplace? Ready to try it out for yourself?
Building a multi-Region application requires lots of preparation and work. In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. Finally, in Part 3, we’ll look at the application and management layers. In Part 2, we’ll add in data and replication strategies.
Seamless failover : Zerto’s powerful orchestration and automation engine ensures that your applications are back online quickly, minimizing disruption and downtime. Wrapping It Up Building a robust and effective disaster recovery strategy requires meticulous planning, especially when it comes to compute solutions.
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Data is at the center of many applications. For this reason, data consistency must be considered when building a multi-Region application.
The growing need for applications to always be available eventually created a demand for recovery faster than traditional backups could provide. Despite these improvements, backup solutions couldn’t keep up with the RPOs and RTOs being set for business-critical applications and data.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Growing in both volume and severity, malicious actors are finding increasingly sophisticated methods of targeting the vulnerability of applications. Victims are either forced to pay the ransom or face total loss of business-critical applications. by protecting any application using continuous data protection (CDP).
Database contents change depending on the applications they serve, and they need to be protected alongside other application components. Application consistent replicas of MS SQL instances are achieved using the Microsoft VSS SQL Writer service. Read more about Protecting Microsoft SQL Server with Zerto Best Practices.
Recovering the virtual instances that make up your applications from the cloud is an essential part of modern business continuity strategies. Using cloud disaster recovery services, organizations can quickly restore critical workloads, applications, and databases to resume operations. Ensuring frequent backups with low RPOs.
In this feature, SIOS Technology ‘s Todd Doane offers five strategies for achieving application high availability. Business-critical applications, such as SAP, S/4 HANA, SQL Server, and MaxDB, serve as the backbone of many organizations. The company relied on securities trading applications based on Oracle Database.
Customers only pay for resources when needed, such as during a failover or DR testing. Automation and orchestration: Many cloud-based DR solutions offer automated failover and failback, reducing downtime and simplifying disaster recovery processes. Replication log latency is important for application performance. Azure or AWS).
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. Consolidated VPG State View— in addition to creating VPGs and performing failover operations, you can now view a simplified VPG state directly from the cloud console.
While all the native tools are there for anyone to take advantage of, what makes this solution unique is that Zerto takes the guesswork out of having to manage those snapshot chains, replication, instance configurations, networking, and identifying what instances make up which applications. Failover Live Workflow.
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. To identify potential business impact, ask yourself questions like: Which applications are most important? What virtualized infrastructure makes up those applications?
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. When critical systems go down, you need more than just a chat tool.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community.
It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. . First, it can synchronously replicate at the memory layer, so, in the event of a failover, there’s no waiting for memory loads to happen before the system can be considered up.
Michelle’s recently unveiled her latest version of her homegrown BIA tool, which is powered by Microsoft’s Power Apps - an off-the-shelf tool many companies use to create homegrown applications for their teams. We get to understand her development process and see if this is something others may wish to explore further for their own programs.
In this post, we start by discussing the threats against applications running as Kubernetes clusters. We’ll cover the threats against applications running as Kubernetes clusters and how Zerto for Kubernetes and its one-to-many replication functionality protects against them. They’re managed by the Kubernetes control plane.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
When you deploy mission-critical applications, you must ensure that your applications and data are resilient to single points of failure. Organizations are increasingly adopting a multicloud strategy—placing applications and data in two or more clouds in addition to an on-premises environment.
We get reminded repeatedly with each cloud outage that there is no such thing as a bullet-proof platform, and no matter where your applications and data reside, you still need a disaster recovery plan. Outages are only one of many threats facing your data and applications.
This fine tunes secondary storage based on the importance of the applications or data needing protection. And it allows you to test failover without disrupting applications or workloads, increasing your confidence in new protection mechanisms that have no effect on your existing, continual replication.
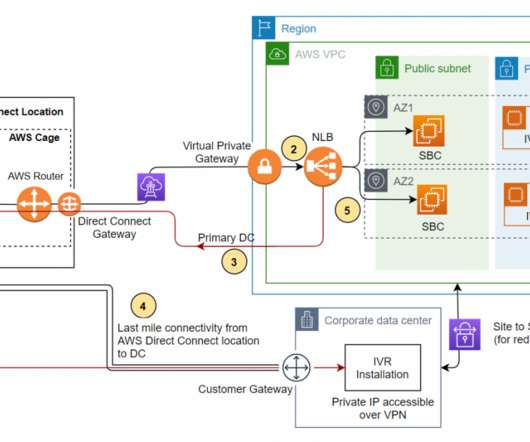
In other cases, the customer may want to use their home developed or third-party contact center application. Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. This is where the IVR application will be installed.
HPE and AWS will ensure that you are no longer bogged down with managing complex infrastructure, planning capacity changes, or worrying about varying application requirements. Adopting hybrid cloud does not need to be complex—and, if leveraged correctly, it can catapult your business forward.
Zerto, a Hewlett Packard Enterprise company, empowers customers to run an always-on business by simplifying the protection, recovery, and mobility of on-premises and cloud applications. You can try and buy Zerto with the same confidence and ease that comes with your other Azure-native applications. Why Go through the Azure Marketplace?
Consider factors such as the types of applications and data you need to protect, your recovery time objectives (RTOs) and recovery point objectives (RPOs) , compliance requirements, and budget or resources constraints. Zerto runs failover, dev , and other QA tests at any time without production impact, ensuring aggressive SLAs are met.
Now they need to access data using an internal business application. application username and password) to authenticate into the software and access data. Applications also validate their authorization. VPN is great for simple access to an application or server. ZTNA requires additional account verification (e.g.,
Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. SSDs aren’t typically used for long-term backups, so they’re built for both but are typically used in speed-driven applications. Applications that require fast data transfers take advantage of SSDs the most.
Zerto empowers you to: Recover entire sites and applications with confidence, at scale, in minutes. In just a few clicks, recover entire sites or multi-VM applications. Easily perform failover and backup testing quickly, without disruption. It’s that easy. Lower risk with instant, non-disruptive testing.
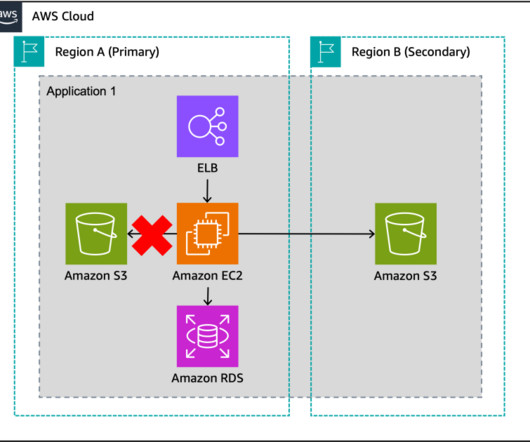
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment.
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. Enter your knight in shining armor—snapshot consolidation via fan-in replication.
Pure Storage has been hard at work innovating and developing new paths for VMware customers to take advantage of their storage platform to drive their applications forward. Leverage instant data copy management to accelerate application workflows by unlocking yourself from rigid traditional datastore types. Let’s discuss!
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1
The lab exercises allowed them to install Zerto, pair production and recovery sites, restore files and folders, perform test and live failovers, and restore VMs from long-term retention. Zerto makes [replication] so simple and easy for virtual machines and it opened my eyes to a different way of doing business for disaster recovery.
IT resilience refers to the ability to continuously keep essential IT systems and applications up and running despite disasters and disruptions. This can be achieved via periodic backups of data and applications to offsite storage to allow for fast recovery. What Is IT Resilience?
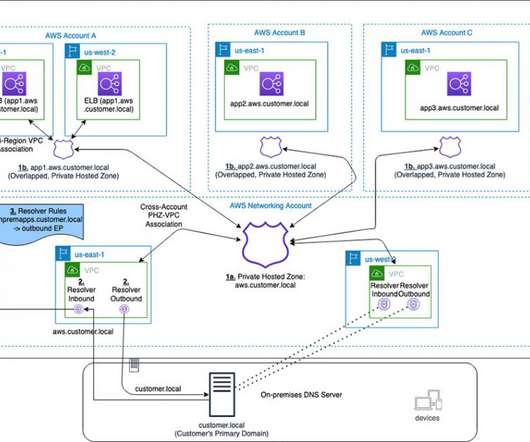
Many AWS customers have internal business applications spread over multiple AWS accounts and on-premises to support different business units. Your business units can use flexibility and autonomy to manage the hosted zones for their applications and support multi-region application environments for disaster recovery (DR) purposes.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content