This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Event-driven automation is a powerful approach to managing enterprise IT environments, allowing systems to automatically react to enterprise events (Observability / Monitoring / Security / Social / Machine) and reducing or removing the need for manual intervention. Guard rails can be easily added to prevent accidental overscaling.
This cloud-based solution ensures data security, minimizes downtime, and enables rapid recovery, keeping your operations resilient against hurricanes, wildfires, and other unexpected events. In the event of a disaster, businesses can switch to their cloud-based VMs within minutes.
How to Set Up a Secure Isolated Recovery Environment (SIRE) by Pure Storage Blog If youve suffered a breach, outage, or attack, theres one thing you should have completed and ready to go: a secure isolated recovery environment (SIRE). Heres why you need a secure isolated recovery environment and how to set one up. Why Do You Need a SIRE?
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
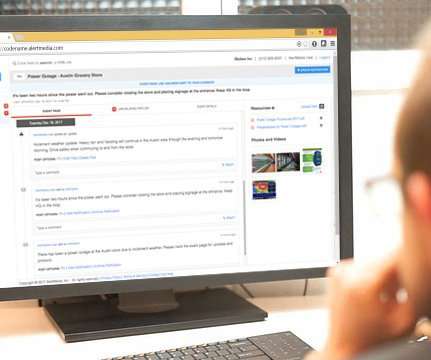
With the launch of Event Pages, organizations can instantly link their employees to critical information via a dedicated web page specific to an event. Individuals affected by the event can check the page as little or often as they feel necessary.
With the launch of Event Pages,  organizations can instantly link their employees to critical information via a dedicated web page specific to an event. Instead of sending individual status updates to every affected employee, the company now manages one Event Page in our mobile or web application â?? AlertMediaâ??s
Use tools like SIEM (security information and event management) and SOAR (security orchestration, automation, and response) platforms. Work with legal counsel to create an incident response plan that aligns with applicable laws. Access to data: Youre swimming in data from countless sources.
For my current client, I first considered this system’s potential after a hypothetical hurricane or extreme weather event. While Aruba has not faced a severe hurricane in living memory, such a system could still be valuable after an event causing widespread damage.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. We often hear people say, “We’re in the cloud, so we don’t have to an IT/DR plan.
Recovering the virtual instances that make up your applications from the cloud is an essential part of modern business continuity strategies. Using cloud disaster recovery services, organizations can quickly restore critical workloads, applications, and databases to resume operations. What is a cloud recovery site?
An IT disaster that leaves an organization without its data and applications can be crippling, if not fatal. The world has become increasingly reliant on access to data and digital services, and prolonged outages may cost your organization lost business, impaired productivity and irreparable reputation damage.
IT resilience refers to the ability to continuously keep essential IT systems and applications up and running despite disasters and disruptions. Without IT resilience, most businesses will be unable to maintain critical business functions when faced with disruptive events like cyberattacks, fires, natural disasters, etc.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1
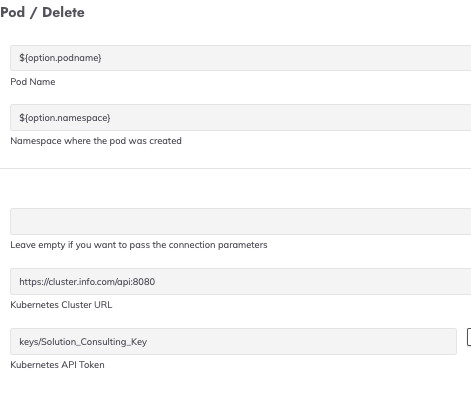
In this post, we start by discussing the threats against applications running as Kubernetes clusters. We’ll cover the threats against applications running as Kubernetes clusters and how Zerto for Kubernetes and its one-to-many replication functionality protects against them. They’re managed by the Kubernetes control plane.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Alternatively, shut down application servers and stop remote database access. . Re-enable full access to the database and application.
IT pros and organizations are starting to realize the importance of protecting their Kubernetes applications. Containers and cloud-native workloads are not immune from disruptive events and data loss. This includes human errors, outages, but most importantly: ransomware. . New capabilities include: . and Rook Ceph .
Follow these seven steps to implement a BC strategy that can help you swiftly recover your business processes in the event of an outage. A good BC strategy can help you swiftly recover your critical business processes in the event of a disruption, identify gaps that need to be remediated, and determine what training is necessary.
Cyber resilience refers to an organization’s capacity to sustain operations and continue delivering to customers during a critical cyber event, whether it’s an internal disruption or an external threat. Adaptability and agility are key components of cyber resilience, allowing businesses to respond effectively to such events.
If you’ve suffered a breach, outage, or attack, there’s one thing you should have completed and ready to go: a staged recovery environment (SRE). This should be set up in advance, tested, and in a ready state to be transitioned into quickly after an event. To stage and orchestrate the reintroduction of critical applications.
Cloud hosting means placing compute resourcessuch as storage, applications, processing, and virtualizationin multi-tenancy third-party data centers that are accessed through the public internet. Service providers offer resources such as applications, compute, and storage through free or pay-per-usage models. What Is Cloud Storage?
What really happens when the cloud goes down and how do you protect your critical business applications in such an event? Learn about the anatomy of a cloud outage and best practices to help your business ensure maximum uptime against all odds.
Educators need their applications available to reliably teach to our children, while constituents need access to emergency, financial and social services in their most critical time of need. An IT outage of any sort can adversely impact people’s lives.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
In an age when ransomware attacks are common occurrences, simply having your systems, applications, and data backed up is not enough to ensure your organization is able to recover from a disaster. Remember, after an outage, every minute counts…. As a result, they aren’t able to recover as fast as needed.
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
What if the very tools that we rely on for failover are themselves impacted by a DR event? As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. Simple Regional failover scenario using Route 53 Application Recovery Controller.
Using an automation orchestration tool to enable event-driven automation, organisations can empower on-call responders with immediate access to automated runbooks, personally crafted by subject matter experts. They can do this by having automation orchestration capability that is event-driven, where the event in question is the incident.
Data backup is the process after a data loss event of duplicating data to facilitate retrieval of the duplicate set Duplicating data in order to recover the duplicate set following a data loss incident. They guarantee that data is secure and that essential information is safe in the event of a natural disaster, theft, or other emergency.
Indeed, besides any business’ need to be able to cope with natural disasters or planned outages (maintenance, etc.), As such, you need a data protection management and recovery solution that seamlessly protects your data and workloads across multiple solutions, applications, and environments. What Is Cyber Resilience?
As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. It is a monolithic application (application server and web server) that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance. The monolith application is tightly coupled with the database.
Their process for developing and updating their BCP initially involved holding in-person interviews with department heads to gather information about various impacts to their core processes in case of an outage: Who are their key team members? What vendors or applications do they rely on? What are their workaround processes?
We’ll also share some ideas on how you can ensure that your documentation is not simply window dressing but is a real aid that can improve your company’s ability to recover in the event of a disruption. These may be different than the workarounds used in a non-cyber applicationoutage. Common Mistake No.
Surging ransomware threats elevate the importance of data privacy and protection through capabilities such as encryption and data immutability in object storage – capabilities that protect sensitive data and enable teams to get back to business fast in the event of such an attack.
Today’s organizations are using and creating more data from applications, databases, sensors, as well as other sources. Not all data is equal: When a disaster strikes, there are certain sets of data and applications the business needs to get back up and running. We are data dependent: The business environment has become data-centric.
This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. This allows customers to seamlessly move applications and data across hybrid environments without refactoring, enabling true hybrid cloud deployment. Azure or AWS).
These events could be man-made (industrial sabotage, cyber-attacks, workplace violence) or natural disasters (pandemics, hurricanes, floods), etc. It is a strategy designed to help businesses continue operating with minimal disruption during a disruptive event. Business Continuity Plan vs. Disaster Recovery Plan.
Approaching maintenance in this way allows your organization to be prepared for planned outages within your infrastructure, including patch installation, security updates, and service packs. RPOs establish how much data an organization can stand to lose in the event of a disaster. Incompatible Infrastructure.
Application restoration priorities or tiers should be well-defined so that business units know the timeline for restoring applications and there are no surprises. Without these services, other business applications can’t come back online or function correctly. Or 10 hours?” If we are under attack, how will we communicate?
Many IT teams and companies think they’re successfully backing up their data and applications, only to have unpleasant surprises in the case of a malware attack, outage or other event. To overcome these challenges, you need to make sure you’re verifying that your backups are working exactly how you think they should.
Whether it’s supplier challenges, extreme weather, an unplanned outage, or an increased threat of cyberattacks, it seems the next disruption is just around the corner. What happens when a hurricane causes damage to an entire region, causing several sites to go down along with unplanned network outages? Generate Response.
In the realm of uncertainty around cyber threats and other unplanned outages, disaster recovery (DR) testing stands as a crucial pillar. DR testing additionally ensures organizations are as prepared as they can be to enable the swift restoration and safety of data and applications in the face of unforeseen events.
Regardless of the actual figure, time really is money, so organizations must be proactive in setting themselves up for successful recovery in the event of a disaster. A BC program encompasses multiple plans to maintain business operations before, during, and after an event. CASE STUDY: IMPROVING DISASTER RECOVERY.
Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. FlashArray ActiveWorkload Launched— ActiveWorkload brings non-disruptive workload migrations to FlashArray.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content