This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How to Set Up a Secure Isolated Recovery Environment (SIRE) by Pure Storage Blog If youve suffered a breach, outage, or attack, theres one thing you should have completed and ready to go: a secure isolated recovery environment (SIRE). Its all about speed. Their focus is speed: Is the business back up and running yet?
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. Redundancy ensures resilience by maintaining connectivity during outages. Bandwidth Optimization and Capacity Planning Why It Matters: Recovery operations generate significant network traffic.
This system would also assist in less obvious impacts, such as a computer outage affecting specific applications. Although traffic lights are a blunt instrument, with ‘amber’ potentially indicating anywhere from 30% to 60% operational capacity, they provide an easily understandable status.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or applicationoutages.
A recent Gartner reports reveals that by 2025, more than 70% of corporate, enterprise-grade storage capacity will be deployed as consumption-based offerings—up from less than 40% in 2021. . Consumed capacity. SLAs are the legal agreements we make with our customers on measurable metrics like uptime, capacity, and performance.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. .
IT resilience refers to the ability to continuously keep essential IT systems and applications up and running despite disasters and disruptions. An effective IT resilience strategy focuses on delivering an ‘always-on’ customer experience regardless of unplanned outages and changes to IT infrastructure. What Is IT Resilience?
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Alternatively, shut down application servers and stop remote database access. . Re-enable full access to the database and application.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1 Figure 2.2.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. Mega arrays were able to shrink from 77 rack units to 12 with the introduction of FlashArray.
Cloud hosting means placing compute resourcessuch as storage, applications, processing, and virtualizationin multi-tenancy third-party data centers that are accessed through the public internet. Service providers offer resources such as applications, compute, and storage through free or pay-per-usage models. What Is Cloud Storage?
In an age when ransomware attacks are common occurrences, simply having your systems, applications, and data backed up is not enough to ensure your organization is able to recover from a disaster. Remember, after an outage, every minute counts…. As a result, they aren’t able to recover as fast as needed.
Capacity limitations. We often see that efforts to recover critical apps are derailed by limitations in computing or storage capacity. In today’s environment, you cannot just go out and buy capacity. Sorting out such problems can take hours if not days, an expensive proposition if the issue is prolonging an outage.
Cyber resilience refers to an organization’s capacity to sustain operations and continue delivering to customers during a critical cyber event, whether it’s an internal disruption or an external threat. Digital transformation enhances an organization’s ability to manage cyber threats while optimizing business operations.
If you’ve suffered a breach, outage, or attack, there’s one thing you should have completed and ready to go: a staged recovery environment (SRE). To stage and orchestrate the reintroduction of critical applications. Work with business stakeholders to prioritize application recovery needs to appropriately size the environment.
Today’s organizations are using and creating more data from applications, databases, sensors, as well as other sources. Not all data is equal: When a disaster strikes, there are certain sets of data and applications the business needs to get back up and running. We are data dependent: The business environment has become data-centric.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. Mega arrays were able to shrink from 77 rack units to 12 with the introduction of FlashArray.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . The problem is that most businesses don’t know how to protect their containerized applications. According to Cybersecurity Insiders’ 2022 Cloud Security Report : .
BMC Helix ServiceOps brings service and operations management together with differentiated capabilities that provide a deep level of context and insight by: Protecting the business from the risk of outages and slow performance. Scaling capacity with artificial intelligence. Personalizing employee and customer experience.
As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. It is a monolithic application (application server and web server) that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance. The monolith application is tightly coupled with the database.
System Monitoring and Alerting Monitoring and alerting allows IT teams to detect and respond to critical issues in real time, helping to prevent costly failures or outages.
Service outages ultimately frustrate customers, leading to churn and loss of trust. These are the most common weak points cyber extortionists use: Outdated software and systems: Unpatched operating systems, applications, or hardware often have known vulnerabilities that attackers exploit.
CIOs can use the capacity required immediately via OPEX, manage costs over time based upon discounting, and have the ability to burst into the type of high IO (a.k.a. While an IT professional’s primary job is to ensure user access to data and applications, security should be a high priority for everyone, regardless of their role.
This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. This allows customers to seamlessly move applications and data across hybrid environments without refactoring, enabling true hybrid cloud deployment. Azure or AWS).
With business growth and changes in compute infrastructures, power equipment and capacities can become out of alignment, exposing your business to huge risk. Cloud-based data protection and recovery allows organizations to back up and store critical data and applications off-site, so they are protected from local disruptions.
When it comes to SaaS applications running in the cloud, there are a number of unique considerations. This means that they are responsible for providing always-available application services that are hosted on resilient infrastructure and maintaining data copies to withstand infrastructure failures or site-wide outages.
References to Runbooks detailing all applicable procedures step-by-step, with checklists and flow diagrams. Over time, these plans can be expanded as resources, capacity, and business functionality increase. Instructions about how to use the plan end-to-end, from activation to de-activation phases. What Is A Disaster Recovery Plan?
Integrating Pure Storage all-flash storage technology with Equinix Metal bare metal infrastructure helps businesses achieve high performance, low latency, and rapid data access when using their data-intensive applications to run large databases, AI workloads, or high-velocity analytics. Simplicity. High-performance computing.
Most business-critical applications run on high-performance all-flash storage arrays. The same forces that drive businesses to demand high performance from their applications apply to data protection operations. IT professionals need fast data protection before challenges to application availability appear. . Faster Is Better.
In today’s post we’ll look at why organizations still need to be adept at IT disaster recovery (IT/DR) and describe the four phases of restoring IT services after an outage. Phase 1: Preparation Technically, preparation is not a phase of disaster recovery since it happens before the outage. Estimate how long the outage will last.
RAM by Pure Storage Blog Flash memory is a high-performance solution to traditional hard drives making data storage and retrieval faster for applications and users. Every computer needs a form of RAM to store input from applications and send data to the central processing unit (CPU) for calculations. What Is Computer or System Memory?
Platform software upgrades can get very complicated very fast and come with unexpected outages and downtime. And when your data and applications are offline, your organization faces losses—in time, money, and even reputation. That’s where truly non-disruptive, agile data storage comes into play.
Virtual Volumes (vVols) and stretched clusters offer the ability to balance VMs application workloads between two geographically separated data centers. They also offer non-disruptive workload mobility enabling migration of services between geographically close sites without the need for sustaining an outage.
In the context of computing, container orchestration specifically refers to the management of containerized applications, where containers encapsulate an application and its dependencies, making it portable and scalable across different computing environments.
You invest in larger storage tanks and develop a way to reuse greywater for non-potable applications like gardening. So much so that you’re able to optimize performance, reduce costs, increase capacity, and prevent outages by quickly moving or spreading workloads to various execution venues.
What is a generator and how do we inspect it on a residential application? Once that information was gathered, I would verify that the switch had a “suitable for use as service equipment” (SUSE) label, and that it had proper capacity, ratings, listing, and labeling.
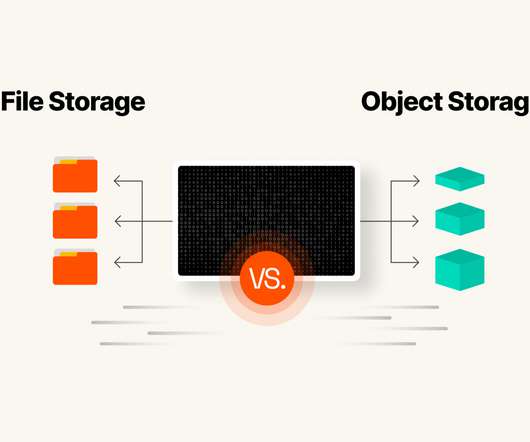
Because of the differences in structure, file storage and object storage have significantly different capacity to scale. While file storage isn’t considered extremely expensive, it can result in higher costs as you add capacity. This makes it simple to retrieve data via many different applications and even web browsers.
Today, that same FlashArray from 2014 has 10 times its original storage capacity in just three rack units. Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. Mega arrays were able to shrink from 77 rack units to 12 with the introduction of FlashArray.
This key design difference makes them well-suited to very different business functions, applications, and programs. Flash storage can offer an affordable and highly consistent storage solution for relational databases as they grow and support more cloud-based modern applications’ persistent storage needs. Efficiency. Consistency.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. This ensures that the control plane stays available via the AWS Singapore Region even if there is an outage in AWS Mumbai Region affecting control plane availability.
Maintaining performance through failure is Job 1: all-flash arrays are deployed in some of the most mission-critical workloads in the world, and taking a 12.5%, 25%, or 50% performance hit during failures is simply not an option – it can result in significant application response issues or downtime. never having to ask for an outage window).
And many have chosen MySQL for their production environments for a variety of use cases, including as a relational database or as a component of the LAMP web application stack. But, because database applications like MySQL can be particularly demanding, it’s important to ensure the right resources are allocated to each virtual machine.
The fire and impact: The fire OVHcloud had in their data centre campus in Strasburg, reminds us, that just because we have put our applications in place or have bought software that is hosted in the cloud, we are still vulnerable to IT outages. What are the lessons I identified from the OVHcloud fire?
The fire and impact: The fire OVHcloud had in their data centre campus in Strasburg, reminds us, that just because we have put our applications in place or have bought software that is hosted in the cloud, we are still vulnerable to IT outages. What are the lessons I identified from the OVHcloud fire?
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content