This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channels original scope, and your readership this last year has proven that decision was the right one. Well, its been another historic year!
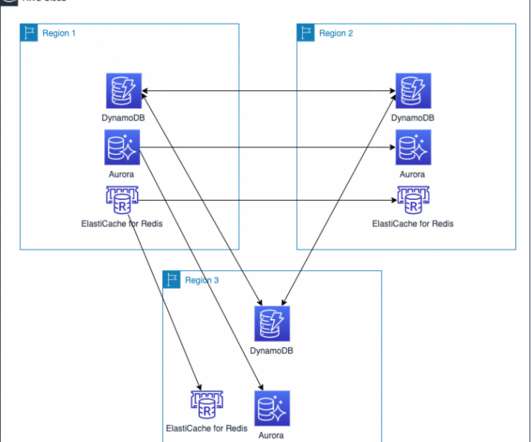
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy.
How Pure Protect //DRaaS Shields Your Business from Natural Disasters by Pure Storage Blog Summary Pure Protect //DRaaS shields your business from the rising threat of natural disasters. Fast failover and minimal downtime: One of the key benefits of Pure Protect //DRaaS is its rapid failover capability.
Building a multi-Region application requires lots of preparation and work. In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. Finally, in Part 3, we’ll look at the application and management layers. Considerations before getting started.
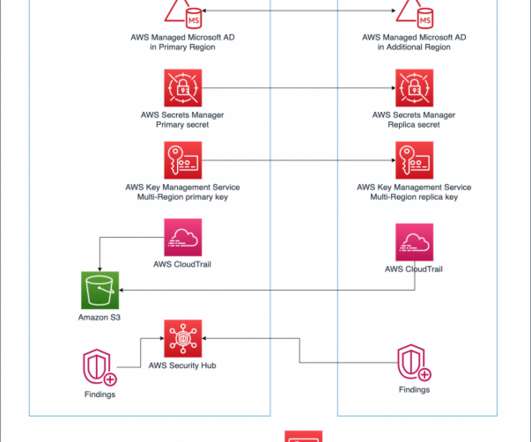
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Data is at the center of many applications. For this reason, data consistency must be considered when building a multi-Region application.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? What Is Failback?
Automating Disaster Recovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disaster recovery can offer many advantages for organizations. Customers only pay for resources when needed, such as during a failover or DR testing. Azure or AWS).
A DR runbook is a collection of recovery processes and documentation that simplifies managing a DR environment when testing or performing live failovers. To identify potential business impact, ask yourself questions like: Which applications are most important? What virtualized infrastructure makes up those applications?
It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. . First, it can synchronously replicate at the memory layer, so, in the event of a failover, there’s no waiting for memory loads to happen before the system can be considered up.
READ TIME: 4 MIN March 4, 2020 Coronavirus and the Need for a Remote Workforce Failover Plan For some businesses, the Coronavirus is requiring them to take a deep dive into remediation options if the pandemic was to effect their workforce or local community.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover.
When you deploy mission-critical applications, you must ensure that your applications and data are resilient to single points of failure. Organizations are increasingly adopting a multicloud strategy—placing applications and data in two or more clouds in addition to an on-premises environment.
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. Fan-in deduplicates data across source arrays before sending it to the target, maximizing your storage efficiency.
At the end of November, I blogged about the need for disaster recovery in the cloud and also attended AWS re:Invent in Las Vegas, Nevada. I covered this topic in more detail in my last blog post , but the highlights bear repeating in light of these recent outages. Outages are only one of many threats facing your data and applications.
This fine tunes secondary storage based on the importance of the applications or data needing protection. And it allows you to test failover without disrupting applications or workloads, increasing your confidence in new protection mechanisms that have no effect on your existing, continual replication.
ZTNA vs. VPN by Pure Storage Blog Summary As data breaches become more common, organizations need a better way to protect their data. Now they need to access data using an internal business application. application username and password) to authenticate into the software and access data.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
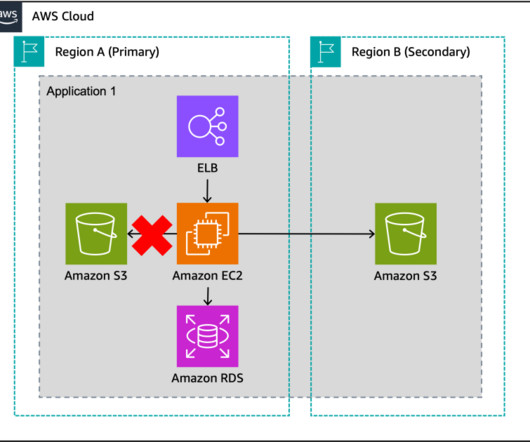
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment. or OpenSearch 1.1,
Move to Pure: The Last Storage vMotion You’ll Ever Need to Do by Pure Storage Blog Back to Las Vegas! Pure Storage has been hard at work innovating and developing new paths for VMware customers to take advantage of their storage platform to drive their applications forward. Let’s discuss! vSphere Virtual Volumes Of course vVols!
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1
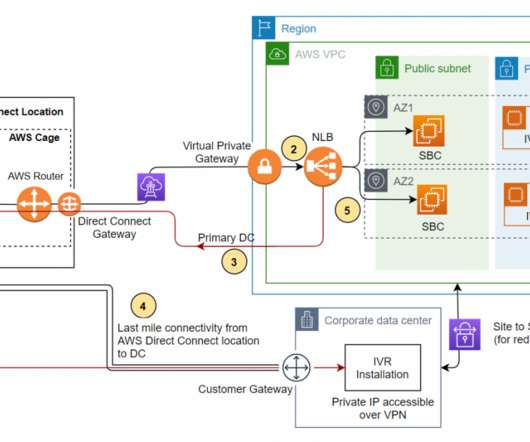
In other cases, the customer may want to use their home developed or third-party contact center application. Let’s see how the SIP trunk termination on the AWS network handles the failover scenario of a third-party IVR application installed on Amazon EC2 at the DR site. This is where the IVR application will be installed.
In this blog post, we’ll explore key considerations to help you make an informed decision when selecting a DRaaS provider. Because it replicates only the changed information (rather than the entire application), hypervisor-based replication doesn’t impact VM performance. This is true continuous data protection.
Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. SSDs aren’t typically used for long-term backups, so they’re built for both but are typically used in speed-driven applications. Applications that require fast data transfers take advantage of SSDs the most.
Top 8 VMware Alternatives by Blog Home Summary Virtualization software is a powerful tool that can help businesses increase efficiency, reduce costs, and improve resource utilization. OpenShift also works with containers , has built-in security, and has data storage failover across multiple disks.
Introducing Pure Protect //Disaster Recovery as a Service (DRaaS) by Pure Storage Blog In today’s unpredictable world, natural disasters are ramping up in both frequency and intensity. Combatting these various threats and disasters can lead to complex solutions and costly applications that only solve part of the problem. Register now.
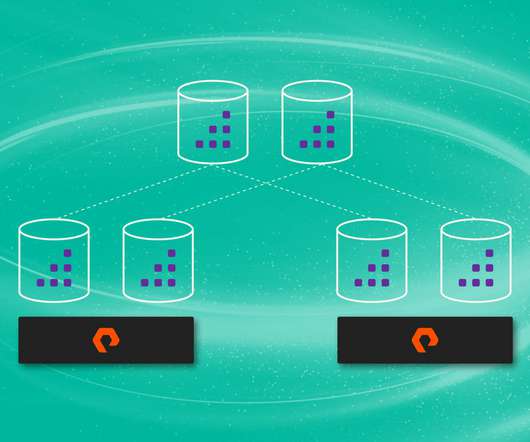
In the previous blog, “The Benefits of One-to-Many Replication,” we provided an overview of Zerto’s one-to-many replication feature. One-to-many replication allows you to replicate data from a single source to multiple (up to three) target environments, providing a flexible and efficient way to protect your data and applications.
Being able to migrate, manage, protect, and recover data and applications to and in the cloud using purpose-built cloud technologies is the key to successful cloud adoption and digital transformation. Zerto In-Cloud for AWS empowers users with the ability to logically select all EC2 instances that make up a particular application.
DXC Technology: Turning Ideas into Real Business Impact by Blog Home Summary When this leading technology services provider needed a robust disaster recovery (DR) solution for its Managed Container Services platform, DXC Technology chose Portworx by Pure Storage. CDP is widely used by DXC Technology’s government clients in Italy.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). However, they will run the same version of your application for consistency and availability in event of a failure. Fail over with event-driven serverless architecture.
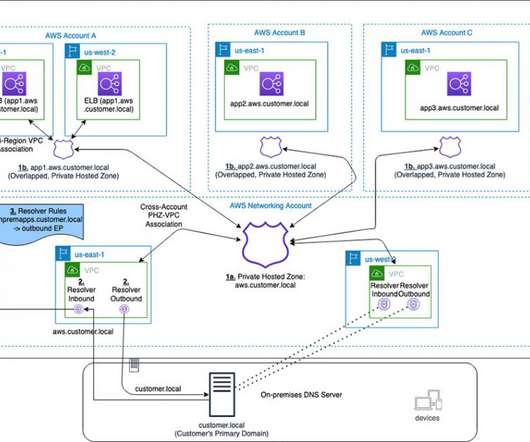
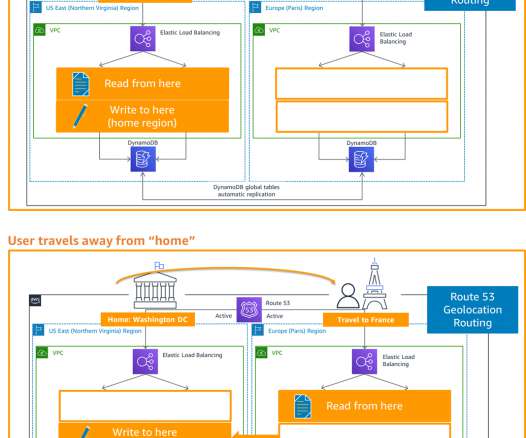
Many AWS customers have internal business applications spread over multiple AWS accounts and on-premises to support different business units. Your business units can use flexibility and autonomy to manage the hosted zones for their applications and support multi-region application environments for disaster recovery (DR) purposes.
In this blog post, we’ll explore how to effectively and efficiently migrate to the cloud using Zerto. Application migration: Migrate your applications and workloads to the cloud, ensuring compatibility and performance optimization. Following these steps helps ensure that your migration is successful. Still not convinced?
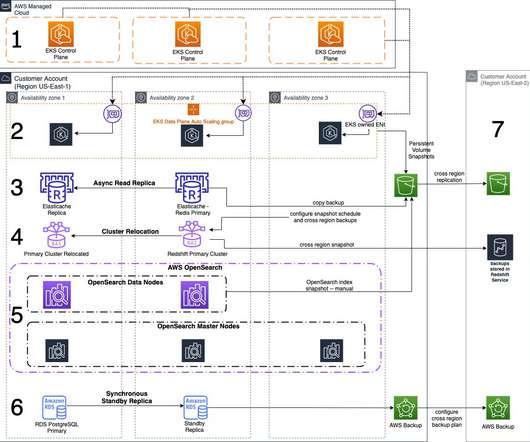
This 3-part blog series discusses disaster recovery (DR) strategies that you can implement to ensure your data is safe and that your workload stays available during a disaster. The strategy outlined in this blog post addresses how to integrate AWS managed services into a single-Region DR strategy. Amazon EKS control plane.
This blog post will focus on the use of two or more Pure Cloud Block Store instances in different Microsoft Azure availability zones or regions to achieve cost-effective disaster recovery for Microsoft SQL Server instances. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . In part 2 of our three-part cloud data security blog series, we discussed the issue of complexity. According to Cybersecurity Insiders’ 2022 Cloud Security Report : .
In the last blog, Maximizing System Throughput , we talked about design patterns you can adopt to address immediate scaling challenges to provide a better customer experience. In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution.
Equally important is to look at throughput (units of data per second)—how data is actually delivered to the arrays in support of real-world application performance. For active applications, SSDs are commonly used since they offer faster IOPS. However, looking at IOPS is only half the equation. So in short, you should use both.
Life-supporting applications such as those used by the City of New Orleans’s IT department must always be on. It maintains application performance with continuous replication and near-zero RPO/RTO. It’s eminently important for them to have a scenario where they can test failover actively without disrupting these services. .
For this year’s datacenter failover exercise, 57 Tier 1 and 2 service applications where declared to be “impacted”. While the previous year’s test was more extensive, this year’s was limited to failover response testing and recovery of underlying information technology infrastructure only.
Non-disruptive DR Drills for Oracle Databases Using Pure Storage ActiveDR — Part 3 of 4 by Pure Storage Blog In Part 3 of this four-part series, I’ll show some simple scripting to perform non-disruptive DR tests for Oracle databases using ActiveDR ™. We’ll explore this in the final blog post of this series —Part 4.
Active-active vs. Active-passive: Decoding High-availability Configurations for Massive Data Networks by Pure Storage Blog Configuring high availability on massive data networks demands precision and understanding. In emergency situations, healthcare providers need instant access to accurate information, making failover capabilities vital.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. In a DR scenario, recover data and deploy your application. Run scaled-down versions of applications in a second Region and scale up for a DR scenario. Data storage.
Synchronous replication is mainly used for high-end transactional applications that require instant failover if the primary node fails. It also introduces latency that slows down the primary application and only works for distances of up to 300 km. Asynchronous replication, on the other hand, is mainly used for data backups. .
In my first blog post of this series , I introduced you to four strategies for disaster recovery (DR). If your application cannot handle this and you require strong consistency, use another write pattern to avoid write contention. Alternatively, you can use AWS Global Accelerator for routing and failover.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content