This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. Redundancy ensures resilience by maintaining connectivity during outages. How to Achieve It: Implement multi-layered security with firewalls, intrusion prevention systems, zero trust architecture, and encryption.
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. The monolith application is tightly coupled with the database.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. Architecture overview. OpenSearch Service.
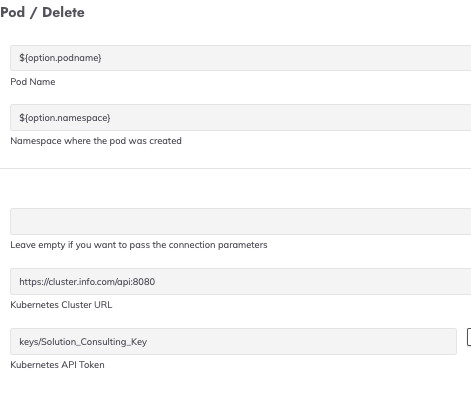
Kubernetes Pod Actions Description: Whilst in Kubernetes environments, a desired state is usually well maintained, occasionally restarting pods can be necessary to refresh the application state or apply new configurations. This automation task restarts pods to ensure they connect to the most updated environment. — 10.
With an ever-increasing dependency on data for all business functions and decision-making, the need for highly available application and database architectures has never been more critical. . Alternatively, shut down application servers and stop remote database access. . Re-enable full access to the database and application.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or applicationoutages.
Far from relieving organizations of the responsibility of recovering their IT systems, today’s cloud-based and hybrid environments make it more important than ever that companies know how to bring their systems back up in the event of an outage. Moreover, cloud-services providers are themselves susceptible to outages and failed recoveries.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Figure 3: High-level solution architecture for protecting Azure VMs across two regions. .
In an age when ransomware attacks are common occurrences, simply having your systems, applications, and data backed up is not enough to ensure your organization is able to recover from a disaster. Remember, after an outage, every minute counts…. As a result, they aren’t able to recover as fast as needed.
Effective failover methods must include independent, automated channels (online and offline) for both notifications and critical data access, and a distributed system architecture, integrated with backup systems and tools. PagerDutys 700+ integrations mean the incident management platform fits seamlessly into customers’ tech stacks.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. The Best Data Protection Software.
Educators need their applications available to reliably teach to our children, while constituents need access to emergency, financial and social services in their most critical time of need. An IT outage of any sort can adversely impact people’s lives.
As you review the key objectives and recommendations, ask yourself: Is my security architecture resilient? Those investments add up to one concept: a tiered resiliency architecture. A three-tiered resiliency architecture can protect your entire data estate, which I outlined how to do do this in this article.
When critical applications suffer performance degradation—or worse yet, a full outage—engineers rush to find the (apparent) cause of the incident, such that they can remediate the issue as fast as possible. Grab all the evidence: Capturing application state for post-incident forensics. Stay inquisitive, my fellow detectives.
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object. Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation.
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
Consider engaging in a discussion with the CISO about the benefits of tiered security architectures and “ data bunkers ,” which can help retain large amounts of data and make it available immediately. Without these services, other business applications can’t come back online or function correctly.
Will That Cause an Outage? A modern cloud-like storage service should never require “planned downtime” or require outage windows to perform routine software, hardware upgrades and maintenance. Our Evergreen architecture already eliminates the industry’s traditional method of upgrading storage by replacing and junking existing systems.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. Get started with Portworx—try it for free. .
As a bonus, you’ll see how to use service control policies (SCPs) to help simulate a Regional outage, so that you can test failover scenarios more realistically. In the simplest case, we’ve deployed an application in a primary Region and a backup Region. Simple Regional failover scenario using Route 53 Application Recovery Controller.
Here, we delve into HA and DR, the dynamic duo of application resilience. High Availability is the ability of an application to continue to serve clients who are requesting access to its services. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
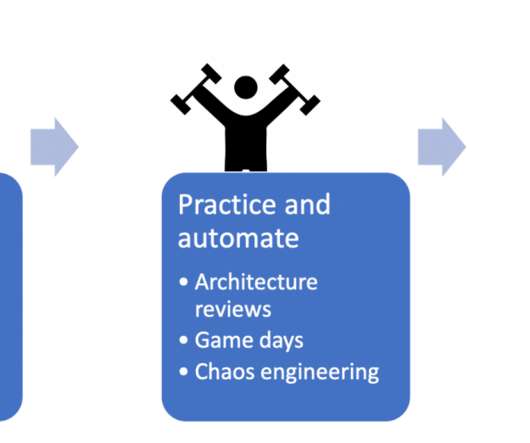
This affects the resilience of critical business applications and can stall cloud adoption. In Part II, we’ll explore the technical considerations related to architecture and patterns. It’s also sometimes mixed with concerns about highly publicized security or outage events. Architecture reviews. Customer challenges.
Zerto, a Hewlett Packard Enterprise company, empowers customers to run an always-on business by simplifying the protection, recovery, and mobility of on-premises and cloud applications. The new multi-VRA architecture scales out protection for VMs in Azure rather than using multiple ZCAs.
Service outages ultimately frustrate customers, leading to churn and loss of trust. These are the most common weak points cyber extortionists use: Outdated software and systems: Unpatched operating systems, applications, or hardware often have known vulnerabilities that attackers exploit.
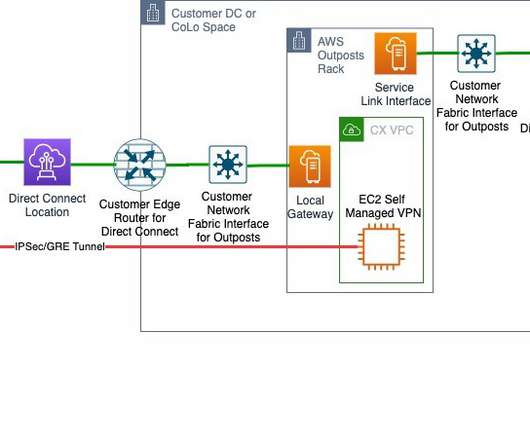
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. This architecture also helps customers to comply with various data sovereignty regulations in a given country. Architecture Overview. Amazon VPC. AWS Outposts.
Most business-critical applications run on high-performance all-flash storage arrays. The same forces that drive businesses to demand high performance from their applications apply to data protection operations. IT professionals need fast data protection before challenges to application availability appear. . Faster Is Better.
In the PagerDuty application, some of this work is done for you, via the Intelligent Alert Grouping (IAG) feature. When we build our monitors and corresponding alerts, we are usually doing so with the service in question in mind but we can’t always effectively map how dependencies will respond to each other’s latencies and outages.
Hyperscale cloud providers like Amazon, Google, and Microsoft—along with consumer computing companies like Apple—are heavily focused on building proprietary processor designs specific to their needs, while other manufacturers like Intel, AMD, and Qualcomm are all focusing on delivering sub-10 nm Application Specific Integrated Circuits (ASICs).
As generative AI applications like chatbots become more pervasive, companies will train them on their troves of internal data, unlocking even more value from previously untapped information. The result is that large sections of corporate datasets are now created by SaaS applications.
My experience with the transition from traditional applications to modern apps, microservices, containers, and Kubernetes illustrates many of the themes uncovered in our research. . I saw the difference between a traditional architecture and a microservices architecture. That is the power of modern applications.
FlashArray//E operates with the same unified block and file architecture as FlashArray to streamline management and operations and is also a perfect complement to our FlashBlade ® family providing unified file and object. Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation.
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment.
Without proper oversight, sanctioned and unsanctioned SaaS applications can leave sensitive business information exposed. When backups of sanctioned SaaS applications do exist, overlooked SaaS data often goes unprotected. Shadow IT and shadow AI remain a major source of headaches for IT teams. That starts with immutable storage.
But even internally, an outage can be disastrous. The city had to spend $10 million on recovery efforts, not including the $8M in lost revenue from a two-week outage of bill payment systems and real estate transactions. Application scanning and encryption key management. What Happens If You Do Pay the Ransom? Tabletop planning.
Platform software upgrades can get very complicated very fast and come with unexpected outages and downtime. And when your data and applications are offline, your organization faces losses—in time, money, and even reputation. That’s where truly non-disruptive, agile data storage comes into play.
Modern applications are powered by ephemeral compute, yet persistent data—vast data lakes and data warehouses. For example, many architectures on AWS, even those that split workloads into multiple availability zones, have one central data lake or bucket. The biggest myths in AWS architecture are often related to resilience.
The folks over at XtremIO have been busy this holiday season, penning a nearly 2,000-word blog to make the argument for their scale-out architecture vs. dual-controller architectures. never having to ask for an outage window). never having to ask for an outage window). We call this non-disruptive operations.
First, which is much more easily obtained, is to host some applications in one cloud platform and other applications in another cloud platform. While this does require tooling and support in both Cloud Operations and Cybersecurity, it provides resiliency protection against outages fully taking down entire operations.
A recent Pure Storage survey found that 69% of organizations consider recovering from a cyber event to be fundamentally different from recovering from a “traditional” outage or disaster. builds on the original framework, integrating lessons learned from years of real-world application and recent technological advancements.
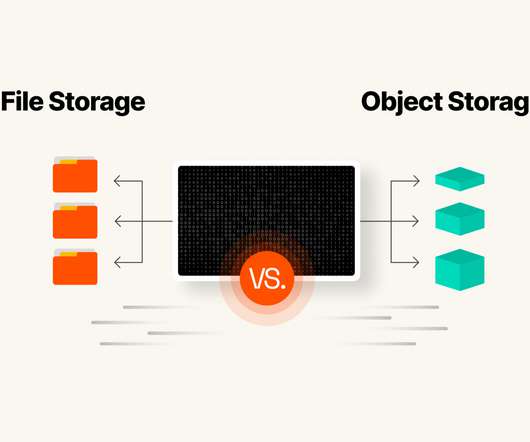
This makes it simple to retrieve data via many different applications and even web browsers. A retail store saves its server backup and recovery data in cloud-based object storage, so it’s still available in the event of a natural disaster or local outage. Traditional object storage uses HTTP to access data.
RTO is the service level defining how long a recovery may take before unacceptable levels of damage occur from an outage. Meanwhile, RPO is the service level defining the point in time when data loss resulting from an outage becomes unacceptable. Both represent critical points of failure. After that time, the business suffers.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content