This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channels original scope, and your readership this last year has proven that decision was the right one. Well, its been another historic year!
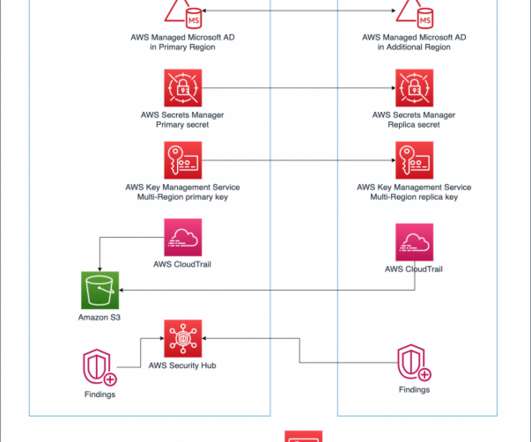
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy.
Recovery Time Objective (RTO): Measures the time it takes to restore applications, services, and systems after a disruption. BGP, OSPF), and automatic failover mechanisms to enable uninterrupted communication and data flow. Are advanced security measures like zero trust architecture in place? Do you conduct regular DR tests?
Being able to choose between different compute architectures, such as Intel and AMD, is essential for maintaining flexibility in your DR strategy. Zerto excels in this area by offering an agnostic approach to DR, ensuring flexibility and compatibility across various platforms, whether you are using Intel or AMD architectures.
Building a multi-Region application requires lots of preparation and work. Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming. Finally, in Part 3, we’ll look at the application and management layers.
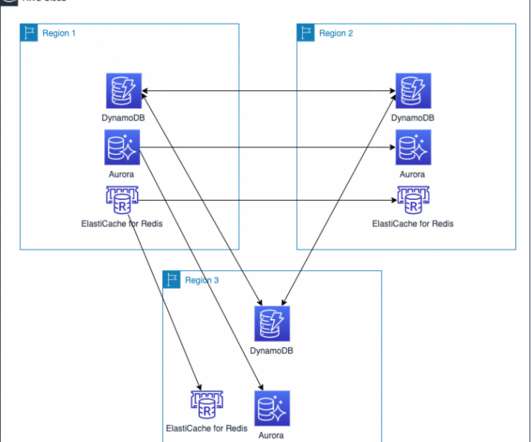
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Data is at the center of many applications. For this reason, data consistency must be considered when building a multi-Region application.
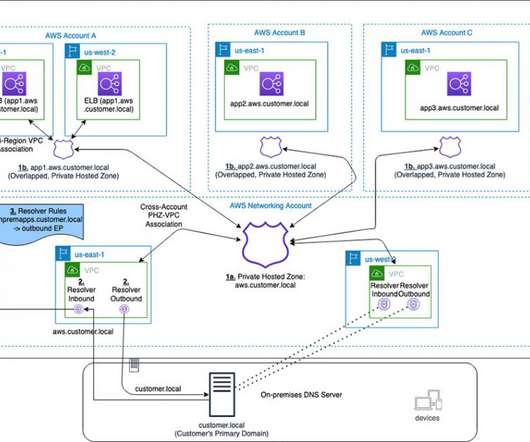
Many AWS customers have internal business applications spread over multiple AWS accounts and on-premises to support different business units. Route 53 Private Hosted Zones (PHZs) and Resolver endpoints on AWS create an architecture best practice for centralized DNS in hybrid cloud environment. Architecture Overview.
New capabilities include powerful tools to protect data and applications against ransomware and provide enhanced security with new Zerto for Azure architecture. Consolidated VPG State View— in addition to creating VPGs and performing failover operations, you can now view a simplified VPG state directly from the cloud console.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). DR implementation architecture on multi-Region active/passive workloads. Fail over with event-driven serverless architecture. This keeps RTO and RPO low.
Growing in both volume and severity, malicious actors are finding increasingly sophisticated methods of targeting the vulnerability of applications. Victims are either forced to pay the ransom or face total loss of business-critical applications. by protecting any application using continuous data protection (CDP).
In this blog, we talk about architecture patterns to improve system resiliency, why observability matters, and how to build a holistic observability solution. As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. The monolith application is tightly coupled with the database.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. When critical systems go down, you need more than just a chat tool.
Database contents change depending on the applications they serve, and they need to be protected alongside other application components. Application consistent replicas of MS SQL instances are achieved using the Microsoft VSS SQL Writer service. Read more about Protecting Microsoft SQL Server with Zerto Best Practices.
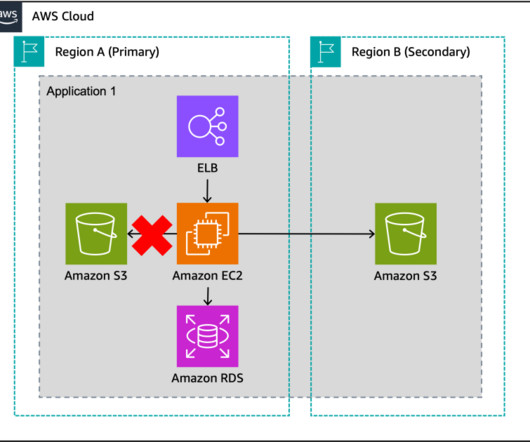
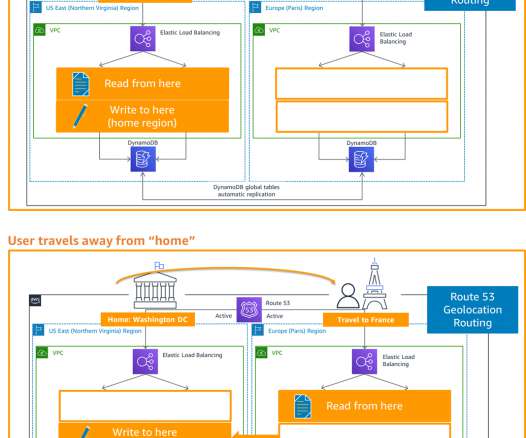
The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. To maintain low latencies and reduce the potential for network error, serve all read and write requests from the local Region of your multi-Region active/active architecture. DR strategies.
A zero trust network architecture (ZTNA) and a virtual private network (VPN) are two different solutions for user authentication and authorization. Now they need to access data using an internal business application. application username and password) to authenticate into the software and access data. What Is VPN?
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. In Part II, we’ll provide technical considerations related to architecture and patterns for resilience in AWS Cloud. Considerations on architecture and patterns.
In a disaster recovery scenario, there are two goals: Recovery time objective (RTO): Restoring critical applications as quickly as possible. It helps keep your multi-tier applications running during planned and unplanned IT outages. Recovery plans are an Azure Site Recovery feature; they define a step-by-step process for VM failover.
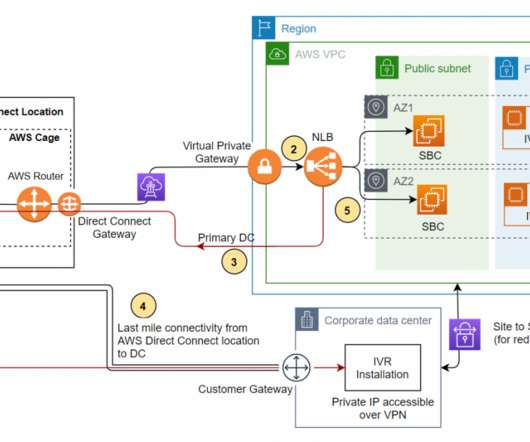
In other cases, the customer may want to use their home developed or third-party contact center application. This architecture enables customers facing challenges of cost overhead with redundant Session Initiation Protocol (SIP) trunks for the DC and DR sites. Solution architecture of DR on AWS for a third-party IVR solution.
Taming the Storage Sprawl: Simplify Your Life with Fan-in Replication for Snapshot Consolidation by Pure Storage Blog As storage admins at heart, we know the struggle: Data keeps growing and applications multiply. Enter your knight in shining armor—snapshot consolidation via fan-in replication.
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. Architecture overview. Looking for more architecture content?
When you deploy mission-critical applications, you must ensure that your applications and data are resilient to single points of failure. The unique architecture enables us to upgrade any component in the stack without disruption. . You can update the software on controller 2, then failover so that it’s active.
No application is safe from ransomware. This vulnerability is particularly alarming for organizations that are refactoring their applications for Kubernetes and containers. Refactoring” an application means breaking it down into many different “services” which can be deployed and operated independently.
In short, the sheer scale of the cloud infrastructure itself offers layers of architectural redundancy and resilience. . We get reminded repeatedly with each cloud outage that there is no such thing as a bullet-proof platform, and no matter where your applications and data reside, you still need a disaster recovery plan.
What if the very tools that we rely on for failover are themselves impacted by a DR event? In this post, you’ll learn how to reduce dependencies in your DR plan and manually control failover even if critical AWS services are disrupted. Failover plan dependencies and considerations. Let’s dig into the DR scenario in more detail.
Being able to migrate, manage, protect, and recover data and applications to and in the cloud using purpose-built cloud technologies is the key to successful cloud adoption and digital transformation. This feature can greatly help solutions architects design AWS DR architectures (2).
DR tries to minimize the impact a disaster has on applications, restoring them to a usable state as quickly as possible. SRE, on the other hand, is a discipline (and job title for many) that applies engineering practices to operations to improve the reliability and availability of the infrastructure that hosts applications.
Perform an entire site or applicationfailover, failback, and move without data loss or impact to production. There are additional differentiators like: Application-centric recovery for multi-VM applications. Recover an entire application and all its VMs to one single, consistent point in time.
Real-time replication and automated failover / failback ensure that your data and applications are restored quickly, minimizing downtime and maintaining business continuity. Granularity of recovery Solution: Zerto provides granular recovery options , allowing you to restore individual files, applications, or entire virtual machines.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
Let’s explore an application that processes payment transactions and is modernized to utilize managed services in the AWS Cloud, as in Figure 2. Warm standby with managed services Let’s cover each of the components of this application, as well as how managed services behave in a multisite environment.
Here, we delve into HA and DR, the dynamic duo of application resilience. High Availability is the ability of an application to continue to serve clients who are requesting access to its services. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
Educators need their applications available to reliably teach to our children, while constituents need access to emergency, financial and social services in their most critical time of need. Scalability and Performance: Zerto’s architecture is designed to scale and perform efficiently, even in large and complex environments.
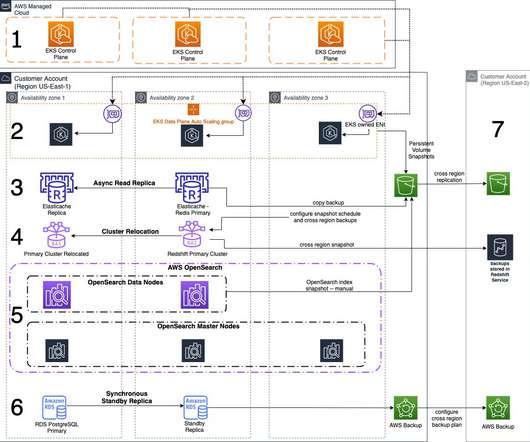
This strategy replicates workloads across multiple AZs and continuously backs up your data to another Region with point-in-time recovery, so your application is safe even if all AZs within your source Region fail. This example architecture refers to an application that processes payment transactions that has been modernized with AMS.
With more business-critical applications going on the cloud , it’s becoming extremely necessary for the organization to consider the internet as part of its core network. That move alone delivers better user experiences on your enterprise applications, providing high availability and improved latency. What is SD-WAN?
The HPE GreenLake cloud platform helps you modernize your business by bringing a cloud operational experience to all your applications and data. With HPE Greenlake you get a consistent view of all your applications and data from edge to cloud in the DSCC.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. Get started with Portworx—try it for free. .
Equally important is to look at throughput (units of data per second)—how data is actually delivered to the arrays in support of real-world application performance. For active applications, SSDs are commonly used since they offer faster IOPS. However, looking at IOPS is only half the equation. So in short, you should use both.
Docker is an open source platform for building and running applications inside of containers. Originally developed by Linux, containers have become an industry standard for application and software development. Figure 1: Docker architecture vs. VM architecture. What Is Docker and What Are Containers? Source: Docker.
IT organizations have mainly focused on physical disaster recovery - how easily can we failover to our DR site if our primary site is unavailable. First, which is much more easily obtained, is to host some applications in one cloud platform and other applications in another cloud platform.
This ensures our customers can respond and coordinate from wherever they are, using whichever interfaces best suit the momentso much so that even point products use PagerDuty as a failover. When critical systems go down, you need more than just a chat tool.
And many have chosen MySQL for their production environments for a variety of use cases, including as a relational database or as a component of the LAMP web application stack. But, because database applications like MySQL can be particularly demanding, it’s important to ensure the right resources are allocated to each virtual machine.
On-prem data sources have the powerful advantage (for design, development, and deployment of enterprise analytics applications) of low-latency data delivery. What Is a Non-Disruptive Upgrade (NDU)? – “Baked into the architecture of FlashArray™.” It has been republished with the author’s credit and consent.
It presents an opportunity to redefine your architecture. ActiveCluster provides seamless failover to deliver zero to near-zero RPO and RTO. . IT teams can reduce their risk exposure, streamline application and data recovery, and minimize management time. Some organizations have already started the transformation process.
This could be storage used by a hypervisor or other storage volumes used by physical servers, container solutions, or other types of applications. This does not easily allow for failover or recovery at a granular level. Recovery is therefore of the entire volume as well.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content