This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IT outages are a growing concern for financial entities, threatening both operational resilience and regulatory compliance. By addressing common challenges and adopting forward-thinking strategies, organizations can turn outages into stepping stones for achieving operational excellence.
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
A single service outage or poor customer experience can severely damage both revenue and brand reputation. Our interconnected nature magnifies issues The global IT outage of July 19 last year exemplifies how the interconnected nature of modern enterprises can amplify the impact of technical failures. The bottom line?
However, IT outages, as the one caused by a Crowdstrike update on July 19 th 2024, are inevitable and can disrupt business operations, leading to significant financial losses and reputational damage. Accelerated incident response and resolution for IT disruption One of the most critical aspects of managing IT outages is the speed of response.
And it connects people, technology, and process so that response feels seamless. A local protest, a regional outage, or a weather alert can impact dozens or hundreds of employees within minutes. That creates complexity, but it also creates opportunity, if youre ready for it. We use a simple framework: Know, Respond, Improve.
There was clearly a big outage and I quickly checked our systems at PagerDuty. Major outages happen multiple times per year, so frequently that we have an internal dashboard (colloquially referred to as “the internets are broken”). His team had just started implementing AIOps when the outage hit.
There was clearly a big outage and I quickly checked our systems at PagerDuty. Major outages happen multiple times per year, so frequently that we have an internal dashboard (colloquially referred to as “the internets are broken”). His team had just started implementing AIOps when the outage hit.
Powered by SafeMode and offered as an add-on to Evergreen//One, this SLA is all about delivering on our promise of resiliency and rapid recovery, plus advanced Pure AIOps security capabilities that empower customers to be proactive and alert.
Manufacturers must be prepared for all types of disruptive events such as severe weather activity, natural and man-made disasters, hazardous materials incidents, supply chain disruptions, and equipment and technology failures. Furthermore, manufacturers can be particularly susceptible to natural and technological crises.
Automation technologies allow you to set appropriate backup schedules, restore files and folders quickly, and provide better control over the backup and recovery processes. Data Migration Data migrations to new storage technologies or platforms are often necessary when implementing a new storage platform.
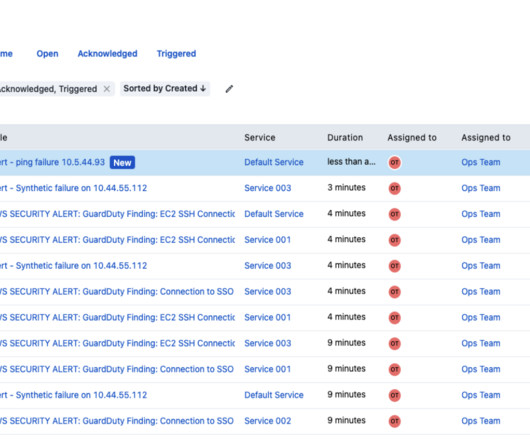
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. With manual processes and eyes-on-glass methods to handle this information, operations center engineers experience alert fatigue, making them prone to missing key signals and incorrectly prioritizing issues.
Increases in physical and digital disruption, such as civil unrest, cyberattacks, severe weather events, and unplanned outages, have left many industries scrambling to secure a robust operational resilience strategy, including the cellular industry. Protect and alert their workforce regardless of location with mass notification.
Prepare for power outages Ensure you have accurate contact information for employees, customers, and stakeholders to stay connected during power outages. This can include automated alerts, sirens, or mass messaging platforms to reach individuals across different locations.
New Security Industry Association (SIA) member Vunetrix offers a security network monitoring tool designed to detect real-time performance problems with IP security technologies across multiple geographics and report conditions through a user-friendly dashboard and automated email/SMS alerts.
Your Guide to Managed Information Technology (IT) Services. MSPs install wireless intrusion detection and prevention systems that not only enable protection but also alert the MSP of a security breach. Natural disasters, human errors, power outages, or cyberattacks can be detrimental to businesses. Consulting Services.
With little to no data to understand how and when power outages occur, it has become increasingly challenging for bioengineers to manage. . Nexleaf creates data and technology solutions for better health outcomes in low and middle income countries. Understand how alerts and data could help resolve power outages.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. With manual processes and eyes-on-glass methods to handle this information, operations center engineers experience alert fatigue, making them prone to missing key signals and incorrectly prioritizing issues.
Global outages and disruptions have become an inevitable reality for the modern enterprise. Operations teams face three critical challenges with each incident: Orchestrating the right responses across people, processes, and technologies. Gathering learnings from outages and transforming them into proactive improvements.
Powered by SafeMode and offered as an add-on to Evergreen//One, this SLA is all about delivering on our promise of resiliency and rapid recovery, plus advanced Pure AIOps security capabilities that empower customers to be proactive and alert.
This blog offers a comprehensive guide on best practices, communication readiness, and the critical role of technology in incident management. Understanding the impact of IT incidents Every day, operational issues such as IT outages and data breaches disrupt business operations.
Between net-zero goals, increasing energy costs, and decreasing grid reliability, utility companies are under more pressure than ever to go fully digital by leveraging the latest technologies to be as efficient and productive as possible. For example, the latest AMI meters provide alerts when your usage spikes. Costs AMI 2.0
Rather than building your own system, rely on established network management tools to automate configuration backups, track and highlight changes in real time, and alert you when unauthorized modifications occur. This gap exposes businesses to unnecessary risk, especially when a simple, automated network backup solution can close it.
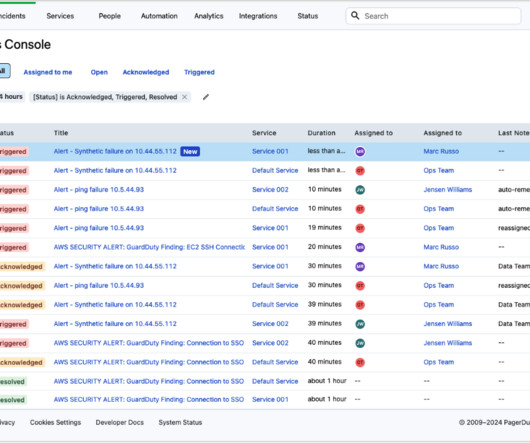
Our users expect our technology to be available and reliable at all times. Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. Alarms triggered in AWS generate alerts in PagerDuty that might result in incidents. It’s 2023. So, be prepared.
Protect your people, places and property by delivering alerts rapidly across your entire organization. Facility Incident Alerts Accidents happen. From leaks and spills to employee injuries, cyberattacks and workplace violence, your company needs a way to alert workers to an incident before it becomes a full-blown crisis.
Key technological components of running a successful retail location include managing web orders, integrating with third-party delivery services, handling order management, and supporting self-service checkout, among others. Our technical debt isn’t consistent—we have different generations of technology in nearly every store.
Critical vendors require deeper dives, including a thorough review of their business continuity plan, a record of any historical outages, a more frequent review of their financials, and an in-depth analysis of their SOC2 report. Establish guidelines and alerts for continuous monitoring.
This designation recognizes Takeda for employing “best in class” Critical Event Management (CEM) processes and technologies to power organizational resilience. The Technical Account Manager (TAM) provides expert consultation and support to ensure they are maximizing the use of their tools and technologies.
Complementing these are Customer Service Continuity and Workforce Continuity Plans, guaranteeing that customer-facing functions and workforce well-being remain priorities during outages or emergencies. Moreover, Continuous Process Improvement keeps leadership alert to emerging trends and agile in adapting to new realities.
It’s a passwordless solution that validates would-be users through several layers of technology to make sure they are who they say they are. So what happens when, during an outage, employees start attempting to use backup devices, such as their home computers, to access the network?
While competing solutions start the recovery process only after AD goes down, Guardian Active Directory Forest Recovery does it all before an AD outage happens. This helps minimize downtime in the event of outages or cyberattacks.
A different kind of partnership One key barrier to Intelehealth’s progress was the platform’s persistent and time-consuming technical outages and team mobility issues, further straining their resources. We want as much collaboration as possible.”
Click here to read part on e on eradicating change management outages. Operationalization, in the context of technology, refers to the process of integrating FlashArray ™ or FlashBlade ® features into the everyday operational framework of an organization.
Whether it’s receiving crucial banking alerts, getting updates from our favorite retailers, or even surfacing a notification from PagerDuty when your service is down–SMS keeps us informed and connected. But have you ever wondered about the intricacies behind this seemingly straightforward technology?
An organization’s ability to recover from a disaster requires careful planning, testable processes, and the right technology. The disaster recovery plan must also contain a contingency plan: What is plan B in the case of an outage, who will guide personnel through plan B, and how will employee training be conducted?
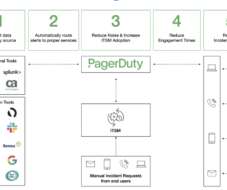
According to our conversation, Carlos has divided the AIOps market into two camps: technology-centric (primarily APM/Observability players) and process-centric. PagerDuty is a process-centric solution leveraging multiple technologies. Providing all impacted individuals with this clean data signal is vital to improving operations.
With regard to data management, the two sections of that technology crucial to data protection software are data lifecycle management and information lifecycle management. Additionally, the solution offers ransomware detection, alerting and notification, remediation capabilities, and is available in AWS, Azure, Google, IBM, and Alibaba.
When considering IT systems, a SLA helps organizations conduct high-level risk assessments by detailing the requirements for availability, reliability, and the acceptable number of outages for the service provided. guaranteed uptime and allow a maximum of two outage events per year, lasting not more than three hours each.
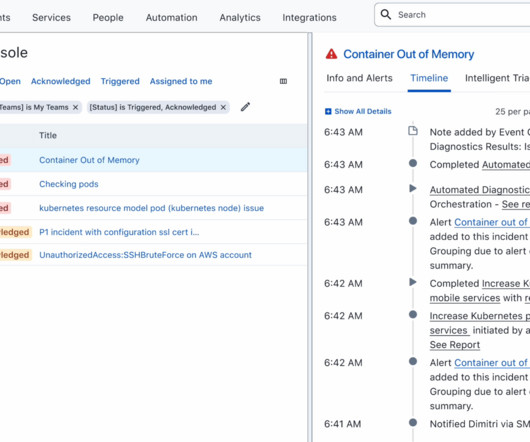
Monitoring and alerting : The AIOps capabilities of the PagerDuty Operations Cloud are built on our foundational data model and trained on over a decade of customer data. Alert Routing, call-out, and escalation : PagerDuty allows firms to define notification protocols for different types of incidents based on urgency and severity.
Issues are first identified by customers—rather than by technology teams—and urgent issues are manually escalated by a central team through the changing of ticket priorities. Technology teams have started shifting from centralized to distributed technical teams, but lack coordination and/or skill sharing.
The advancement of technology and complexity of internal systems, tooling, and processes have only made matters worse. But what if the problem requires the assistance of back-office Engineering/Developer/IT resources to resolve a core issue, such as an outage or a bug? . In our example, Eng/Dev/IT are unaware. How long will it take?
Our users expect our technology to be available and reliable at all times. Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. Alarms triggered in AWS generate alerts in PagerDuty that might result in incidents. It’s 2023. So, be prepared.
They could also come from non-natural sources; such threats would include theft, sabotage, terrorism, power outages, civil unrest and so many more. All sources are not equal: An alert from NOAA is very different from a raw Tweet by someone you do not know. Many of the points made apply to other risk areas. Future Intelligence Sources.
Automation refers to the use of technology to perform tasks or processes without human intervention. Monitoring and Alerting Automated monitoring solutions like Prometheus or Nagios continuously monitor system performance and health metrics, triggering alerts or automated remediation actions in case of anomalies or failures.
You need to ensure the incident is moving forward, the right teams are working on it, and stakeholders and customers are receiving accurate and timely updates about the outage. After all, your entire technology workflow depends on it. These alerts are filtered through our noise reduction feature to help your teams stay focused.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content