This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
However, IT outages, as the one caused by a Crowdstrike update on July 19 th 2024, are inevitable and can disrupt business operations, leading to significant financial losses and reputational damage. Accelerated incident response and resolution for IT disruption One of the most critical aspects of managing IT outages is the speed of response.
And ultimately, it’s not a matter of if you will have an outage, but of when. Before an outage… 1. During an outage… 3. Increase situational awareness during incident triage Give responders access to contextual information the moment they’re paged about an incident. After an outage… 8.
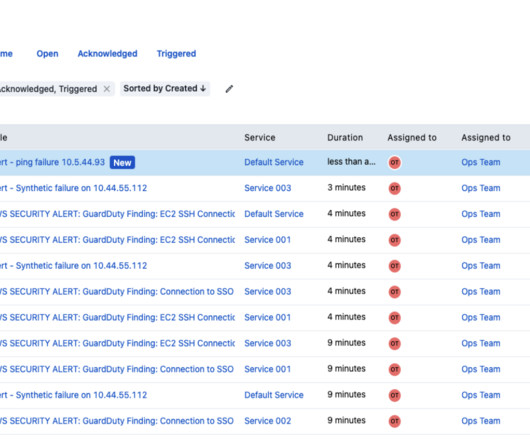
From managing global outages to addressing complex digital operations, the PagerDuty Operations Cloud enabled organizations to respond faster, work smarter, and build operational resilience. The new alert side panel offers visibility into alerts and metadata. Take the product tour. All generally available for AIOps customers.
And ultimately, it’s not a matter of if you will have an outage, but of when. Before an outage… 1. During an outage… 3. Increase situational awareness during incident triage Give responders access to contextual information the moment they’re paged about an incident. After an outage… 8.
When the incident begins it might only be impacting a single service, but as time progresses, your brain boots, the coffee is poured, the docs are read, and all the while as the incident is escalating to other services and teams that you might not see the alerts for if they’re not in your scope of ownership.
Every day, events like the following happen with no warning: Hurricanes, tornadoes, and other natural disasters Active shooter Urban wildfire Power outages Cybercrime Disease outbreaks Workplace violence. To ensure your crisis alerting is accurate and timely, here are three essential tips to follow: 1.
Built-in genAI , powered by PagerDuty Advance, quickly surfaces and summarizes key information directly from the chat, providing contextual support and enhancing collaboration and communication. Learn more about the PagerDuty Operations Cloud platform and how we can help teams like yours stay ahead of outages by taking this product tour.
Operations Center Modernization Our latest innovations help teams focus on high-impact incidents, applying automation to proactively resolve issues before they escalate into outages. By standardizing updates, teams save valuable time and deliver accurate information to customers. Sign up for early access (AIOps customers only).
Audience-Specific Status Pages (GA) : Deliver targeted service information and status updates to different stakeholder groups from a single interface, ensuring relevant communication while maintaining operational efficiency. Teams will be able to automate routine response actions while maintaining oversight through approval workflows.
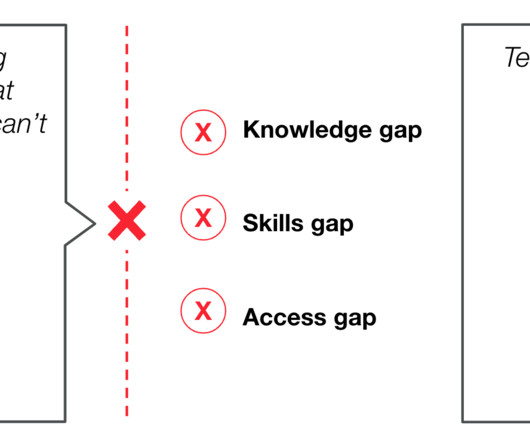
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. With manual processes and eyes-on-glass methods to handle this information, operations center engineers experience alert fatigue, making them prone to missing key signals and incorrectly prioritizing issues.
This information will be important after an event when determining if there is too much snow on the roof. Avoiding a power outage can save a day or two of business interruption. Select a heating system repair service before an unexpected outage or maintenance issue arises mid-season. Prevent plumbing from freezing.
This includes utilizing various communication channels such as email, SMS, phone calls, and social media updates to keep everyone informed and safe. Prepare for power outages Ensure you have accurate contact information for employees, customers, and stakeholders to stay connected during power outages.
Increases in physical and digital disruption, such as civil unrest, cyberattacks, severe weather events, and unplanned outages, have left many industries scrambling to secure a robust operational resilience strategy, including the cellular industry. Protect and alert their workforce regardless of location with mass notification.
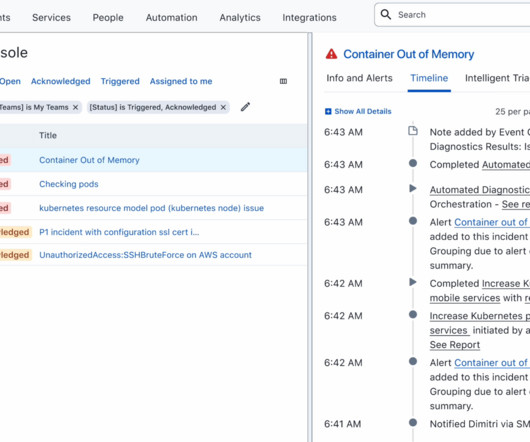
At this point in the incident lifecycle you have controlled the fire hose of alerts coming from sources all around your organisation, and you have automated the mobilisation of the correct on-call responder only for the relevant actionable items. We have previously mentioned the known and repeatable requirements that automation generally has.
Whether you’re safeguarding cloud workloads or securing petabytes of mission-critical data, the wisdom shared here is designed to inform, inspire, and elevate your data resilience strategy. Without proper oversight, sanctioned and unsanctioned SaaS applications can leave sensitive business information exposed.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. With manual processes and eyes-on-glass methods to handle this information, operations center engineers experience alert fatigue, making them prone to missing key signals and incorrectly prioritizing issues.
Your Guide to Managed Information Technology (IT) Services. Cybersecurity concerns have become more prominent as personal information is stolen from businesses, and websites are taken hostage by ransomware. Natural disasters, human errors, power outages, or cyberattacks can be detrimental to businesses. Cybersecurity.
New Security Industry Association (SIA) member Vunetrix offers a security network monitoring tool designed to detect real-time performance problems with IP security technologies across multiple geographics and report conditions through a user-friendly dashboard and automated email/SMS alerts. It is all about knowing what you cannot see.
Global outages and disruptions have become an inevitable reality for the modern enterprise. Gathering learnings from outages and transforming them into proactive improvements. Global Intelligent Alert Grouping is now available in early access for AIOps customers. Sign up here.
Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. Keep this information handy and make sure it is up to date as part of your incident preparedness. This dependence has brought risk.
Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. This reduces the number of incidents created and enriches existing ones with relevant information that will help you identify the root cause of the issue. So, be prepared.
They enabled utility companies to remotely monitor electricity, connect and disconnect service, detect tampering, and identify outages. lets you better monitor energy usage in real time or near real time, allowing you to make more informed decisions about your consumption habits. In that sense, everyone stands to gain from AMI 2.0,
Understanding the impact of IT incidents Every day, operational issues such as IT outages and data breaches disrupt business operations. Integrating monitoring and ITSM platforms with communication solutions ensures seamless information flow, enabling faster response times and reducing Mean Time to Repair (MTTR).
When facing a critical breach or outage in physical security systems, teams need to understand the where and when in real-time. Applying the principles of digital operations with real-time alerting and automation is key to better insights and actionable information. PagerDuty’s 650+ integrations (e.g., Slack, Teams, Zoom, etc.),
Takeda earned Gold Tier status in 2021 and has since implemented many improvements to optimize their ability to detect and assess risks, coordinate with crisis response teams, communicate emergency information to employees, and account for their safety. Takeda earned high marks in each competency area.
Protect your people, places and property by delivering alerts rapidly across your entire organization. Facility Incident Alerts Accidents happen. From leaks and spills to employee injuries, cyberattacks and workplace violence, your company needs a way to alert workers to an incident before it becomes a full-blown crisis.
So what happens when, during an outage, employees start attempting to use backup devices, such as their home computers, to access the network? Just as with equipment, BC and IT need to work together in advance to make sure all alternate workers whose participation is anticipated by the recovery plan will have system access during an outage.
For more information about this and the various migration options , we’ve outlined everything in this Knowledge Base article. Event Orchestration can help teams stay focused on only critical events by only interrupting responders with the most important, time-critical alerts. These can be seen in the “Alerts” menu. .
Critical vendors require deeper dives, including a thorough review of their business continuity plan, a record of any historical outages, a more frequent review of their financials, and an in-depth analysis of their SOC2 report. Establish guidelines and alerts for continuous monitoring.
Monitoring and alerting : The AIOps capabilities of the PagerDuty Operations Cloud are built on our foundational data model and trained on over a decade of customer data. Alert Routing, call-out, and escalation : PagerDuty allows firms to define notification protocols for different types of incidents based on urgency and severity.
The lifecycle of managing a critical event is built on five foundational pillars: Plan, Monitor, Alert, Respond, and Improve. Enhanced communication capabilities accelerate the dissemination of critical information and facilitate collaboration across the enterprise, significantly reducing response times during crises.
Those days are gone, thankfully, replaced by a different problem: a continuously growing ocean of information that’s available to you instantly, in a plethora of different formats. They could also come from non-natural sources; such threats would include theft, sabotage, terrorism, power outages, civil unrest and so many more.
The disaster recovery plan must also contain a contingency plan: What is plan B in the case of an outage, who will guide personnel through plan B, and how will employee training be conducted? Consistency: Every department and group must be communicating the same information and scripted talking points.
While competing solutions start the recovery process only after AD goes down, Guardian Active Directory Forest Recovery does it all before an AD outage happens. This helps minimize downtime in the event of outages or cyberattacks.
Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. Keep this information handy and make sure it is up to date as part of your incident preparedness. This dependence has brought risk.
Production outages are scary for everyone, but with the right system monitoring solution, they can be made less stressful. After few outages of our application, we realized we needed to re-think holistically and not add metrics on one-time basis. This enables alerts when we are close to reaching quotas. Related information.
This means that they are responsible for providing always-available application services that are hosted on resilient infrastructure and maintaining data copies to withstand infrastructure failures or site-wide outages. Storage Requirements. Frequent backup ability to support the recovery point objectives defined earlier.
As businesses today face a spectrum of issues, from major technical failures to cloud service disruptions and cybersecurity threats, they must be in a constant state of alert and preparation. Aside from the immediate loss of revenue and customer trust, these organisations now face significant financial and operational consequences.
Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. This reduces the number of incidents created and enriches existing ones with relevant information that will help you identify the root cause of the issue. So, be prepared.
With regard to data management, the two sections of that technology crucial to data protection software are data lifecycle management and information lifecycle management. Additionally, the solution offers ransomware detection, alerting and notification, remediation capabilities, and is available in AWS, Azure, Google, IBM, and Alibaba.
When considering IT systems, a SLA helps organizations conduct high-level risk assessments by detailing the requirements for availability, reliability, and the acceptable number of outages for the service provided. guaranteed uptime and allow a maximum of two outage events per year, lasting not more than three hours each.
Audience-Specific Status Pages (GA) : Deliver targeted service information and status updates to different stakeholder groups from a single interface, ensuring relevant communication while maintaining operational efficiency. Teams will be able to automate routine response actions while maintaining oversight through approval workflows.
It’s not just revenue that takes a hit every time you have an outage–brand reputation and client satisfaction are also on the line. If you’ve only been using the platform for on-call and alerting, it’s time to consider how you could achieve your cost-optimization goals with PagerDuty. Incidents are costly.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content