This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Turning Setbacks into Strengths: How Spring Branch ISD Built Resilience with Pure Storage and Veeam by Pure Storage Blog Summary Spring Branch Independent School District in Houston experienced an unplanned outage. Theres nothing fun about dealing with an unplanned outage.
When the incident begins it might only be impacting a single service, but as time progresses, your brain boots, the coffee is poured, the docs are read, and all the while as the incident is escalating to other services and teams that you might not see the alerts for if they’re not in your scope of ownership. Common incident challenges.
The PagerDuty Operations Cloud is an end-to-end enterprise-grade platform that delivers on all these strategies, helping teams stay connected during system disruptions, across multiple channels: Web: Offers comprehensive alert visibility from a single dashboard with the recently enhanced Operations Console.
System Monitoring and Alerting Monitoring and alerting allows IT teams to detect and respond to critical issues in real time, helping to prevent costly failures or outages. That way, the new platform supports a new, more efficient way of doing business. Don’t just accept “that’s why they call it work”—automate.
Despite basic out-of-the-box protection from SaaS vendors, data residing in SaaS applications is your responsibility, not the vendor’s. This data is exposed to potential risks like outages, accidental deletion, and ransomware attacks that can lead to loss or downtime. Why Monitoring and Analyzing your SaaS Backup Data is important?
When critical applications suffer performance degradation—or worse yet, a full outage—engineers rush to find the (apparent) cause of the incident, such that they can remediate the issue as fast as possible. Grab all the evidence: Capturing application state for post-incident forensics. Stay inquisitive, my fellow detectives.
At this point in the incident lifecycle you have controlled the fire hose of alerts coming from sources all around your organisation, and you have automated the mobilisation of the correct on-call responder only for the relevant actionable items. MIM : Populate incidents with automated diagnostics and normalise event data so it’s consumable.
Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. FlashArray ActiveWorkload Launched— ActiveWorkload brings non-disruptive workload migrations to FlashArray.
Prepare for power outages Ensure you have accurate contact information for employees, customers, and stakeholders to stay connected during power outages. This can include automated alerts, sirens, or mass messaging platforms to reach individuals across different locations.
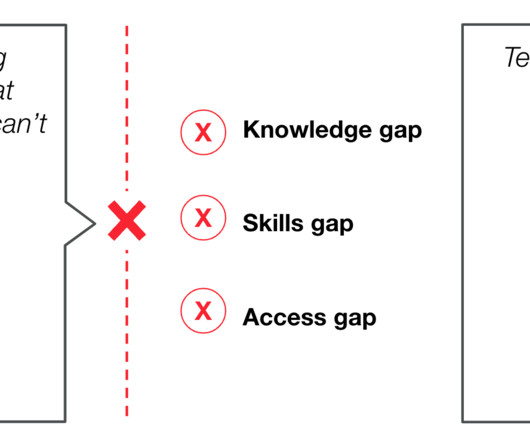
With little to no data to understand how and when power outages occur, it has become increasingly challenging for bioengineers to manage. . Without data showing exactly how long and costly these outages are, it’s difficult for these hospitals to justify additional funds. Nexleaf Analytics is working to solve this challenge.
As a refresher from previous blogs, our example ecommerce company’s “Shoppers” application runs in the cloud. It is a monolithic application (application server and web server) that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance. The monolith application is tightly coupled with the database.
Without proper oversight, sanctioned and unsanctioned SaaS applications can leave sensitive business information exposed. When backups of sanctioned SaaS applications do exist, overlooked SaaS data often goes unprotected. Shadow IT and shadow AI remain a major source of headaches for IT teams. That starts with immutable storage.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. The Best Data Protection Software.
Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. Alarms triggered in AWS generate alerts in PagerDuty that might result in incidents. They can result in the creation of a new alert and/or incident, or the update or resolution of an existing one.
The cloud providers have no knowledge of your applications or their KPIs. Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. This dependence has brought risk. How should a team handle an incident that lies with an upstream provider?
When it comes to SaaS applications running in the cloud, there are a number of unique considerations. This means that they are responsible for providing always-available application services that are hosted on resilient infrastructure and maintaining data copies to withstand infrastructure failures or site-wide outages.
Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. FlashArray ActiveWorkload Launched— ActiveWorkload brings non-disruptive workload migrations to FlashArray.
In the context of computing, container orchestration specifically refers to the management of containerized applications, where containers encapsulate an application and its dependencies, making it portable and scalable across different computing environments.
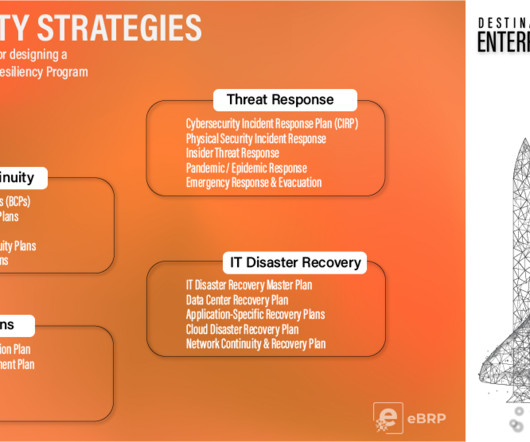
Disaster recovery comprises a set of policies or procedures designed to ensure effective communication during the event and facilitate the return to normal operations, the recovery of IT systems, and the restoration of uptime for mission-critical applications. Both tasks require assessment of business impact and risk analyses.
Complementing these are Customer Service Continuity and Workforce Continuity Plans, guaranteeing that customer-facing functions and workforce well-being remain priorities during outages or emergencies. Moreover, Continuous Process Improvement keeps leadership alert to emerging trends and agile in adapting to new realities.
Monitoring and alerting : The AIOps capabilities of the PagerDuty Operations Cloud are built on our foundational data model and trained on over a decade of customer data. Alert Routing, call-out, and escalation : PagerDuty allows firms to define notification protocols for different types of incidents based on urgency and severity.
There’s no denying it: in today’s interconnected world, Application-to-Person (A2P) SMS notifications have become an integral part of our daily lives. A2P SMS often faces disruptions due to network outages or planned maintenance, affecting message delivery. Plan for Change SMS regulations are a moving target.
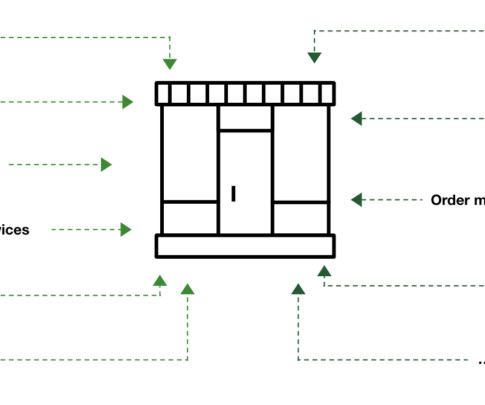
Caption: Examples of different services and applications in a distributed/remote store infrastructure. Each location represents a potential point of failure, with challenges ranging from in-store IT operations like patching, monitoring, and software updates, to in-store merchandising, such as real-time displays and in-store applications.
When considering IT systems, a SLA helps organizations conduct high-level risk assessments by detailing the requirements for availability, reliability, and the acceptable number of outages for the service provided. guaranteed uptime and allow a maximum of two outage events per year, lasting not more than three hours each.
Microsoft Azure is a pay-as-you-go cloud computing platform where businesses can host their data as well as build, manage and deploy their applications anywhere. Built-in protection against ransomware alerts you to an unauthorized request, and multifactor authentication stops cyber threats from accessing your data.
As businesses today face a spectrum of issues, from major technical failures to cloud service disruptions and cybersecurity threats, they must be in a constant state of alert and preparation. Aside from the immediate loss of revenue and customer trust, these organisations now face significant financial and operational consequences.
It’s not just revenue that takes a hit every time you have an outage–brand reputation and client satisfaction are also on the line. If you’ve only been using the platform for on-call and alerting, it’s time to consider how you could achieve your cost-optimization goals with PagerDuty. Incidents are costly. Learn more. .
The cloud providers have no knowledge of your applications or their KPIs. Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. This dependence has brought risk. How should a team handle an incident that lies with an upstream provider?
Complex IT systems have several failure points, and it only takes one system change to cause a domino effect of failures and outages. Those outages could lead to websites and applications going offline, ecommerce sites no longer taking orders, or end-users being without a crucial service.
Inevitably, something will fail unexpectedly, and chaos will rise during times of stress, such as incidents and service outages. Alarms triggered in AWS generate alerts in PagerDuty that might result in incidents. They can result in the creation of a new alert and/or incident, or the update or resolution of an existing one.
You need to ensure the incident is moving forward, the right teams are working on it, and stakeholders and customers are receiving accurate and timely updates about the outage. When you experience a failure, PagerDuty takes signals from all of your tools and automatically routes alerts to the proper services.
Click here to read part on e on eradicating change management outages. This goes beyond initial setup, delving into ongoing management, optimization, monitoring and alerting, and alignment with data protection policies and recovery objectives. Such integration boosts data protection and recovery capabilities significantly.
The PagerDuty Operations Cloud is an end-to-end enterprise-grade platform that delivers on all these strategies, helping teams stay connected during system disruptions, across multiple channels: Web: Offers comprehensive alert visibility from a single dashboard with the recently enhanced Operations Console.
Reactive organizations have some initial technology investments to gain visibility and real-time mobilization as they begin migrating to the cloud and maturing their applications into more complex digital services.
Move any workload seamlessly, including BC/DR, migration to new hardware, or application consolidation. FlashArray ActiveWorkload Launched— ActiveWorkload brings non-disruptive workload migrations to FlashArray.
As one of our first time-critical health grantees, Nexleaf used grant funding and PagerDuty’s incident response platform, with technical pro bono support from PagerDuty employees, to enhance the delivery of power outagealerts and make them more useful for healthcare workers in 13 under-resourced health facilities in Kenya.
. ——————————– Part 1: Detect: Filtering the Noise In the midst of all the chaos from recent outages and incidents this year, we would bet that somewhere in all the noise was the alert that truly mattered. People are becoming numb to alerts, making them less effective.
These principles ensure the availability of critical application data so the organization can quickly resume operations from natural or malicious incidents. They provide a secure, resilient data foundation to help you deliver dependable applications and services, , cybersecurity, and even compliance outcomes.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























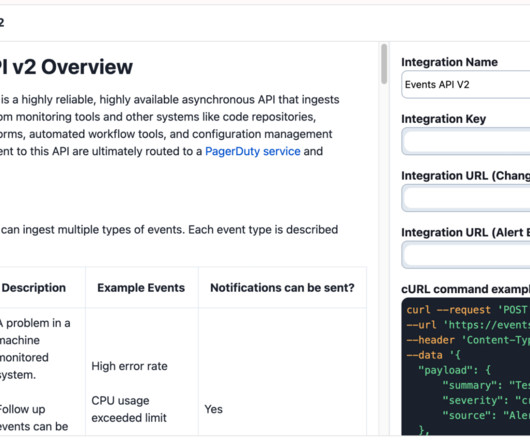
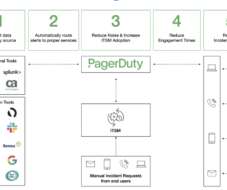












Let's personalize your content