This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
6 Customer-proven Best Practices for Cyber-resilient Backup and Recovery by Pure Storage Blog Summary From the 3-2-1-1-0 framework to indelible data to faster threat detection, cyber resilience best practices can help organizations safeguard their operations and recover quickly and confidently when the worst happens.
And how to become resilient with ISO 27001 and ISO 22301 Unfortunately, even the most secure organisation can suffer an incident. This is where cyber resilience comes in. Cyber resilience combines cyber security with the ability to detect, respond to and recover from cyber incidents. How will you ensure operational resilience?
In the world of Enterprise Resiliency, being “ready” isn’t just about having a plan it’s about proving that plan works under pressure. What True Resiliency Testing Looks Like To truly evaluate your organization’s readiness, testing must be comprehensive, data-driven , and operational.
With the global surge in cybercrime—particularly ransomware attacks —and occasional outages of cloud services , enterprise risk management is just the latest initiative that needs attention. What would happen to your organization’s day-to-day operations if your Microsoft Azure Active Directory (Azure AD) stopped working?
A radical shift toward lean and modern Network Operations Centers (NOCs), digital resilience, and a relentless pursuit of inefficiencies. Modernizing NOC operations by adopting a lean approach will streamline operations, reduce costs, and ensure IT systems are optimized for performance and resilience. The solution?
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. Why didn’t they activate their Disaster Recovery Plan? In the outage described above, the IT organization response was delayed by almost two hours and was initially sluggish.
The post also introduces a multi-site active/passive approach. The multi-site active/passive approach is best for customers who have business-critical workloads with higher availability requirements over other active/passive environments. You would just need to create the records and specify failover for the routing policy.
Though ransomware has dominated conversations in the data protection sphere for quite some time, stories of recent outages due to this threat still circulate. A colleague and I hosted a riveting session on the Zerto Cyber Resilience Vault , a roundtable discussion that garnered so much interest we had to accommodate an overspill.
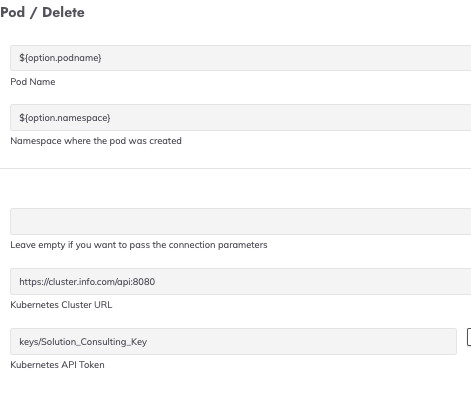
This can easily be extended to any activity within the Kubernetes ecosystem, and 23 plugins are available for tasks such as maintaining PVs, deploying services, grabbing logs, or running internal jobs. Any drift from this configuration can be corrected by reapplying the Terraform plan. Automated backups ensure that data is always recoverable.
Service outages ultimately frustrate customers, leading to churn and loss of trust. This is a key part of becoming cyber resilient. Continuously monitor system logs to detect unusual activity, such as failed login attempts or unauthorized data transfers. To fix these vulnerabilities: 1.
When it comes to major technological disruptions, cloud service outages, and cybersecurity threats, businesses must be proactive and prepared. Actionable Insights Reduced downtime isn’t just about saving time—it’s about understanding the true cost of inaction and actively implementing measures to minimise it.
As a fast follow to our recent launch , this quarter’s wrap-up blog highlights our latest product innovations and upcoming features—all designed to enhance your operational resilience and drive meaningful business outcomes by reducing risk and strengthening your ability to adapt and respond effectively.
This automation reduces the burden on IT staff, enabling them to respond to incidents more quickly while focusing on customer service-oriented and strategic activities. Increased operational resilience : A quick response and recovery from IT incidents and outages help institutions mitigate risks associated with system outages or delays.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. However, leading companies are using automation to manage chaos, drive innovation, and build the operational resilience required for modern digital businesses.
In the context of business and organizations, “continuity” refers to the ability of a company or other type of organization to quickly restore its essential functions, operations, and services in the face of unexpected disruptions or outages. The Move to “Resilience” Another word worth mentioning in this discussion is “resilience.”
This data is exposed to potential risks like outages, accidental deletion, and ransomware attacks that can lead to loss or downtime. Moreover, monitoring data activities allows organizations to proactively detect and respond to security threats, such as unauthorized access or data breaches.
The activity of crisis management is also included under the umbrella though that tends to be treated separately.) Its criticality points up the need for everyone involved in improving the organization’s resilience to have a clear understanding of these two fundamental terms and activities.
Business continuity professionals who want to make their organizations more resilient should make a conscious effort to become gap hunters. It’s a practical, down-to-earth approach that focuses on small things, but it has the power to bring big gains to an organization’s resilience,” he wrote. This can be crippling during an outage.
Manufacturers must be prepared for all types of disruptive events such as severe weather activity, natural and man-made disasters, hazardous materials incidents, supply chain disruptions, and equipment and technology failures. WHITE PAPER: ENTERPRISE RESILIENCE DURING SEVERE WEATHER. The Importance of Building a Plan.
The recent global IT outage is a stark reminder that even the most advanced organizations can have bad days. We’ve also invested heavily in cultivating personal resilience among our employees. By fostering a supportive environment, we ensure that our employees are not just technically prepared, but mentally resilient as well.
Using multiple Regions ensures resiliency in the most serious, widespread outages. The Amazon EKS control plane and data plane will be created on demand in the secondary Region during an outage via Infrastructure-as-a-Code (IaaC) such as AWS CloudFormation , Terraform, etc. DR Strategies. Architecture overview.
Residual Risk There are two main kinds of risk when it comes to organizational activities and business continuity: inherent risk and residual risk. Inherent risk is the danger intrinsic to any business activity or operation. Residual risk is the amount of risk that remains in an activity after mitigation controls are applied.
The recent global IT outage is a stark reminder that even the most advanced organizations can have bad days. We’ve also invested heavily in cultivating personal resilience among our employees. By fostering a supportive environment, we ensure that our employees are not just technically prepared, but mentally resilient as well.
Related on MHA Consulting: Sounds Like a Plan: The Elements of a Modern Recovery Plan Everyone reading this blog will know that the business continuity (BC) recovery plan is something organizations create to help them quickly restore their essential operations in the event of an outage, minimizing the impact on the company.
In today’s world, organizations face unprecedented challenges that require a new approach to resilience. Organizations that embrace, invest in, and elevate resilience as a strategic priority are able to more proactively sense issues, analyze vulnerabilities, and adapt to the evolving environment. million customers.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. However, leading companies are using automation to manage chaos, drive innovation, and build the operational resilience required for modern digital businesses.
Instructions about how to use the plan end-to-end, from activation to de-activation phases. Since most businesses today are heavily IT reliant, DRP tends to focus on business data and information systems by addressing one or several points of failure including application downtime, network outages, hardware failure, data loss, etc.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . This replication type can provide near-zero recovery point objectives. .
When an IT outage strikes, the primary concern is the rapid restoration of services. The correct action, especially in the face of a service outage, would be to opt for a swift rollback of the change that introduced the bug. Striking a balance between these two is essential for maintaining a robust and resilient IT environment.
Follow these seven steps to implement a BC strategy that can help you swiftly recover your business processes in the event of an outage. We at MHA are happy to participate in these types of conversations and activities. BC strategy development is not a “one and done” activity.
As lead solutions architect for the AWS Well-Architected Reliability pillar , I help customers build resilient workloads on AWS. Active/passive and active/active DR strategies. Active/passive DR. Figure 2 categorizes DR strategies as either active/passive or active/active.
While the technological and societal transformations underway are likely positive in the long term, they are also creat ing demand for new resilience measures. But how can you build resilience with in your organization? Operational Risk and Resilience Teams Need to Balance a Complex Agenda Now more than ever, resilience is essential.
Organizations now have to contend with a heightened risk of drought, flooding, heat waves, wildfires, hurricanes, political unrest, global conflict, cyberattack, power outages, active shooters, supply chain disruptions, pandemic, social-media impacts, and all the rest. Operational resilience.
Whether you’re safeguarding cloud workloads or securing petabytes of mission-critical data, the wisdom shared here is designed to inform, inspire, and elevate your data resilience strategy. By adhering to these practices, organizations can enhance their data backup strategies and ensure resilience against potential risks.”
We are living in a golden age in terms of the easy availability of high-quality information on how organizations can make themselves more resilient. Anything and everything is out there regarding how you can protect your organization and its stakeholders from disruptions and recover quickly when outages occur. Other BCM professionals.
In this feature, Clumio co-founder and CTO Woon Ho Jung offers commentary on achieving data resiliency with data classification and the shared responsibility model. This is critical for compliance audits and proving disaster resilience. The biggest myths in AWS architecture are often related to resilience.
But in our current period of an ever-expanding set of global threats, most organizations would benefit from developing a system for actively monitoring potential threats to their operations and assets. They help organizations anticipate, avoid, and prepare for impacts, saving money and improving resiliency.
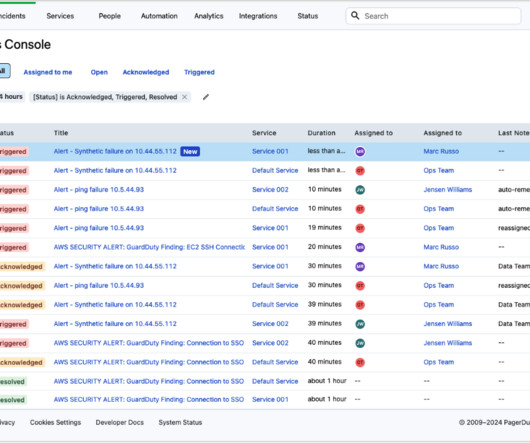
When we talk to our customers about operational resiliency, three common themes come up: Teams don’t spend enough time on preventative design. Immutable centralized incident record : PagerDuty provides a time-stamped log of all activities and resolution steps relating to an incident.
EMEA: With the implementation of DORA, it is now even more critical for financial services leaders to work alongside trusted IT partners with digital operational resiliency capabilities to reduce or avoid the impact of an outage and accelerate the time to restore normal service. GA following in early March. Read more here.
Organizations that implement a backup strategy with cyber resilience at the core can enable restores that are fast, predictable, reliable and cost-effective – at scale. Rapid recovery with no downtime and no data loss helps businesses of all sizes achieve true resilience and bounce back no matter what comes along.
Knowing what roles should be represented on the business continuity management (BCM) team and what kind of people should fill them is an overlooked key to success in making organizations resilient. Legal: The legal team can provide important insight on the legal ramifications of activities performed in response to an emergency.
Here, we delve into HA and DR, the dynamic duo of application resilience. Learn what they are, some benefits and drawbacks, and the reasons why you should embrace both when developing your highly resilient IT operations. An active-active cluster architecture is actively running the same service simultaneously on two or more nodes.
Top Storage and Data Protection News for the Week of September 27, 2024 Cayosoft Secures Patent for Active Directory Recovery Solution Cayosoft Guardian Forest Recovery’s patented approach solves these issues by functioning as an AD resilience solution rather than a typical backup and recovery tool.
It’s simple to activate snapshots and set up replication, which can help you facilitate quick recovery in the event of a system failure or data loss. . It is reasonable to expect that increased telecommuting could trigger certain elements of your business continuity plan — either due to outage or load.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content