This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. Why didn’t they activate their Disaster Recovery Plan? In the outage described above, the IT organization response was delayed by almost two hours and was initially sluggish.
The post also introduces a multi-site active/passive approach. The multi-site active/passive approach is best for customers who have business-critical workloads with higher availability requirements over other active/passive environments. You would just need to create the records and specify failover for the routing policy.
Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other other localized disruptions, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need. Active/passive and active/active DR strategies. In Figure 3, we show how active/passive works.
Customers only pay for resources when needed, such as during a failover or DR testing. This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. JetStream replicates VMs and data into blobs, and compute resources (hosts) can be allocated on demand on failover.
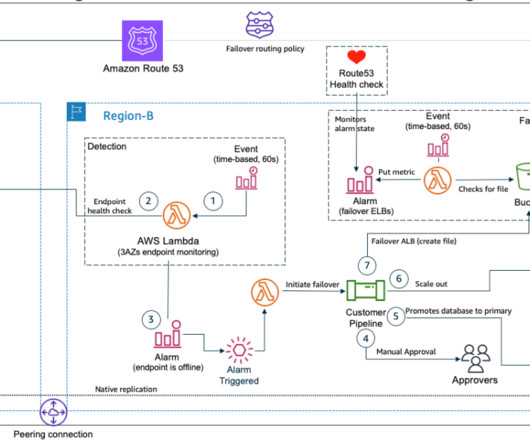
Using multiple Regions ensures resiliency in the most serious, widespread outages. Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. DR Strategies.
Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. . Cost-effective Disaster Recovery . Seeding and reseeding times can be drastically minimized.
There are two types of HA clustering configurations that are used to host an application: active-passive and active-active. The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests.
The IDC study found that 79% of those surveyed activated a disaster response, 83% experienced data corruption from an attack, and nearly 60% experienced unrecoverable data. The Zerto for Kubernetes failover test workflow can help check that box. Disaster Recovery & Data Protection All-In-One.
Instructions about how to use the plan end-to-end, from activation to de-activation phases. Since most businesses today are heavily IT reliant, DRP tends to focus on business data and information systems by addressing one or several points of failure including application downtime, network outages, hardware failure, data loss, etc.
Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. This dependence has brought risk.
Top Storage and Data Protection News for the Week of September 27, 2024 Cayosoft Secures Patent for Active Directory Recovery Solution Cayosoft Guardian Forest Recovery’s patented approach solves these issues by functioning as an AD resilience solution rather than a typical backup and recovery tool.
If you’re using infrastructure as a service (IaaS), constantly check and monitor your configurations, and be sure to employ the same monitoring of suspicious activity as you do on-prem. . PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failover event. This component determines which array will continue data services should a power outage occur. Active/active clustered array pairs. Multi-direction replication.
The manufacturing processes they support—like the aluminum casting required to produce powertrain and engine components—are energy-intensive and prone to outages. Two mainframes power critical sales, after-sales, and supply chain processes, which are backed up on Pure FlashBlade ® using virtual tape software and then written to Amazon S3.
Typically, backup systems are called into action for discrete outages. A proper DR plan does not necessarily require a hot failover site. If you don’t have a failover site, mission-critical apps and their resources can be stored as replicas, which can be quickly transferred to a secondary data center.
Any data that has been identified as valuable and essential to the organization should also be protected with proactive security measures such as Cyberstorage that can actively defend both primary and backup copies from theft.” However, backups fail to provide protection from data theft with no chance of recovery.
This means that instead of constantly worrying about IT problems, you and your employees can focus on core business activities. They can set up automated failovers that will automatically shift workloads from one server or data center to another in case the main one fails or crashes unexpectedly.
Cloud providers have experienced outages due to configuration errors , distributed denial of service attacks (DDOS), and even catastrophic fires. Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. This dependence has brought risk.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
Traditional Storage Array Approaches Storage arrays primarily take one of two approaches to address this challenge: active/active or scale-out. Active-Active: Advantages and Disadvantages Active/active allows both controllers to simultaneously serve IO to hosts. Each has its advantages and disadvantages.
Immutable centralized incident record : PagerDuty provides a time-stamped log of all activities and resolution steps relating to an incident. Alternatively, firms could manually disable a machine or application or create a PagerDuty test incident to trigger an outage and then practice their response procedures.
Application: AI-driven surveillance enhances facility security by detecting unusual activities, intruders, or potential security threats. Environmental Monitoring for Critical Infrastructure: How it Works: IoT sensors monitor environmental conditions such as temperature, humidity, and seismic activity around critical infrastructure.
This design needs to keep costs at a minimum, and it needs to allow for failure detection and manual failover of resources. The solution Amazon Route53 Application Recovery Controller (Route53 ARC) helps manage and orchestrate application failover and recovery across multiple AWS Regions or on-premises environments.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content