This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. The post also introduces a multi-site active/passive approach.
If you want true highavailability – meaning that your SQL Server database will be accessible 99.99 The PaaS offering — Amazon RDS – falls out of the running because its service level agreement (SLA) only guarantees an availability level of 99.95 Will you use SQL Server’s built-in Availability Groups (AG) functionality?
In my first blog post of this series , I introduced you to four strategies for disasterrecovery (DR). My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. DR strategies: Multi-site active/active. Implementing multi-site active/active.
For on-premises business continuity and disasterrecovery, ActiveCluster ™ enables zero RPO and zero RTO at metro distances. Want to provide business continuity between availability zones of either AWS or Azure? Need active-active synchronous replication between Azure and AWS? No problem.
Solutions Review’s listing of the best backup and disasterrecovery companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. These changes speak to the cloud’s continued rise, significantly impacting the backup and disasterrecovery market over recent years.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of highavailability (HA) and disasterrecovery (DR) is paramount. What Is HighAvailability? Here, we delve into HA and DR, the dynamic duo of application resilience.
Since the primary objective of a backup site is disasterrecovery (DR) management, this site is often referred to as a DR site. DisasterRecovery on AWS. DR strategy defines the recovery objectives for downtime and data loss. The workload has a recovery time objective (RTO) and a recovery point objective (RPO).
In a previous blog post , I introduced you to four strategies for disasterrecovery (DR) on AWS. These strategies enable you to prepare for and recover from a disaster. Every AWS Region consists of multiple Availability Zones (AZs). Backup within the AWS Region. There are several options for automated response.
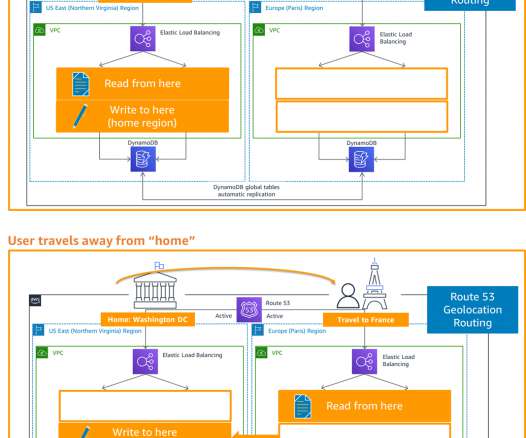
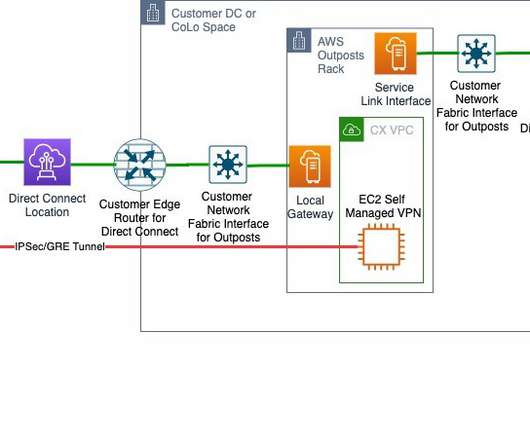
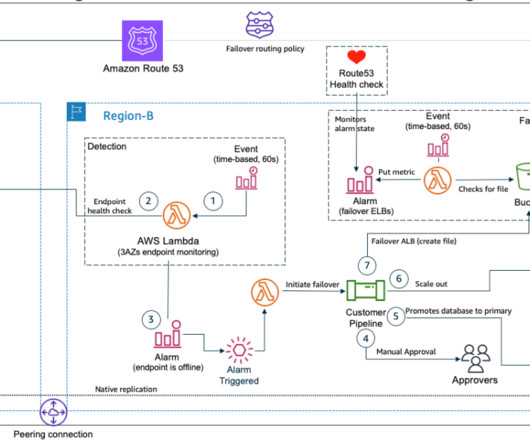
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disasterrecovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. This keeps RTO and RPO low.
In this feature, SIOS Technology Corp ‘s Dave Bermingham reveals three highavailability for SQL Server in AWS options to consider. If you want true highavailability – meaning that your SQL Server database will be accessible 99.99 Will you use SQL Server’s built-in Availability Groups (AG) functionality?
So, given its importance, you want to make sure you have a solid solution for ensuring it’s highly available or protected in the event of a disaster. Most SAP HANA customers today are using SAP HANA system replication (HSR) to ensure the highavailability and disasterrecovery systems remain in sync.
Pure Cloud Block Store offers built-in data protection that leverages multiple high-availability zones (AZs), to reduce physical fault domain exposure. Pure Cloud Block Store removes this limitation with an architecture that provides highavailability. Kunal Kapoor, Director Product Management, Pure Storage.
That’s why many customers replicate their mission-critical workloads in multiple places using a DisasterRecovery (DR) strategy suited for their needs. Depending on the RPO and RTO of the mission-critical workload, the requirement for disasterrecovery ranges from simple backup and restore, to multi-site, active-active, setup.
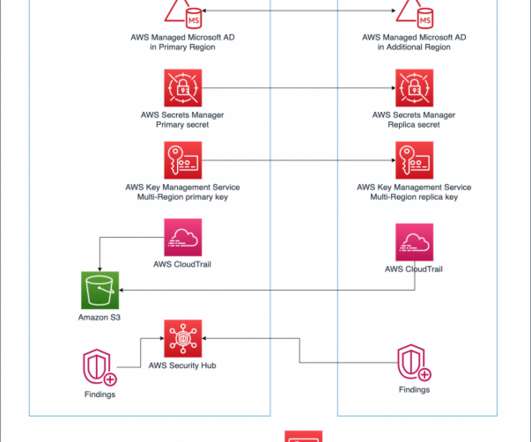
AWS Regions are built with multiple isolated and physically separate Availability Zones (AZs). This approach allows you to create highly available Well-Architected workloads that span AZs to achieve greater fault tolerance. AWS CloudTrail logs user activity and API usage. Considerations before getting started.
Here are comprehensive solutions you can utilize to achieve data redundancy and ensure effective disasterrecovery: Cloud storage solutions Cloud storage platforms such as Amazon Web Services, Microsoft Azure, or Google Cloud employ advanced data replication techniques and store data across multiple servers and locations.
The benefits of using Pure Cloud Block Store volumes for SQL Server database storage include, but are not limited to, greater storage efficiency and increased storage availability. . Cost-effective DisasterRecovery . This replication type can provide near-zero recovery point objectives. .
Humans conflate Availability with Contingency Many outages are caused or exacerbated because ‘fail-proof’ systems failed. High security, compartmentalized access, biometrics, the works. Uptime Institute Tier 4, everything down to the power into the racks was HighAvailability.
To do this, they implement automated monitoring and alerting systems and automated recovery processes. They continuously improve systems’ design and operation, and they work closely with development teams to ensure that systems are highly available, resilient, and prepared for planned and unplanned disruptions to applications.
Devastating Downtime and Disruptions— The cost of downtime and disruptions, planned and unplanned, is still wreaking havoc on businesses knowing that each minute down in this highly available world of products and services is not worth the price. Today, Beth is a Zerto customer and helps manage their disasterrecovery strategy. “We
Data protection is a broad field, encompassing backup and disasterrecovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disasterrecovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
Live migration: Hyper-V enables live migration of virtual machines between hosts without downtime, ensuring continuous availability and resource optimization. High-availability clusters: Configure failover clusters where VMs automatically migrate to a healthy server in case of hardware failure, minimizing service disruptions.
SvHCI can be deployed on a single server, or on two servers to enable highavailability and eliminate downtime. Security Guardian Shields Up allows customers to temporarily freeze all changes to Tier 0 objects, disrupting attacks against Active Directory that involve lateral movement and persistence.
It offers numerous high-availability solutions. MySQL Workloads DisasterRecovery MySQL databases are the heart of many businesses. This means, of course, that admins need a disaster-recovery plan in place in case a database disruption occurs. It can be virtualized. Single-command failover.
by Pure Storage Blog A key distinction in the realm of disasterrecovery is the one between failover and failback. Both play critical roles in business continuity and disasterrecovery efforts, so it’s important to understand what they are and why they’re different. Their effects, however, couldn’t be more different.
by Pure Storage Blog A key distinction in the realm of disasterrecovery is the one between failover and failback. Both play critical roles in business continuity and disasterrecovery efforts, so it’s important to understand what they are and why they’re different. Their effects, however, couldn’t be more different.
Executive builders should center their resilience strategies around availability, performance, and disasterrecovery (DR). Availability: Concerns to solve for highavailability (HA) and DR. Now let’s discuss how we can address these concerns in the AWS Cloud. Availability and disasterrecovery.
As part of Solutions Review’s ongoing coverage of the enterprise storage, data protection, and backup and disasterrecovery markets, lead editor Tim King offers this nearly 7,000-word resource. However, backups fail to provide protection from data theft with no chance of recovery.
introducing extreme highavailability for PostgreSQL—up to 99.999%+ availability via active-active technology, according to the vendor. EDB Launches Postgres Distributed 5.0 EnterpriseDB (EDB), the accelerator of Postgres in the enterprise, is launching EDB Postgres Distributed (PGD) 5.0, Read on for more.
These activities keep your systems up to date and fine-tuned, helping prevent unexpected failures and ensure smooth business operations. And in the event of a data loss incident, MSPs will leverage their disasterrecovery strategies to restore your systems and data efficiently.
Read on for more HYCU Wins Google Cloud Technology Partner of the Year for Backup & DisasterRecovery HYCU provides backup and recovery for the broadest number of IaaS, DBaaS, PaaS, and SaaS services for Google Cloud currently.
SIOS Debuts New DisasterRecovery Professional Services The new suite of offerings is designed to provide advanced guidance in the areas of Installation and Upgrade Services, Product Training, HighAvailability Validation Check Services, Standby Engineering Services, and Customized Professional Services. Read on for more.
This chain of activities results in an increasingly complex, geographically vast, and multi-tiered supply network. There will be edge M&A activity as the technology matures and presents a credible alternative to hyperscale clouds. On top of that, these suppliers themselves outsource their material to second-tier suppliers.
They’re also clustered in regions and geographies to provide highavailability and redundancy in case of failures. By having a cloud data center in different geographical locations, Microsoft offers its customers a resilient, scalable, and available platform globally. What Are Azure Availability Zones?
VMware’s ecosystem is comprehensive, offering a wide array of tools for efficient VM management, disasterrecovery, and enhanced security. Support and Community When it comes to support and community resources, both Hyper-V and VMware have large, active user bases and extensive support options.
In 2024, it will be crucial to optimize the transparency afforded by these regulations, and by dragging cybercriminals out into the open, authorities can more effectively curtail their illicit activity.” If the AI detects unusual activity, it can respond autonomously to increase their level of protection.
Every minute of activity translates to lost revenue, diminished productivity, and potentially irreparable damage to reputation. We’ve established that speed is key for effective cyber recovery. Among these, DR is often the most comprehensive solution because of its robust mechanisms for quick recovery for a wide range of disruptions.
Active-active stretched cluster vVol support with VMware and Pure Storage. The Portworx by Pure Storage Kubernetes data platform was created to solve the needs of customers that require multi-cloud mobility, highavailability, disasterrecovery and backup for their most critical production applications.
Data recovery should be a key focus around Data Privacy Week 2024, knowing that it’s still a major concern as only 13 percent of organizations say they can successfully recover during a disasterrecovery situation. In 2024, the overall mindfulness of cyber preparedness will take precedence.” Larry Whiteside, Jr.,
Data recovery should be a key focus around Data Privacy Week 2024, knowing that it’s still a major concern as only 13 percent of organizations say they can successfully recover during a disasterrecovery situation. In 2024, the overall mindfulness of cyber preparedness will take precedence.” Larry Whiteside, Jr.,
Data recovery should be a key focus around Data Privacy Week 2024, knowing that it’s still a major concern as only 13 percent of organizations say they can successfully recover during a disasterrecovery situation. In 2024, the overall mindfulness of cyber preparedness will take precedence.” Larry Whiteside, Jr.,
A good strategy for resilience will include operating with highavailability and planning for business continuity. It also accounts for the incidence of natural disasters, such as earthquakes or floods and technical failures, such as power failure or network connectivity.
A Pure Storage survey revealed that 90% of Singapore’s public agencies are actively seeking ways to mitigate AI’s impact on energy consumption. The high-performance all-flash storage scales non-disruptively, while delivering rapid data access and highavailability, to support the ministrys growing digital needs.
A Pure Storage survey revealed that 90% of Singapore’s public agencies are actively seeking ways to mitigate AI’s impact on energy consumption. The high-performance all-flash storage scales non-disruptively, while delivering rapid data access and highavailability, to support the ministrys growing digital needs.
vSphere highavailability (HA) and disasterrecovery (DR): VMware offers built-in highavailability and disasterrecovery features, ensuring that critical workloads can quickly recover from failures with minimal downtime. These can significantly increase the total cost of ownership (TCO).
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content